Nous avons vu le tracé linéaire de base dans la section précédente, mais Matplotlib propose beaucoup d’autres types de tracés tels que les diagrammes à barres, les histogrammes, les diagrammes de dispersion, les diagrammes circulaires, les diagrammes en boîte (Box et Whisker Plot), les cartes thermiques (ou de chaleur heatmap), l’affichage d’images, etc. Comprenons maintenant quand les utiliser et quelques cas d’utilisation.
Diagramme à barres #
Les diagrammes à barres représentent des données catégorielles à l’aide de barres rectangulaires, la longueur ou la hauteur de chaque barre représentant une valeur. Tu peux utiliser la commande plt.bar(x,y) pour générer des diagrammes à barres verticales et plt.barh(x,y) pour des diagrammes à barres horizontales.
Quelques cas d’utilisation :
- Comparer les performances de vente de différents produits.
- Représentation de la répartition de la population par pays.
Par exemple : diagramme à barres multiples dans un seul graphique
# Catégories de dépenses
categories = ['Logement', 'Transport', 'Alimentation', 'Divertissement', 'Services publics']
# Dépenses mensuelles pour Alice, Bob et Carole
alice_expenses = [1200, 300, 400, 200, 150]
bob_expenses = [1100, 320, 380, 180, 140]
carol_expenses = [1300, 280, 420, 220, 160]
# Créer un tableau pour les positions de l'axe x
x = np.arange(len(categories))
# Largeur des barres, nous en avons besoin car nous avons l'intention de tracer plusieurs barres.
bar_width = 0.2
# Créer des barres pour les dépenses d'Alice, soustraire la largeur des barres du tableau x,
# de telle sorte qu'elle soit placé à gauche.
plt.bar(x - bar_width, alice_expenses, width=bar_width, label='Alice', color='skyblue')
# Créer des barres pour les dépenses de Bob
plt.bar(x, bob_expenses, width=bar_width, label='Bob', color='lightcoral')
# Créer des barres pour les dépenses de Carole, ajouter la largeur des barres au tableau x,
# de telle sorte qu'elle soit placé à gauche.
plt.bar(x + bar_width, carol_expenses, width=bar_width, label='Martin', color='lightgreen')
# Ajouter des étiquettes, un titre et une légende
plt.xlabel('Catégories de dépenses')
plt.ylabel('Dépenses mensuelles (en €)')
plt.title('Comparaison des dépenses mensuelles')
# Pour afficher les noms des catégories sur les positions de l'axe des x.
plt.xticks(x, categories)
plt.legend()
# Afficher le graphe
plt.show()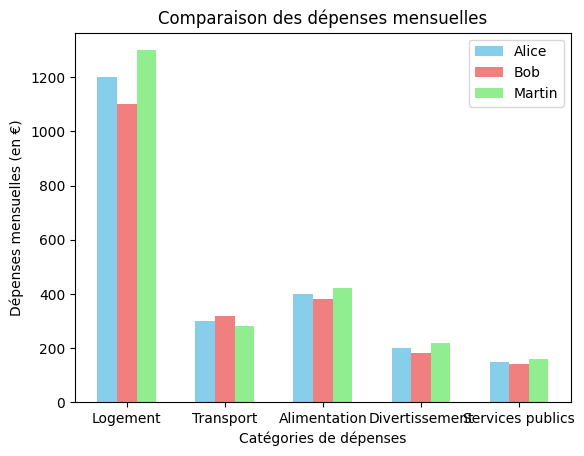
- Ainsi, pour obtenir ces barres, nous avons soustrait les étiquettes x de la largeur de la barre pour la première barre et ajouté l’étiquette à la largeur de la barre pour la dernière barre. Nous avons défini le paramètre de largeur comme étant égal à la largeur de la barre pour toutes les barres.
Histogrammes #
Les histogrammes sont utilisés pour visualiser la distribution de données continues ou numériques et ils nous aident à identifier des modèles dans les données. Dans un histogramme, les données sont regroupées en “bins” (des cases ou bacs en gros) et la hauteur de chaque barre représente la fréquence ou le nombre de points de données dans cette bin. Il prend les limites inférieures et supérieures des données et les divise en fonction du nombre de bins indiqué.
Tu peux utiliser la commande plt.hist(x) pour générer des histogrammes. Contrairement au diagramme en bâtons, tu n’as pas besoin de “y”, car il ne représente que la fréquence d’une donnée continue. Le nombre de bins par défaut est de 10, mais il peut être modifié. Tu peux également remplacer l’intervalle des bins par l’intervalle de ton choix. Tu peux également ajouter la couleur du bord des barres.
En plus du tracé de l’histogramme, dans le même graphique, si tu souhaites ajouter une ligne, par exemple la moyenne ou la médiane, tu peux le faire en calculant la valeur et en la passant à plt.axvline(calculated_mean,label=desired_label). Cette méthode peut être utilisée avec n’importe quel autre graphique.
Quelques cas d’utilisation :
- Analyse de la distribution des âges dans une population.
- Examen de la distribution des notes d’examen dans une classe.
# Exemple de données sur les notes d'examen
exam_scores = [68, 72, 75, 80, 82, 84, 86, 90, 92, 95, 98, 100]
# Gammes de bins personnalisés
bin_ranges = [60, 70, 80, 90, 100]
# Créer un histogramme avec des plages de bins personnalisées en l'assignant à des bins.
plt.hist(exam_scores, bins=bin_ranges, color='lightblue', edgecolor='black', alpha=0.7)
# Ajouter des étiquettes et un titre
plt.xlabel('Exam Scores')
plt.ylabel('Frequency')
plt.title('Exam Scores Histogram with Custom Bins')
# Calculer et ajouter une ligne médiane
median_score = np.median(exam_scores)
plt.axvline(median_score, color='red', linestyle='dashed', linewidth=2, label=f'Median Score: {median_score}')
# Ajouter une légende
plt.legend()
# Afficher le graphe
plt.show()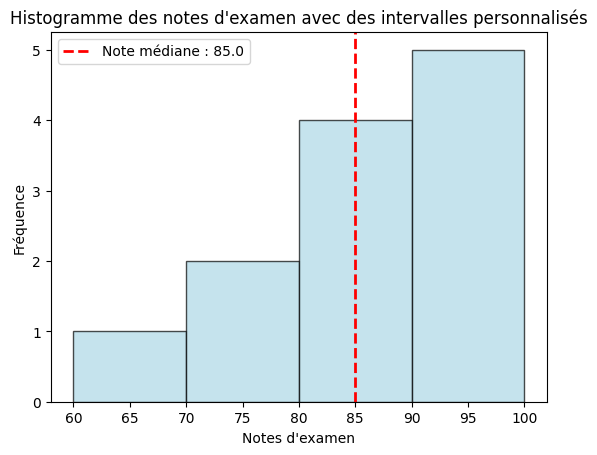
Diagrammes de dispersion #
Les diagrammes de dispersion représentent des points de données individuels sur un plan bidimensionnel. Ils sont utilisés pour explorer les relations ou les corrélations entre deux variables numériques. Dans ce cas, chaque axe représente une variable et les points représentent les données.
Tu peux utiliser plt.scatter(x,y) pour générer des diagrammes de dispersion. Pour modifier la taille des points, utilise les paramètres s, c pour la couleur et marker pour remplacer le point par un marqueur. Le paramètre alpha contrôle l’intensité de la couleur. Pour la taille, tu peux même envoyer une liste de tailles différentes pour chaque point.
Quelques cas d’utilisation :
- Étude de la relation entre les heures d’étude et les résultats aux examens.
- Analyse de la corrélation entre la température et les ventes de glaces.
# Prenons un échantillon de données pour les magasins
# Taille du magasin Représente la taille de chaque magasin en 100 m².
stores = ['Magasin A', 'Magasin B', 'Magasin C', 'Magasin D', 'Magasin E']
customers = [120, 90, 150, 80, 200]
revenue = [20000, 18000, 25000, 17000, 30000]
store_size = [10, 5, 15, 8, 20]
# Ici, nous mettons à l'échelle les tailles des magasins pour les tailles des points dans le diagramme de dispersion
point_sizes = [size * 100 for size in store_size]
# Pour créer un diagramme de dispersion avec différentes tailles de points,
# Ici, alpha contrôle l'intensité de la couleur.
plt.scatter(customers, revenue, s=point_sizes, c='skyblue', alpha=0.7, edgecolors='b')
# Ajouter des étiquettes, un titre et une légende
plt.xlabel('Nombre de clients')
plt.ylabel("Chiffre d'affaires (€)")
plt.title("Relation entre les clients, le chiffre d'affaires et la taille du magasin")
# Pour afficher le tracé
plt.show()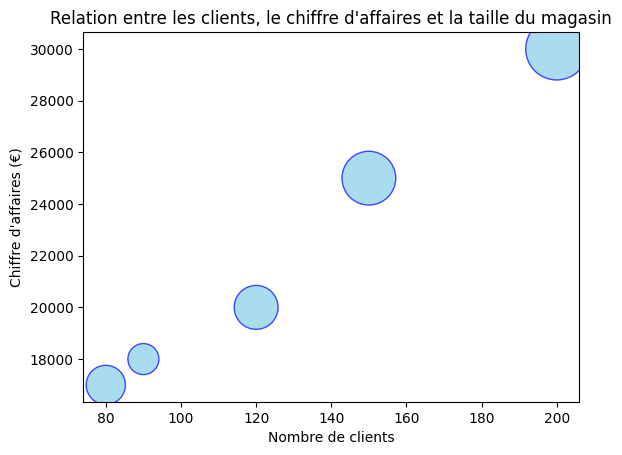
Diagrammes circulaires #
Les diagrammes circulaires représentent des parties d’un tout sous la forme de parts d’un gâteau circulaire. Ils conviennent pour montrer la composition d’une seule variable catégorielle en termes de pourcentages. Mais ils ne sont pas adaptés lorsqu’il y a plus de six catégories, car ils deviennent maladroits ; dans ce cas, il est préférable d’utiliser des barres horizontales.
Utilise la commande plt.pie(x,labels=tes_noms_de_catégorie, colors=liste_de_couleur_désirée), si tu as une liste de couleurs souhaitées, tu peux la fournir et tu peux également changer la couleur du bord du graphique circulaire avec le paramètre wedgeprops={'edgecolor':votre_couleur}.
Il est également possible de mettre en évidence des segments particuliers à l’aide du paramètre explode en passant un tuple dont chaque élément représente la quantité par laquelle il doit exploser. Le paramètre autopct permet de choisir le nombre de valeurs après la décimale à afficher dans le graphique.
Quelques cas d’utilisation :
- Affichage de la répartition d’un budget par catégories de dépenses.
- Afficher la part de marché de différentes marques de smartphones.
Par exemple : Explosion d’un segment particulier pour mieux raconter une histoire lors d’une présentation.
# Catégories de produits
categories = ['Électronique', 'Vêtements', 'Décoration intérieure', 'Livres', 'Jouets']
# Données sur les ventes pour chaque catégorie
sales = [3500, 2800, 2000, 1500, 1200]
# Éclater un segment spécifique (par exemple, 'Vêtements'),
# la deuxième valeur (0.1) est la quantité par laquelle le segment 'Vêtements'.
explode = (0, 0.1, 0, 0, 0)
# Créer un diagramme circulaire avec explode et shadow
plt.pie(sales, labels=categories, explode=explode, shadow=True, autopct='%1.1f%%')
plt.title('Ventes par catégorie de produits')
# Afficher le graphe
plt.show()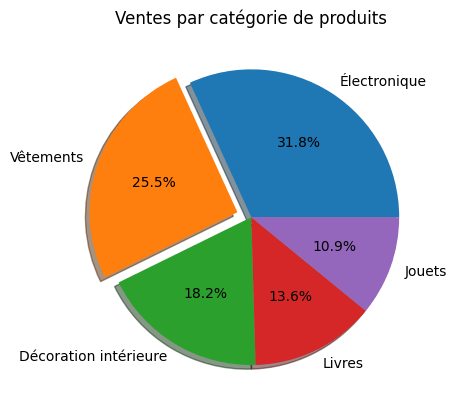
Diagramme en boîte (boîte à moustache) #
Les diagrammes en boîte sont ceux qui ont l’air compliqués, n’est-ce pas ? En termes simples, ils résument la distribution des données numériques en affichant les quartiles, les valeurs aberrantes et l’asymétrie potentielle. Ils donnent un aperçu de la dispersion des données, de la tendance centrale et de la variabilité. Les diagrammes en boîte sont particulièrement utiles pour identifier les valeurs aberrantes et comparer les distributions.
Tu peux utiliser plt.boxplot(data) pour tracer le diagramme en boîte. Tu peux personnaliser l’apparence de la boîte et des valeurs aberrantes à l’aide de boxprops et flierprops, utiliser vert=False pour rendre le box plot horizontal et patch_artist=True pour remplir la boîte de couleurs.
Quelques cas d’utilisation :
- Analyse de la distribution des salaires dans une entreprise.
- Évaluer la variabilité des prix des logements dans différents quartiers.
# Générer des données aléatoires avec des valeurs aberrantes
np.random.seed(42)
data = np.concatenate([np.random.normal(0, 1, 100), np.random.normal(6, 1, 10)])
# Créer un diagramme en boîte avec des valeurs aberrantes
plt.figure(figsize=(8, 6)) # Définir la taille de la figure
plt.boxplot(data, vert=False, patch_artist=True,
boxprops={'facecolor': 'lightblue'},
flierprops={'marker': 'o', 'markerfacecolor': 'red',
'markeredgecolor': 'red'})
# Ajouter des étiquettes et un titre
plt.xlabel('Valeurs')
plt.title('Diagramme en boîte avec valeurs aberrantes')
# Afficher le graphe
plt.grid(True) # Ajouter une grille pour une meilleure lisibilité
plt.show()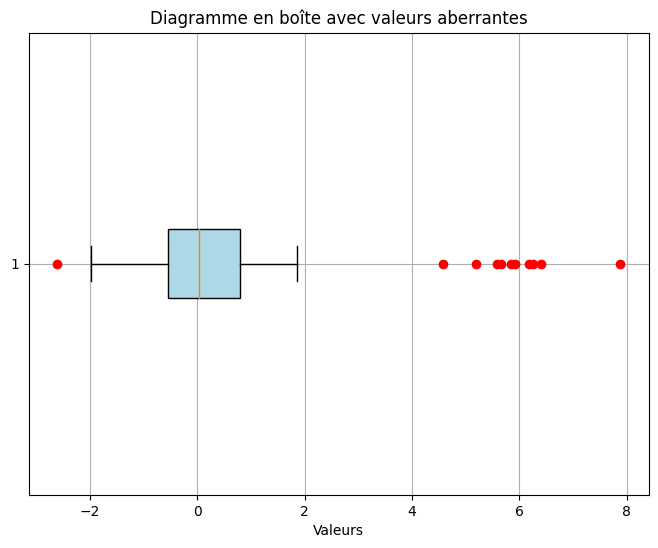
Heatmap et affichage des images #
plt.imshow() est une fonction de Matplotlib utilisée pour afficher des données d’images 2D, visualiser des tableaux 2D ou montrer des images dans différents formats.
- Utilisation de
imshowpour la carte thermique (heatmap) : La carte thermique est une visualisation de la matrice de corrélation, qui nous donne une idée de la corrélation entre chaque variable et l’autre variable. Ici, nous allons créer une carte thermique pour visualiser une matrice de corrélation, et nous utiliserons une carte de couleurs pour montrer visuellement cette relation. Passe la matrice de corrélation àimshowpour visualiser la carte thermique.
# Créer un échantillon de matrice de corrélation
correlation_matrix = np.array([[1.0, 0.8, 0.3, -0.2],
[0.8, 1.0, 0.5, 0.1],
[0.3, 0.5, 1.0, -0.4],
[-0.2, 0.1, -0.4, 1.0]])
# Créer une carte thermique pour la matrice de corrélation
plt.imshow(correlation_matrix, cmap='coolwarm', vmin=-1, vmax=1, aspect='auto', origin='upper')
# Ajouter une barre de couleur avec les commandes suivantes
cbar = plt.colorbar()
cbar.set_label('Correlation', rotation=270, labelpad=20)
# Ajouter des étiquettes et un titre
plt.title('Matrice de corrélation - Carte thermique')
plt.xticks(range(len(correlation_matrix)), ['Var1', 'Var2', 'Var3', 'Var4'])
plt.yticks(range(len(correlation_matrix)), ['Var1', 'Var2', 'Var3', 'Var4'])
plt.show()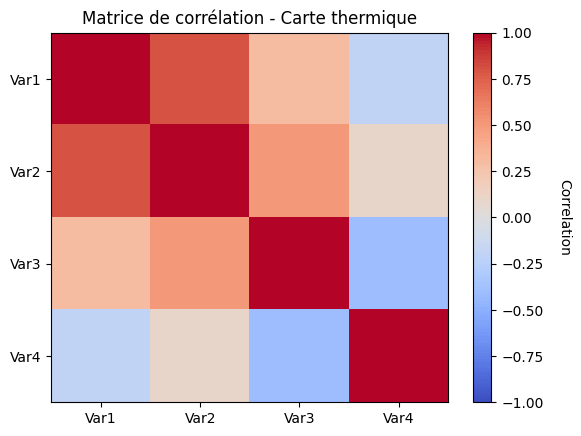
- Affichage d’images avec imshow : La méthode
imreadde Matplotlib, issue du modulematplotlib.image, est souvent utilisée pour lire et charger des images dans différents formats, y compris JPEG, PNG, BMP, TIFF et autres, qui peuvent ensuite être affichées à l’aide deimshow. Si tu as déjà des données d’image dans un tableau, elles peuvent être affichées directement avecimshow.
import matplotlib.image as mpimg
# Charger et afficher une image
img = mpimg.imread('sample_image.jpg')
# Afficher l'image
plt.imshow(img)
# Désactiver les étiquettes d'axe et les ticks
plt.axis('off')
# Ajouter un titre
plt.title("Exemple d'image")
# Montrer le graphique
plt.show() Graphique en pile #
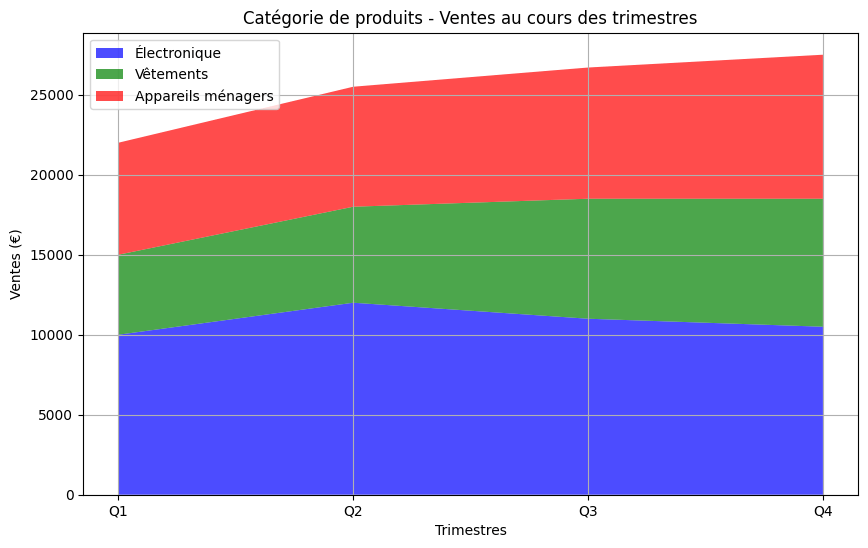
Imagine que tu souhaites visualiser la contribution de trois catégories de produits (électronique, habillement et électroménager) aux ventes totales sur quatre trimestres (Q1 à Q4). Tu peux alors représenter les ventes de chaque catégorie sous forme de couches dans le graphique, et le graphique nous aide à comprendre leurs contributions et leurs tendances au fil du temps. C’est exactement ce que fait le graphique en pile.
Un graphique en pile, également connu sous le nom de graphique en aires empilées, est un type de visualisation de données qui affiche plusieurs ensembles de données sous forme de couches empilées les unes sur les autres, chaque couche représentant une catégorie ou un composant différent des données. Les graphiques en pile sont particulièrement utiles pour visualiser la manière dont les composants individuels contribuent à un ensemble sur une période de temps continue ou dans un domaine catégorique. Utilise plt.stackplot(x,y1,y2), autant de piles que tu le souhaites !
# Exemple de données pour le graphique en pile
quarters = ['Q1', 'Q2', 'Q3', 'Q4']
electronics = [10000, 12000, 11000, 10500]
clothing = [5000, 6000, 7500, 8000]
home_appliances = [7000, 7500, 8200, 9000]
# Créer un graphique en pile
plt.figure(figsize=(10, 6)) # Définir la taille de la figure
plt.stackplot(quarters, electronics, clothing, home_appliances, labels=['Électronique', 'Vêtements', 'Appareils ménagers'],
colors=['blue', 'green', 'red'], alpha=0.7)
# Ajouter des étiquettes, une légende et un titre
plt.xlabel('Trimestres')
plt.ylabel('Ventes (€)')
plt.title('Catégorie de produits - Ventes au cours des trimestres')
plt.legend(loc='upper left')
# Afficher le graphe
plt.grid(True)
plt.show()