
Les diagrammes univariés sont utilisés pour visualiser et analyser une seule variable à la fois. Ils permettent de comprendre la distribution et la tendance centrale, d’identifier les valeurs aberrantes et de vérifier l’existence de schémas ou de tendances au sein d’une seule variable.
KDE Plot #
Un diagramme KDE (Kernel Density Estimation) est un type de visualisation de données utilisé pour estimer la fonction de densité de probabilité d’une variable continue. Ainsi, notre variable continue est représentée sur l’axe des x et l’axe des y représente la densité de probabilité estimée. La somme de l’aire sous la courbe est égale à 1, ce qui indique que la distribution des données est normalisée.
Utilise sns.kdeplot(data=dataframe[column]) pour créer un diagramme KDE pour une variable continue. Tu peux personnaliser l’apparence du tracé KDE en ajustant des paramètres tels que la taille des bandes, le type de noyau, la couleur, etc.
# KDE Plot
plt.figure(figsize=(8, 5))
sns.kdeplot(data=tips["total_bill"], fill=True)
plt.title("Estimation de la densité du noyau de la facture totale")
plt.xlabel("Facture totale (en $)")
plt.ylabel("Densité")
plt.show()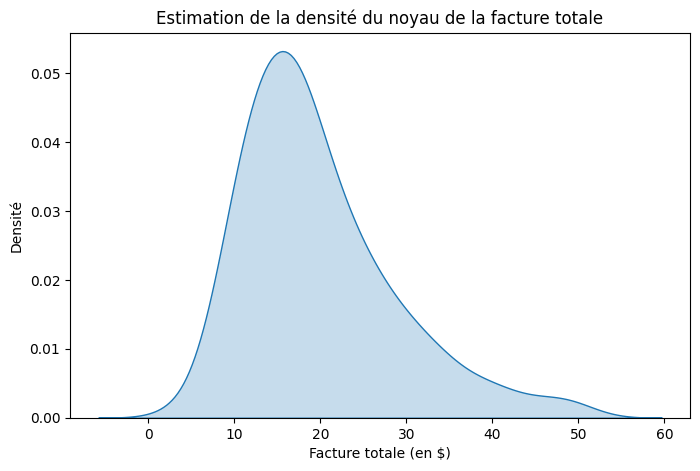
- Les graphes KDE donnent donc un aperçu de la forme, des pics, des modes et de la dispersion des données. Ils sont précieux pour estimer la densité de probabilité des points de données, ce qui peut s’avérer utile dans les analyses statistiques et les tests d’hypothèses.
Rug Plot #
Un Rug Plot est constitué de lignes verticales (ou “tics”) positionnées le long d’un seul axe (généralement l’axe des x). Chaque tic représente l’emplacement d’un point de données individuel, et la proximité des tics représente la densité des points de données ; en général, les zones plus denses ont plus de tiques serrées les unes contre les autres.
Utilise sns.rugplot(data=dataframe[column]) pour créer un rug plot. Tu peux personnaliser l’apparence des tracés en ajustant des paramètres tels que la hauteur, la couleur et l’orientation des tics.
# Rug Plot
plt.figure(figsize=(8, 5))
sns.rugplot(x=tips['total_bill'], height=0.5)
plt.title("Rug Plot de la facture totale")
plt.xlabel("facture totale (en $)")
plt.ylabel("Densité")
plt.show()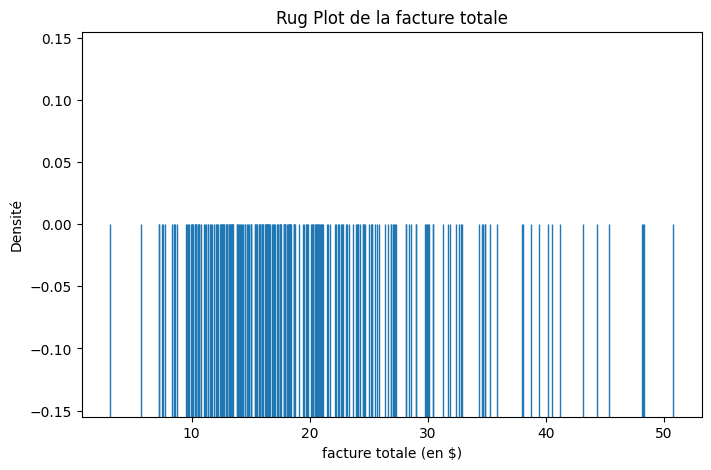
- D’après KDE, nous avons compris que le pic du montant de la facture se situe quelque part entre 10 et 20, mais le diagramme de Rug nous montre que la densité est plus importante entre 15 et 20.
- Ce diagramme est donc particulièrement utile lorsque tu souhaites connaître la position exacte de certains points de données. Les diagrammes Rug sont souvent combinés avec des histogrammes, des diagrammes KDE ou des diagrammes en boîte pour fournir un contexte et des détails supplémentaires. Ils peuvent aider à mettre en évidence les valeurs aberrantes ou les zones à forte densité de données.
Dist Plot #
Un Dist Plot, abréviation de Distribution Plot, ressemble typiquement à un histogramme, mais il comprend en outre une courbe lissée, qui est un diagramme KDE. Il divise la plage de la variable numérique en bins (des cases) ou intervalles et affiche la fréquence ou la densité des points de données dans chaque bin.
# Diagramme de distribution pour la visualisation univariée
plt.figure(figsize=(8, 5))
sns.displot(data=tips['total_bill'])
plt.title("Répartition totale de la facture")
plt.xlabel("Facture totale (en $)")
plt.show()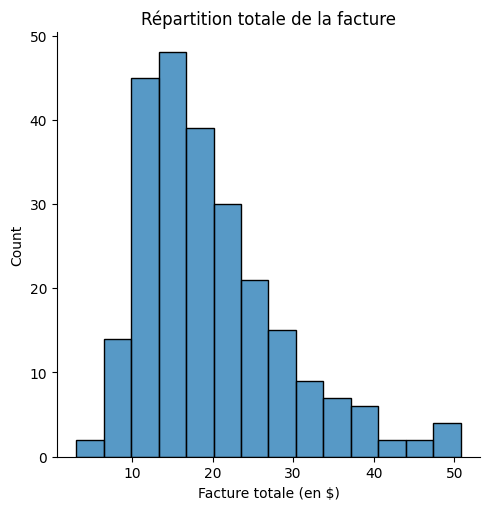
- En option, il est possible d’ajouter un Rug Plot le long de l’axe x, montrant les points de données individuels sous forme de petites lignes verticales. Cela permet d’avoir un aperçu de la densité et de la distribution des points de données individuels.
- Par défaut, le displot retourne un histogramme mais on peut lui demander un diagramme kde également.
Box Plot & Violin Plot #
Nous en avons parlé dans la section consacrée aux diagrammes catégoriels, tout est identique, mais tu ne passes qu’une seule variable lorsque tu souhaites effectuer une analyse univariée.
# Diagramme en boîte pour la visualisation univariée
plt.figure(figsize=(8, 5))
sns.boxplot(x=tips['total_bill'])
plt.title("Répartition de la facture totale")
plt.xlabel("facture totale (en $)")
plt.show()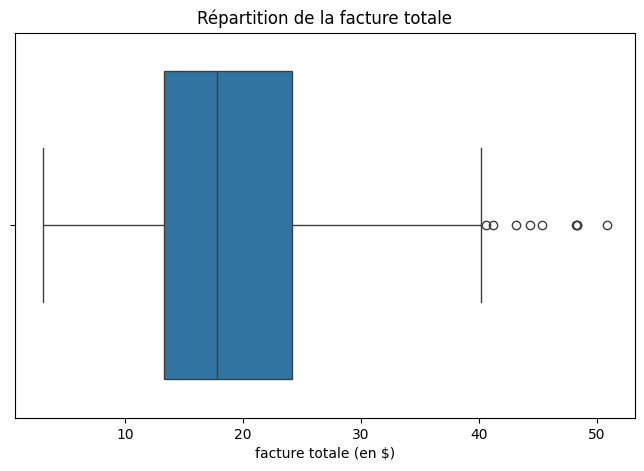
Strip Plot #
Un Strip Plot est un peu similaire à un diagramme en essaim (swarm plot) et affiche des points de données individuels le long d’un seul axe. Cependant, les points de données se chevauchent dans le Strip Plot, de sorte que nous pouvons dire que les diagrammes en essaim sont particulièrement utiles avec des ensembles de données plus petits et lorsque tu souhaites éviter les chevauchements.
Utilise sns.stripplot(data=dataframe[column]), et tu peux également l’utiliser pour les données bivariées. Jitter (ajout d’une petite quantité de bruit aléatoire) peut être appliquée aux points de données afin de réduire le chevauchement et d’améliorer la visibilité.
# Strip Plot pour la visualisation univariée
plt.figure(figsize=(8, 5))
sns.stripplot(x=tips['total_bill'], jitter=True)
plt.title("Répartition de la facture totale")
plt.xlabel("Facture totale (en $)")
plt.show()
Conclusion #
Jusqu’à maintenant, dans ce guide complet, nous avons abordé différents graphiques catégoriels et univariants tels que le diagramme de comptage, le diagramme en essaim, le diagramme en points, le diagramme catégoriel, le diagramme KDE, le diagramme Rug, le diagramme en boîte, le diagramme de distribution, le diagramme en violon, le diagramme en bandes, etc.
Continue à explorer et à jouer avec, seaborn est un outil polyvalent et tu peux faire beaucoup plus avec. Ne t’inquiète pas, dans les 3 prochains tutos nous explorerons les tracés bivariant, multivariant et matriciel afin de libérer tout le potentiel de seaborn.



