Ce sont mes préférés, ces diagrammes nous donnent beaucoup de flexibilité pour explorer les relations et les modèles entre trois variables ou plus simultanément. En d’autres termes, les diagrammes multivariés étendent l’analyse à plus de deux variables, ce qui sera souvent nécessaire dans l’analyse des données.
Utilisation de paramètres pour ajouter des dimensions #
- Utilisation du paramètre Hue : L’utilisation du paramètre
huepermet d’ajouter de la couleur au graphique en fonction de la variable catégorielle fournie, en spécifiant une couleur unique pour chacune des catégories. Ce paramètre peut être utilisé pour presque tous les tracés tels que.scatterplot(),.boxplot(), .violinplot(),.lineplot(), etc.
Prenons quelques exemples.
# Violin Plot avec une teinte Hue
plt.figure(figsize=(10, 6))
sns.violinplot(
x="day", # axe x : Jours de la semaine (catégoriel)
y="total_bill", # axe y : Montant total de la facture (numérique)
data=tips,
hue="sex", # Couleur par genre (catégoriel)
palette="Set1", # Palette de couleurs
split=True # Diviser les violons par catégories de teintes
)
plt.title("Diagramme du violon pour la facture totale par jour et par genre")
plt.xlabel("Jour de la semaine")
plt.ylabel("Facture totale (en $)")
plt.legend(title="Genre")
plt.show()
- Nous utilisons la colonne
sexpour colorer les violons en fonction de leur genre, ce qui ajoute une dimension au diagramme. Chaque genre est représenté par une couleur différente. - Utilisation des paramètres hue et size :
sizeest un autre paramètre qui peut être utilisé pour ajouter une autre dimension numérique à la variable.
# Diagramme de dispersion avec teinte (hue) et taille (size)
plt.figure(figsize=(10, 8))
sns.scatterplot(
x="total_bill",
y="tip",
data=tips,
hue="day", # Couleur par jour (catégoriel)
size="size", # Varier la taille du marqueur par colonne de taille (numérique)
sizes=(20, 200), # Définir la taille des marqueurs
palette="Set1" # Palette de couleurs
)
plt.title("Diagramme de dispersion avec hue et size pour le dataset Tips")
plt.xlabel("Facture totale (en $)")
plt.ylabel("Pourboire (en $)")
plt.legend(title="Jours et tailles")
plt.show()
- Chaque jour est représenté par une couleur différente, le paramètre
hueajoutant une troisième dimension, et la taille du marqueur basée sur la colonnesizedans l’ensemble de données pour ajouter une quatrième dimension.
Diagramme relationnel #
Un diagramme relationnel te permet de visualiser la relation entre deux variables numériques, ainsi que des dimensions catégorielles ou numériques supplémentaires.
Utilise sns.relplot(x,y,data,hue,size,style). Tu peux utiliser le paramètre hue pour colorer les points de données en fonction d’une variable catégorielle, le paramètre size pour faire varier la taille des marqueurs en fonction d’une variable numérique et le paramètre style pour différencier les marqueurs ou les lignes en fonction d’une variable catégorielle. Le paramètre kind te permet de spécifier le type de graphe relationnel que tu souhaites créer.
# Créer un nuage de points à l'aide d'un diagramme relationnel (relplot)
sns.relplot(x="total_bill", y="tip", data=tips, hue="time", style="sex", size="size", palette="Set1", height=6)
plt.title("Diagramme de dispersion relationnel pour le dataset Tips")
plt.xlabel("facture totale (en $)")
plt.ylabel("Pourboire (en $)")
plt.savefig('relplot_avec_mv.png')
plt.show()
- La colonne
timeest utilisée pour colorer les points de données avec le paramètrehue, la colonnesizepour faire varier la taille avec le paramètresize, et la colonnesexpour le paramètremarker. - FacetGrid en utilisant les paramètres col et row de relplot : Tu peux également créer un diagramme relationnel (relplot) en utilisant les paramètres
coletrowpour créer une grille à facettes, ce qui te permet de visualiser les relations au sein de différents sous-ensembles de données. Attribue les colonnes de catégorie àcolet àrow.
# Créer une grille à facettes à l'aide d'un graphe relationnel (relplot)
g = sns.relplot(
x="total_bill",
y="tip",
data=tips,
hue="time",
col="day", # Séparer les graphes par jour (colonnes)
row="sex", # Séparer les graphes par genre (lignes)
palette="Set1",
height=3, # Hauteur de chaque subplot
aspect=1.2 # Rapport d'aspect de chaque subplot
)
# Définir des titres et des étiquettes pour les facettes
g.set_titles(col_template="{col_name} Day", row_template="{row_name} Gender")
g.set_axis_labels("Facture totale (een $)", "Pourboire (en $)")
plt.suptitle("Diagrammes de dispersion relationnels par jour et par genre")
plt.subplots_adjust(top=0.9) # Régler la position du titre
plt.show()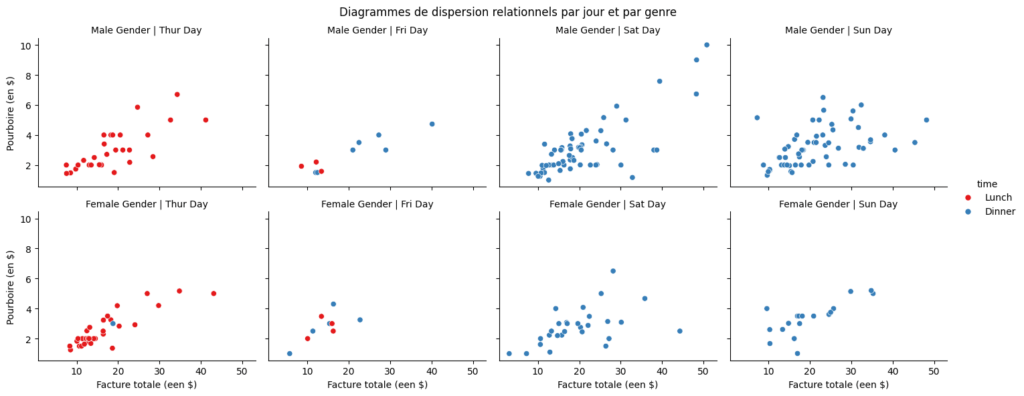
Facet Grid #
Une grille à facettes (Facet Grid) est une fonction de Seaborn qui te permet de créer une grille de sous-graphes (subplots), chacun représentant un sous-ensemble différent de tes données. De cette manière, les grilles à facettes sont utilisées pour comparer des modèles ou des relations avec plusieurs variables dans différentes catégories.
Utilise sns.FacetGrid(data,col,row) pour créer une grille à facettes, qui renvoie l’objet grid. Après avoir créé l’objet grid, tu dois l’associer à un diagramme de ton choix.
# Créer une grille à facettes d'histogrammes pour différents jours
g = sns.FacetGrid(tips, col="day", height=4, aspect=1.2)
g.map(sns.histplot, "total_bill", kde=True)
g.set_axis_labels("Facture totale (en $)", "Fréquence")
g.set_titles(col_template="{col_name} Day")
plt.savefig('facet_grid_hist_plot.png')
plt.show()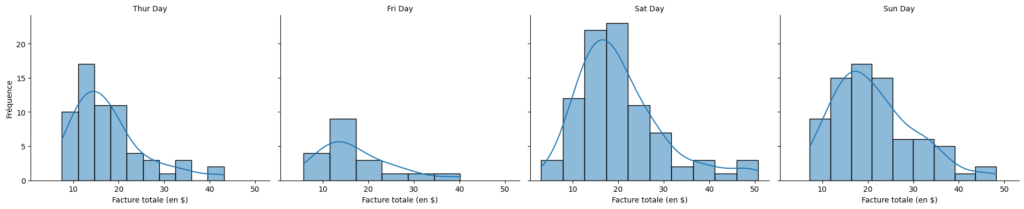
- De même, tu peux mapper n’importe quel autre graphe pour créer différents types de FacetGrids.
Pair Plot #
Un diagramme de paires (Pair Plot) fournit une grille de diagrammes de dispersion et d’histogrammes, où chaque diagramme montre la relation entre deux variables, ce qui explique pourquoi il est également appelé diagramme de paires ou matrice de diagrammes de dispersion.
Les cellules diagonales affichent généralement des histogrammes ou des diagrammes de densité de noyau pour les variables individuelles, montrant leurs distributions. Les cellules hors diagonale de la grille affichent souvent des diagrammes de dispersion, montrant comment deux variables sont liées. Les diagrammes de paires sont particulièrement utiles pour comprendre les modèles, les corrélations et les distributions à travers plusieurs dimensions de vos données.
Utilise sns.pairplot(data) pour créer un diagramme en paires. Tu peux personnaliser l’apparence des diagrammes par paires, notamment en modifiant le type de diagramme (nuage de points, KDE, etc.), les couleurs, les marqueurs, etc. Si tu souhaites modifier les tracés diagonaux, tu peux le faire en utilisant le paramètre diag_kind.
# Charger le dataset "iris"
iris = sns.load_dataset("iris")
# Pair Plot
sns.set(style="ticks")
sns.pairplot(iris, hue="species", markers=["o", "s", "D"])
plt.show()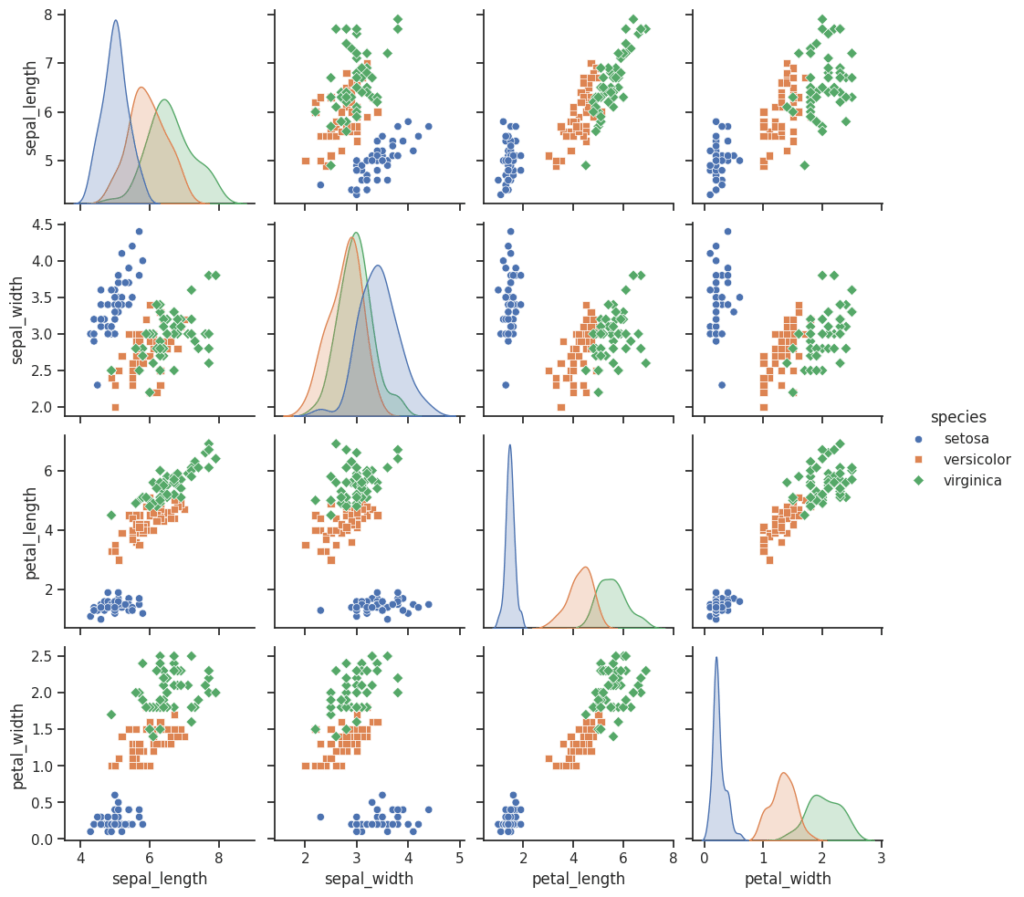
Pair Grid #
L’utilisation d’une grille de paires permet de personnaliser individuellement les tracés inférieur, supérieur et diagonal.
# Charger lee dataset "iris"
iris = sns.load_dataset("iris")
# Créer une grille à facettes de diagrammes de dispersion par paire
g = sns.PairGrid(iris, hue="species")
g.map_upper(sns.scatterplot)
g.map_diag(sns.histplot, kde_kws={"color": "k"})
g.map_lower(sns.kdeplot)
g.add_legend()
plt.show()