
Les diagrammes catégoriels dans la visualisation de données sont utilisés pour visualiser des données catégorielles, qui consistent en des catégories ou des groupes discrets et distincts.
Count Plot #
Le Count Plot (diagramme de comptage) affiche le nombre d’observations dans chaque catégorie. Il convient à la visualisation de la fréquence ou de la distribution des données catégorielles.
Utilise sns.countplot(x,data=dataframe) pour créer un diagramme de comptage. Si tu vois la commande, tu comprendras pourquoi j’ai dit que Seaborn aimait Pandas ! En effet, contrairement à Matplotlib, tu n’as pas besoin de passer la série à la commande plot (dataframe[column]), il y a un paramètre appelé data pour lequel tu dois assigner ton dataframe, puis pour les paramètres x et y tu peux simplement assigner le nom de ta colonne.
Avant de voir le Count Plot, importons un jeu de données disponible dans seaborn.
import seaborn as sns
import matplotlib.pyplot as plt
# Charger l'ensemble de données "tips"
tips = sns.load_dataset("tips")
tips.head()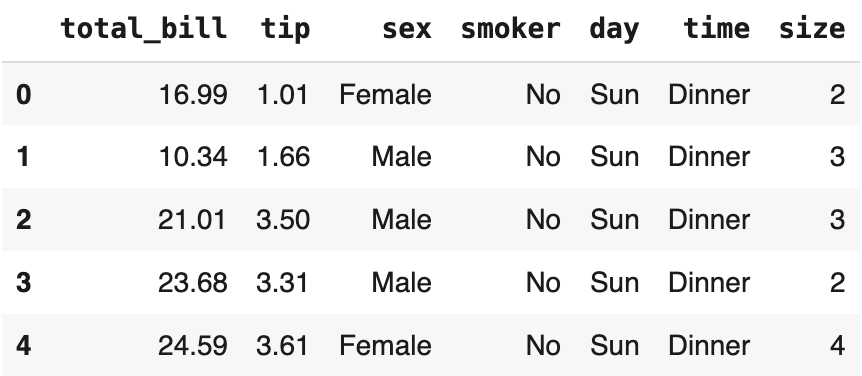
L’ensemble de données Tips concerne les pourboires donnés par les clients d’un restaurant.
Voyons un diagramme de comptage (Count Plot) pour la catégorie jour (day).
# Count Plot
plt.figure(figsize=(8, 5))
sns.countplot(x="day", data=tips, palette="Set3", hue="day", legend=False)
plt.title("Nombre de pourboires par jour de la semaine")
plt.show()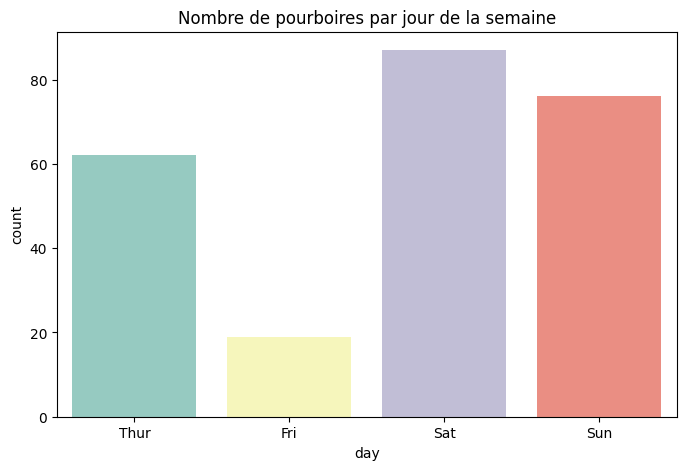
Quelques autres cas d’utilisation :
Analyse de la distribution des évaluations des clients (5 étoiles, 4 étoiles, 3 étoiles) pour un produit ou visualisation de la distribution des types de voitures (berline, SUV, camion) dans un ensemble de données de concessionnaires.
Swarm Plot #
Le diagramme en essaim (Swarm Plot) comporte généralement une variable catégorielle sur l’axe des x et une variable numérique sur l’axe des y, et il affiche des points de données individuels pour chaque catégorie. Comme tu peux le deviner, cela nous permet de visualiser la distribution et la densité des points de données au sein des catégories.
L’une des principales caractéristiques d’un diagramme en essaim c’est qu’il minimise le chevauchement entre les points de données. Cela signifie que chaque point de données est représenté de manière à ne pas se superposer à d’autres points de la même catégorie. Il est ainsi plus facile de voir la densité des données. Mais il est difficile de visualiser des données de grande taille, c’est pourquoi il est efficace avec des ensembles de données relativement petits.
Utilise sns.swarmplot(x,y,data) pour créer le diagramme en essaim et utilise la palette pour modifier les couleurs.
# Swarm Plot
plt.figure(figsize=(8, 5))
sns.swarmplot(x="day", y="total_bill", data=tips, palette="viridis", hue="day", legend=False)
plt.title("Répartition de la facture totale par jour de la semaine")
plt.xlabel("Jour de la semaine")
plt.ylabel("Facture totale (en $)")
plt.show()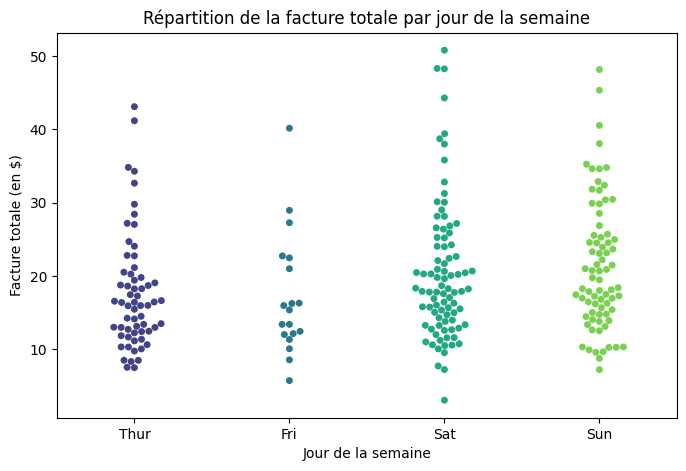
- Comme tu peux le constater, ils peuvent aider à identifier les valeurs aberrantes ou les points de données inhabituels au sein d’une catégorie. Nous pouvons donc affirmer avec certitude qu’un diagramme en essaim est utile pour comprendre la densité des points de données, car il fournit une représentation claire des endroits où les points de données sont concentrés et de ceux où ils sont clairsemés.
Quelques autres cas d’utilisation :
Tu peux utiliser un diagramme en essaim pour visualiser la répartition des notes d’examen entre les différentes classes ou la répartition des heures d’arrivée des clients entre les différents jours de la semaine.
Point Plot #
Le Point Plot comporte généralement une variable catégorielle sur l’axe des x et une variable numérique sur l’axe des y. Il peut fournir des informations sur la distribution et la tendance centrale des données au sein de chaque catégorie, comme une ligne ou un point.
# Point Plot
plt.figure(figsize=(8, 5))
sns.pointplot(x="day", y="total_bill", data=tips, errorbar="sd", palette="pastel", hue="day", legend=False)
plt.title("Facture totale moyenne par jour de la semaine")
plt.xlabel("Jour de la semaine")
plt.ylabel("Facture totale moyenne (en $)")
plt.show()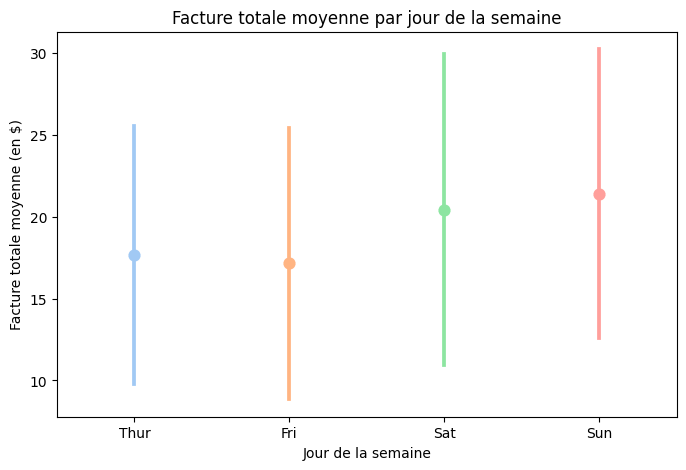
- Cette ligne ou ce point représente la valeur moyenne ou médiane de la variable numérique pour chaque catégorie. Tu peux ainsi voir rapidement s’il existe des différences entre les valeurs moyennes ou médianes des différentes catégories.
- Les mêmes cas d’utilisation s’appliquent ici, mais nous observerons la tendance centrale grâce à ce graphique. Cela nous donne une idée des scores moyens, faibles et élevés dans chaque classe.
Categorical Box Plot #
Un diagramme en boîte catégoriel (Categorical Box Plot), souvent appelé simplement diagramme en boîte ou boîte à moustaches, est un type de diagramme catégoriel utilisé pour visualiser la distribution d’une variable numérique au sein de différentes catégories ou groupes. Il affiche les quartiles (médiane, quartiles supérieurs et inférieurs), les valeurs aberrantes potentielles et la dispersion générale des données.
Utilise sns.boxplot(x,y,data) pour créer un diagramme en boîte catégoriel, mais ce diagramme n’est pas nécessairement destiné aux catégories, tu peux même passer une colonne numérique à l’axe des x.
# Categorical Box Plot
plt.figure(figsize=(8, 5))
sns.boxplot(x="time", y="total_bill", data=tips, palette="coolwarm", hue="time", legend=False)
plt.title("Répartition de la facture totale par heure de repas")
plt.xlabel("L'heure du repas")
plt.ylabel("Facture totale (en $)")
plt.show()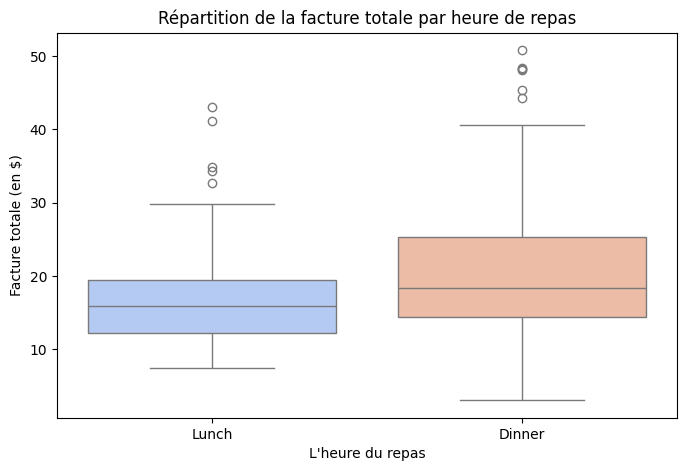
- Le diagramme consiste en une “boîte” rectangulaire qui couvre l’intervalle interquartile (IIQ) des données, avec une ligne à l’intérieur de la boîte représentant la médiane (50e percentile) des données. Des “moustaches” s’étendent (souvent 1,5 fois l’IIQ) à partir de la boîte jusqu’aux valeurs minimales et maximales d’un intervalle défini. Les points situés en dehors des moustaches sont potentiellement considérés comme des valeurs aberrantes.
- Tu peux utiliser ce diagramme lorsque tu souhaites obtenir des statistiques de base pour une variable catégorielle par rapport à une variable numérique. En fait, tu peux également l’utiliser pour deux variables numériques, par exemple, ‘size’ et ‘total_bills’ dans les ensembles de données de cette astuce, essaye-le.
Categorical Violin Plot #
La variable catégorielle détermine les groupes ou les catégories, et une variable numérique est utilisée pour créer les Violin Plots au sein de chaque catégorie. La largeur du graphique à un point spécifique indique la densité des points de données à cette valeur, et la partie centrale d’un Violin Plot ressemble à un violon, d’où le nom de Violin Plot.
À l’intérieur du violon, il y a souvent une représentation en boîte qui inclut la médiane, les quartiles et les valeurs aberrantes potentielles. Il fournit donc un résumé de la tendance centrale et de la dispersion des données afin d’offrir une vue d’ensemble de la distribution d’une variable numérique au sein de chaque catégorie.
Utilise sns.violinplot(x,y,data) pour créer un diagramme de violon.
# Categorical Violin Plot
plt.figure(figsize=(8, 5))
sns.violinplot(x="day", y="total_bill", data=tips, palette="Set2", hue="day", legend=False)
plt.title("Répartition de la facture totale par jour de la semaine")
plt.xlabel("Jour de la semaine")
plt.ylabel("Facture totale (en $)")
plt.show()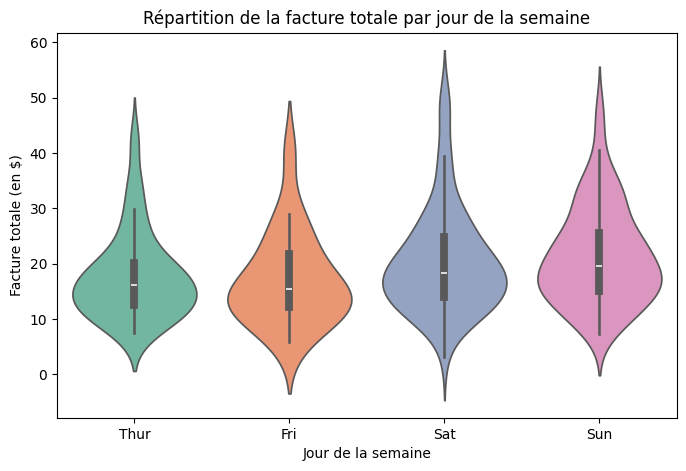
- Comme nous avons déjà observé la densité à partir du diagramme en essaim, nous pouvons constater qu’il combine les caractéristiques d’un diagramme en boîte et d’un diagramme de densité.
- Par conséquent, nous pouvons dire que les diagrammes catégoriels de violon sont efficaces pour comparer la distribution des données numériques dans différentes catégories. Ils te permettent de voir non seulement la tendance centrale et la dispersion, mais aussi la forme et l’asymétrie de la distribution.
Cat Plot #
Un Cat Plot, abréviation de “Categorical Plot”, est une fonction de traçage très puissante dans Seaborn. Elle te permet de réaliser tous les tracés catégoriels que nous avons vus ci-dessus avec un seul paramètre appelé kind dans la commande sns.catplot(x,y). Tu peux utiliser kind=bar, swarm, box, violin, count, point, etc. Les Cat Plots sont très utiles pour visualiser les relations entre les variables catégorielles et les variables numériques. Il s’agit d’un véritable couteau suisse pour les diagrammes catégoriels.



