
Il s’agit d’une approche dans laquelle un agent apprend à prendre des décisions en interagissant avec un environnement. L’agent entreprend des actions, reçoit un retour d’information sous forme de récompenses ou de punitions, et ajuste son comportement pour maximiser les récompenses à long terme. Elle est souvent utilisée en robotique, dans les jeux et les systèmes autonomes, tout comme la méthode d’essai et d’erreur.
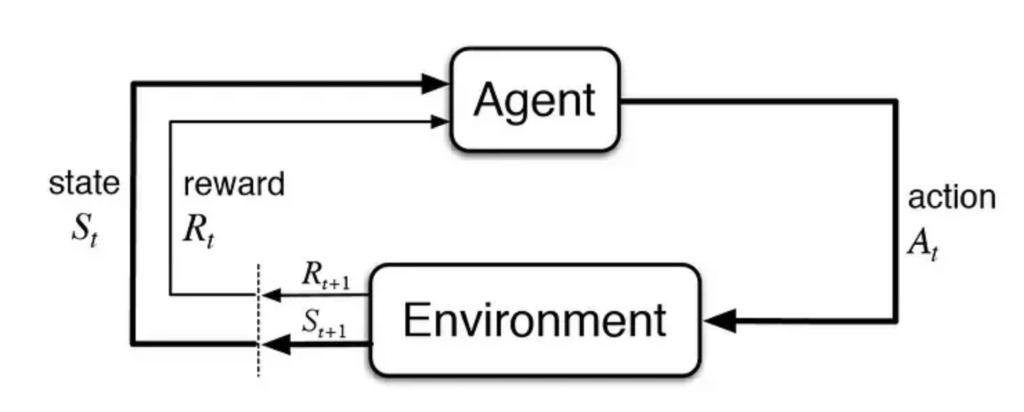
L’objectif global est de prédire la meilleure étape suivante pour obtenir la plus grande récompense finale. Si nous prenons le jeu d’échecs, chaque action peut être chaque coup, et l’état sera la situation actuelle du jeu, les récompenses au milieu des étapes peuvent être les pièces de l’adversaire qu’il capture. La plus grande récompense finale est de gagner la partie. Il apprend donc tout par l’expérience.
Conclusion :
J’espère que tu as bien compris ce qu’est l’apprentissage automatique (ou Machine Learning) et que tu as compris que l’apprentissage supervisé consiste à fournir des données étiquetées, que l’apprentissage non supervisé consiste à fournir à l’algorithme des données sans aucune étiquette particulière, que l’apprentissage semi-supervisé consiste à fournir des données à moitié étiquetées et à moitié non étiquetées, et que l’apprentissage par renforcement est totalement magique et qu’il apprend tout par itération (essais et erreurs).
Il s’agit là des connaissances de base que tu dois avoir sur le Machine Learning avant de te plonger dans l’apprentissage de ces algorithmes. Apprendre les algorithmes en détail est crucial dans la Data Science, je suis moi-même passé par là !
