
Il s’agit de la méthode la plus répandue pour effectuer des opérations d’apprentissage automatique (Machine Learning). Il est utilisé pour les données pour lesquelles il existe une correspondance précise entre les données d’entrée et de sortie. Par exemple, cette forme 🍎, nous avons une étiquette précise pour cela, “Pomme”. Nous montrons quelques-unes de ces formes à l’algorithme (par le biais du code), et la prochaine fois que tu montreras cette forme, elle sera prédite comme étant une pomme.
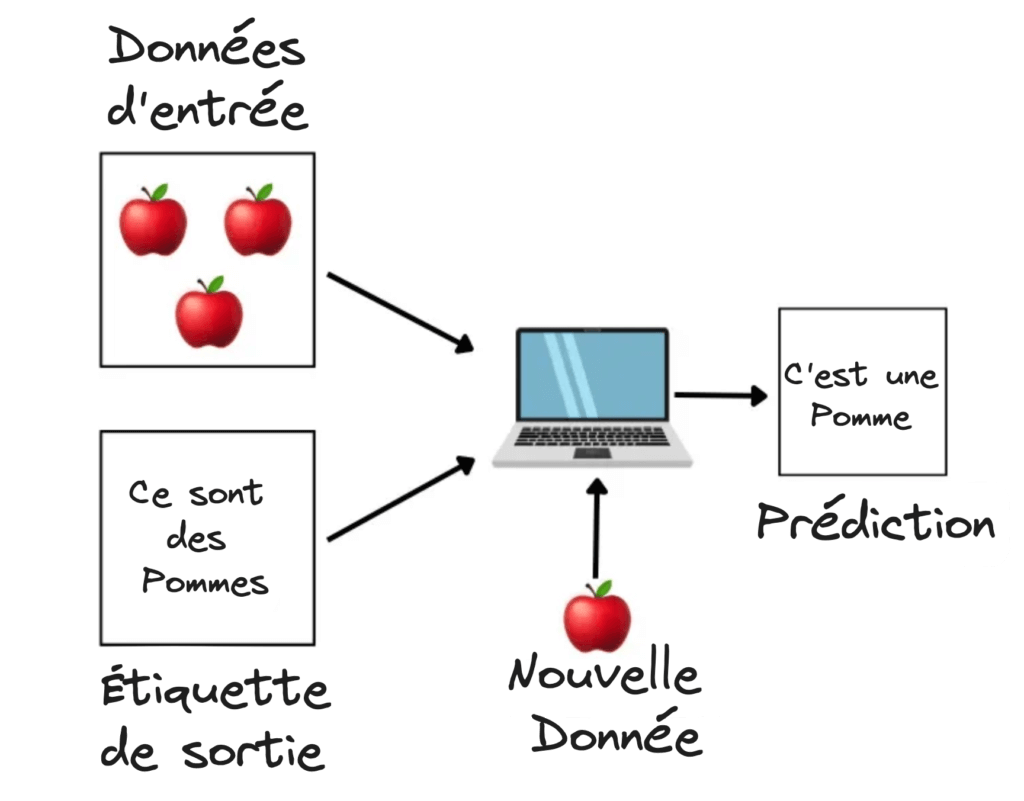
Nous pouvons envoyer à l’algorithme des données sous la forme d’exemples accompagnés d’étiquettes et, au fil du temps, l’algorithme trouvera le modèle approximatif entre les exemples et leurs étiquettes. Une fois qu’il est entièrement entraîné, nous pouvons envoyer les nouvelles données au modèle généré et il fera une prédiction.
Ces algorithmes supervisés sont appelés “orientés tâches”. Au fur et à mesure que nous lui fournissons de nouvelles données, il sera en mesure d’apprendre plus correctement et de faire de meilleures prédictions.
Quelques applications :
- Reconnaissance des visages
- Reconnaissance vocale
- Classification du spam
Et bien d’autres encore…
Types d’apprentissage supervisé #
D’une manière générale, nous pouvons classer l’apprentissage supervisé en deux catégories :
- la régression
- La classification
Régression #
Pour simplifier, les algorithmes de régression prédisent la variable continue (entier/float) sur la base des variables d’entrée. L’exemple utilisé dans le tutoriel précédent peut être considéré comme un algorithme de régression supervisé, qui prédit la taille du père sur la base de la taille d’une personne adulte. En effet, la taille que nous prédisons est une variable continue (float).
Algorithmes de régression #
- Régression linéaire
- Régression polynomiale
- Régression Lasso
- Régression de crête
- Régression exponentielle
- Régression logarithmique
Quelques applications de régression #
- Prédiction des résultats des étudiants sur la base des résultats des examens précédents.
- Prédiction du prix d’une maison en fonction de la taille de la pièce, de la localité, etc.
Classification #
Nous utilisons des algorithmes de classification pour prédire les catégories, mais pas la variable continue. Supposons que tu souhaites préciser si un e-mail est un spam ou non. Dans ce cas, la variable de prédiction n’est pas un nombre, c’est simplement une catégorie “oui” ou “non” (par exemple, “spam” ou “non spam”).
Algorithmes de classification #
- Régression logistique
- K-voisins les plus proches
- Arbres de décision
- Forêt aléatoire
- Machine à vecteur de support
- Bayes naïves
- Ada-Boost
- XG Boost
- Gradient Boosting
Quelques applications de classification #
- Détection des e-mails indésirables basée sur les données des e-mails précédents.
- Classification d’images pour identifier un chat ou un chien.
