
Comme son nom l’indique, il s’agit de l’opposé de l’apprentissage automatique supervisé. Dans l’apprentissage supervisé, nous avons une étiquette d’entrée et de sortie, alors que dans l’apprentissage non supervisé, il y a des données d’entrée, mais elles ne sont pas explicitement étiquetées ! Ces algorithmes sont capables d’apprendre à partir des données en trouvant des modèles implicites.
Prenons l’exemple d’un algorithme qui montre différents fruits d’un panier et qui, sur la base de leur forme, de leur taille et de leur couleur, les répartit en différents groupes ; lorsque tu montres un nouveau fruit, il fait une prédiction sur le groupe.
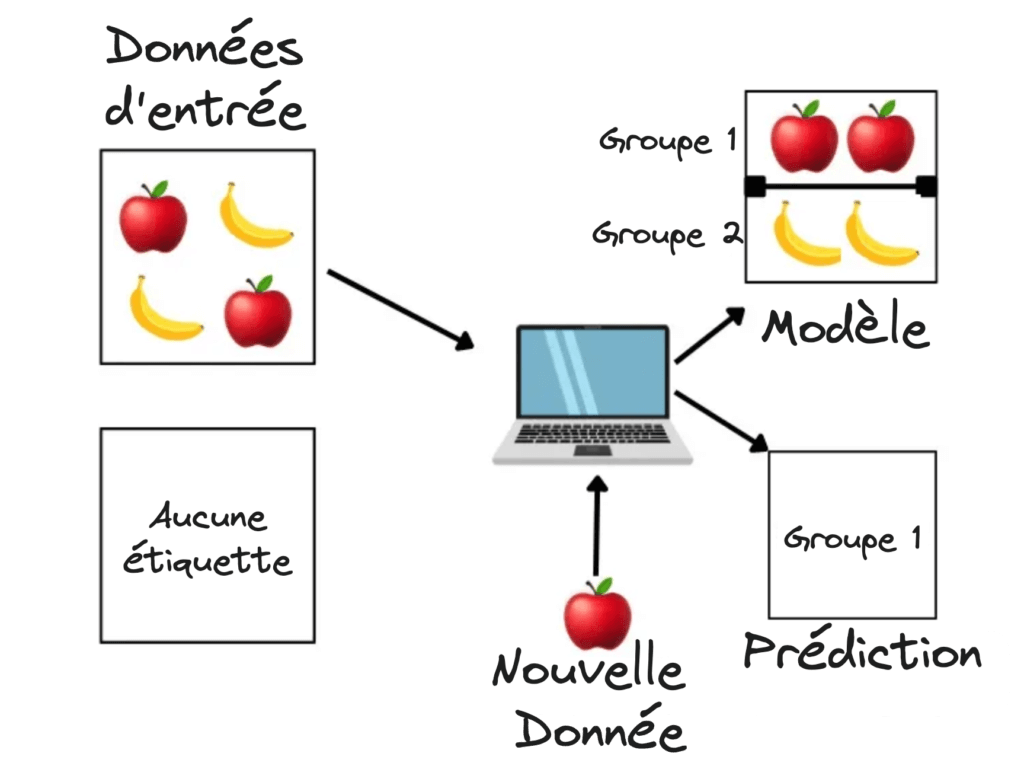
Les algorithmes non supervisés identifient les données sur la base de divers facteurs tels que leur densité, leurs structures, les segments similaires et d’autres caractéristiques similaires.
Quelques applications :
- Systèmes de recommandation
- Analyse du comportement des clients
- Regroupement d’articles d’actualité
Et bien d’autres encore…
Types d’apprentissage non supervisé #
D’une manière générale, nous pouvons les classer en 5 catégories, à savoir :
- Algorithmes de clustering
- Réduction de la dimensionnalité
- Détection des anomalies
- Apprentissage des règles d’association
- Autoencodeurs
Comprenons l’objectif de ces catégories et explorons les algorithmes qui en font partie.
Algorithmes de clustering #
La clustering (ou segmentation) est une technique qui consiste à regrouper dans un même groupe des ensembles d’objets similaires qui sont différents des objets de l’autre groupe sur la base de leurs similitudes. Comme dans le cas de la segmentation du panier de fruits ci-dessus.
Algorithmes dans la catégorie des clustering :
- K-Means
- DBSCAN
- Clustering hiérarchique
- Déplacement de la moyenne
Réduction de la dimensionnalité #
La réduction de la dimensionnalité revient à simplifier un problème complexe en se concentrant sur ses aspects les plus importants. Il s’agit d’une technique qui réduit le nombre de feature/caractéristiques (dimensions) d’un ensemble de données tout en conservant ses informations essentielles. Cette simplification rend l’analyse des données plus efficace et plus facile à visualiser.
Algorithmes dans la catégorie Réduction de la dimensionnalité :
- Analyse en composantes principales (ACP)
- t-Distributed Stochastic Neighbor Embedding (t-SNE) (intégration des voisins stochastiques distribués)
Détection d’anomalie #
La détection d’anomalies revient à trouver l’intrus dans un groupe. Il s’agit d’une technique utilisée dans l’analyse des données pour identifier les points de données inhabituels ou rares qui ne correspondent pas aux modèles attendus, c’est-à-dire les valeurs aberrantes. Cette technique est très utile pour détecter les anomalies dans divers domaines, de la détection des fraudes dans les transactions financières à l’identification des dysfonctionnements des équipements dans les systèmes industriels. Entraîner un modèle sur une seule classe – si quelque chose se trouve en dehors de cette classe, il peut s’agir d’une anomalie.
Algorithmes de détection d’anomalies :
- K-Means à une classe
- SVM à une classe
- Forêt d’isolement (Isolation Forest)
Apprentissage par règles d’association #
L’apprentissage par règles d’association permet de trouver des liens intéressants entre les articles achetés dans un magasin. Il s’agit d’une technique d’apprentissage automatique qui permet de découvrir des relations dans les données et d’identifier des modèles, des tendances et des associations entre des éléments ou des événements. L’apprentissage par règles d’association est un outil précieux pour comprendre le comportement des consommateurs, optimiser les stocks et améliorer les recommandations personnalisées.
Algorithmes dans la catégorie Apprentissage par règles d’association :
- Apriori
- FP-Growth (croissance des motifs fréquents)
- Algorithme Eclat
Autoencoders #
Il s’agit d’un type de réseau de neurones qui prend des données complexes, les compresse en un code, puis tente de recréer les données d’entrée à partir d’un code résumé. Ce processus de compression-décompression peut être utilisé pour supprimer le bruit des données visuelles telles que les images, les vidéos et les scanners médicaux afin d’en améliorer la qualité.
