

Si vous êtes Data Scientist, vous avez sans doute déjà travaillé avec des graphiques à nuage de points. Malgré leur simplicité, les graphiques à nuage de points sont des outils puissants pour visualiser des données. Il existe de nombreuses façons de les représenter en fonction des attributs tels que la couleur, la taille, la forme et le tracé de régression.
Dans cet article, je vous dis à peu près tout ce que vous devez savoir sur la visualisation de données avec des graphiques à nuage de points ! Nous allons passer en revue tous les paramètres et voir quand et comment les utiliser (code inclus). Il se peut que vous trouviez quelques bonnes surprises et astuces que vous pourrez ajouter à votre boîte à outils Data Science!
Importation des bibliothèques et chargement des données
Importation des bibliothèques
Avant de commencer à tracer nos différents graphiques à nuage de points, je vous invite à importer les bibliothèques dont nous aurons besoin :
import seaborn as sns import matplotlib.pyplot as plt
Chargement du dataset
Nous allons travailler sur le dataset iris et commencer par charger celui-ci dans un Dataframe:
df = sns.load_dataset('iris')Notion de régression
Lorsque nous traçons pour la première fois nos données sur un graphique à nuage de points, cela nous donne déjà un aperçu rapide de nos données :
# Graphique à nuage de points sns.regplot(x=df["sepal_length"], y=df["sepal_width"], fit_reg=False) plt.show()
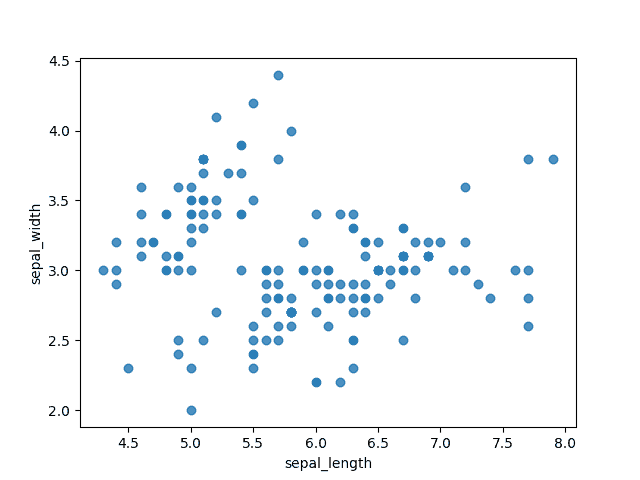
Nous pouvons déjà voir les groupes où la plupart des données semblent se regrouper. Ainsi nous pouvons rapidement identifier les valeurs aberrantes.
Mais il est également agréable de voir à quel point notre tâche peut être compliquée, nous pouvons le faire avec un tracé de régression :
# Régression linéaire ajustée au graphique précédent sns.regplot(x=df["sepal_length"], y=df["sepal_width"], fit_reg=True) plt.show()
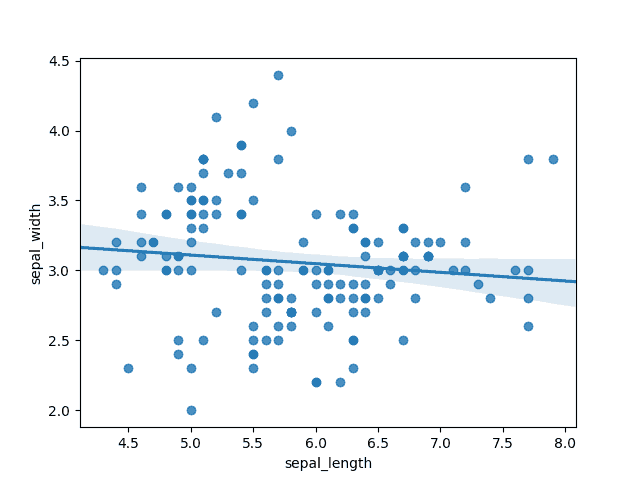
Dans la figure ci-dessus, nous avons réalisé un tracé linéaire. Il est assez facile de voir qu’une fonction linéaire ne fonctionnera pas car beaucoup de points sont assez éloignés de la ligne.
# Régression polynomiale ajustée au graphique d'origine sns.regplot(x=df["sepal_length"], y=df["sepal_width"], fit_reg=True, order=4) plt.show()
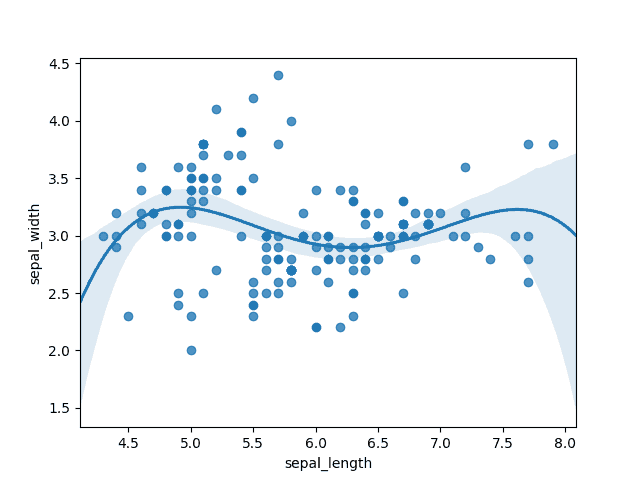
La fonction ci-dessus utilise un polynôme d’ordre 4 et semble beaucoup plus prometteuse. Il semble donc que nous aurons certainement besoin de quelque chose d’au moins 4 pour modéliser cet ensemble de données.
Couleur et forme des graphiques à nuage de points
Les couleurs et les formes peuvent être utilisées pour visualiser les différentes catégories de votre dataset. Couleur et forme sont très intuitives pour le système visuel humain. Lorsque vous regardez un graphique où les groupes de points ont des couleurs différentes ou des formes différentes, il est tout de suite évident que les points appartiennent à des groupes différents. Cela a naturellement un sens pour nous. Cette intuition naturelle correspond toujours à ce que vous voulez faire pour créer des visualisations de données claires et convaincantes.
“Ce qui est évident se passe d’explication.”
# On utilise l'argument 'hue' pour fournir une variable de facteur sns.lmplot( x="sepal_length", y="sepal_width", data=df, fit_reg=False, hue='species', legend=False) plt.legend(loc='lower right') plt.show()
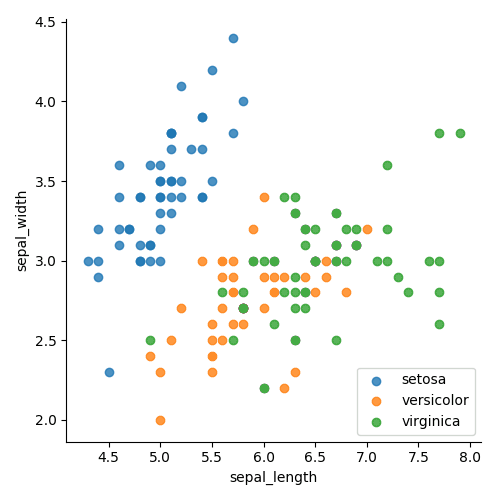
La figure ci-dessus montre les classes regroupées par couleur.
sns.lmplot( x="sepal_length", y="sepal_width", data=df, fit_reg=False, hue='species', legend=False, markers=["o", "P", "D"]) plt.legend(loc='lower right') plt.show()
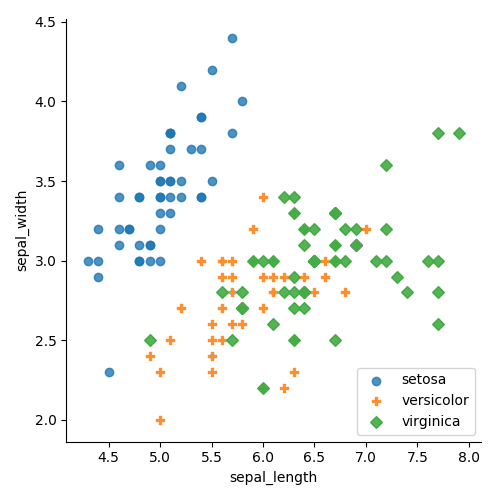
La figure ci-dessus montre les classes séparées par leur couleur et leur forme.
Dans les deux cas, il est beaucoup plus facile de voir les groupes que sur le premier graphique avec tous les points en bleu! Nous savons maintenant qu’il sera probablement facile de séparer la classe setosa avec une erreur faible et que nous devrions concentrer notre attention sur la manière de séparer les deux autres. Il est également clair qu’un seul tracé linéaire ne pourra séparer les points vert et orange; nous aurons besoin d’une dimension supérieure.
Choisir entre couleur et forme devient une question de préférence. Personnellement, je trouve la couleur un peu plus claire et intuitive, mais le choix vous appartient!
Distribution des points avec histogrammes
Les nuages de points avec des histogrammes marginaux sont ceux qui ont des histogrammes au dessus et sur les côtés, représentant la distribution des points pour les entités le long des axes x et y. C’est un petit ajout, mais il est bon de voir la répartition exacte de nos points et d’identifier plus précisément nos points aberrants.
sns.jointplot(x=df["sepal_length"], y=df["sepal_width"], kind='scatter') plt.show()
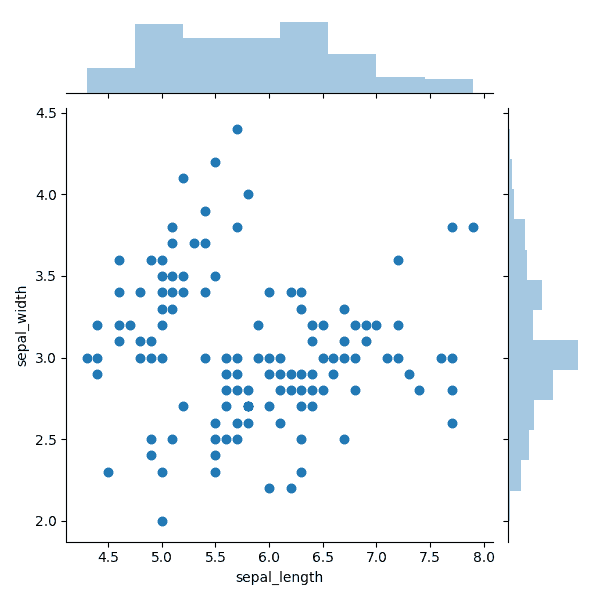
Dans la figure ci-dessus, nous pouvons voir pourquoi l’axe a une très forte concentration de points autour de 3,0. Comment sont-ils concentrés? C’est ce qui se voit le plus facilement dans l’histogramme complètement à droite, ce qui montre qu’il ya au moins trois fois plus de points autour de 3,0 que pour toute autre plage discrète. Nous constatons également qu’il n’ya pratiquement aucun point au dessus de 3,75 par rapport aux autres gammes. En revanche, pour l’axe des x, les choses sont un peu plus égales, à l’exception des valeurs extrêmes tout à droite.
Graphiques à bulles
Avec les graphiques à bulles, nous pouvons utiliser plusieurs variables pour coder les informations. Le nouveau paramètre que nous allons ajouter ici est la taille. Dans la figure ci-dessous, nous indiquons le nombre de frites mangées par chaque personne en fonction de leur taille et de leur poids. Notez qu’un nuage de points n’est qu’un outil de visualisation 2D, mais que, grâce à différents attributs, nous pouvons représenter des informations en 3 dimensions.
Ici, nous utilisons la couleur, la position et la taille. La position détermine la taille et le poids de la personne, la couleur détermine le sexe et la taille détermine le nombre de frites mangées! Le graphique à bulles nous permet de combiner facilement tous les attributs en un graphique afin que nous puissions voir les informations de grande dimension dans une simple vue 2D.
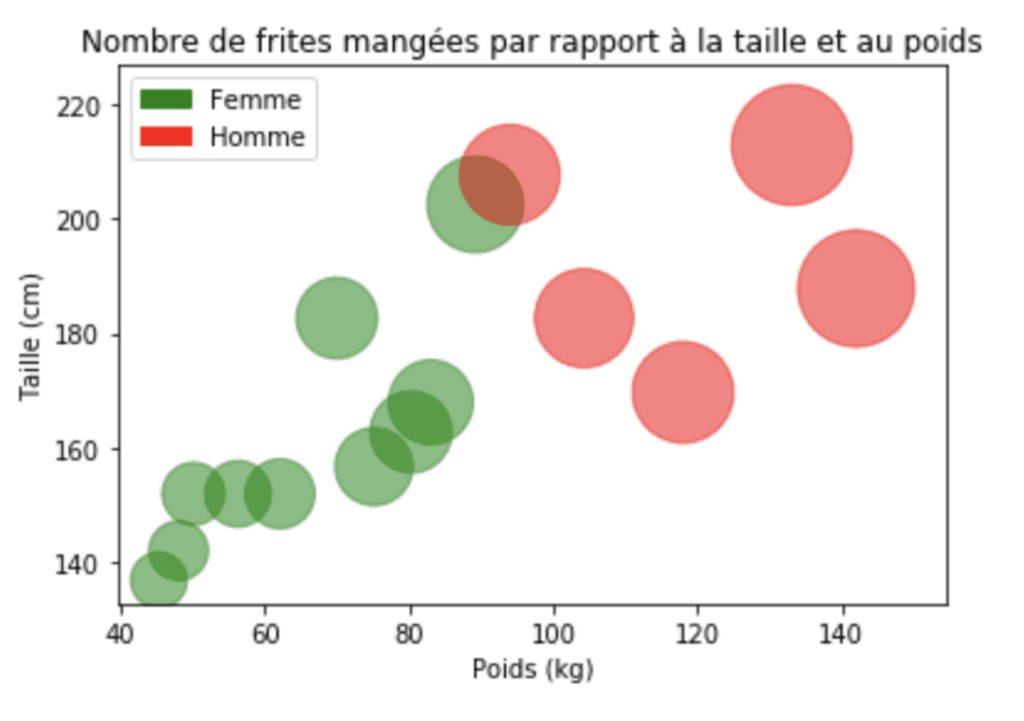
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
x = np.array([100, 105, 110, 124, 136, 155, 166, 177, 182, 196, 208, 230, 260, 294, 312])
y = np.array([54, 56, 60, 60, 60, 72, 62, 64, 66, 80, 82, 72, 67, 84, 74])
z = (x*y) / 60
for index, val in enumerate(z):
if index < 10:
color = 'g'
else:
color = 'r'
plt.scatter(x[index], y[index], s=z[index]*5, alpha=0.5, c=color)
red_patch = mpatches.Patch(color='red', label='Homme')
green_patch = mpatches.Patch(color='green', label='Femme')
plt.legend(handles=[green_patch, red_patch])
plt.title("Nombre de frites mangés par rapport au poids et à la taille")
plt.xlabel("Poids (kg)")
plt.ylabel("Taille (cm)")Si cet article vous a plus, n’hésitez pas à le partager 🙂











