Explorons certaines des meilleures options de visualisation avec la bibliothèque Seaborn pour la Data Science.
Les données constituent l’élément le plus important de toute tâche liée à l’intelligence artificielle ou à la Data science. Cependant, comment comprendre comment utiliser efficacement ces données à l’état brut ?
Regarder les données et jeter un coup d’œil sur quelques détails mineurs ne suffit pas toujours à calculer une solution avec précision. C’est pourquoi nous avons besoin de techniques de visualisation.
Les visualisations jouent un rôle essentiel dans le déchiffrage des modèles de données et nous aident à analyser les méthodes de Machine Learning ou de Deep Learning les plus efficaces qu’un passionné de Data Science peut utiliser pour obtenir des résultats de haute qualité. Ce sont l’une des étapes les plus importantes à suivre pour l’Analyse Exploratoire des Données (EDA en anglais) afin de calculer des solutions souhaitables.
Avant de commencer cet article sur seaborn, je vous recommande de consulter l’un de mes précédents travaux sur les techniques de visualisation de matplotlib et également mon guide de visualisation de données avec Matplotlib et Seaborn. Ils constituent un bon point de départ pour se familiariser avec les différents types de visualisations.
9 visualisations Seaborn pour la Data Science
Dans cet article, nous allons nous concentrer sur la bibliothèque seaborn. Nous allons apprendre les nombreuses techniques de visualisation disponibles dans cette bibliothèque que nous pouvons utiliser dans presque tous les projets. Seaborn est une bibliothèque Python de visualisation de données basée sur matplotlib. Elle fournit une interface de haut niveau pour dessiner des graphiques statistiques attrayants et informatifs.
Seaborn aide à simplifier les visualisations complexes grâce à sa simplicité et permet d’ajouter un attrait esthétique supplémentaire. Outre toutes les caractéristiques étonnantes de Seaborn, il est également construit au-dessus de la bibliothèque matplotlib. Par conséquent, nous pouvons produire des visualisations plus puissantes et productives en utilisant la combinaison de ces deux bibliothèques. Cependant, dans cet article, nous nous concentrerons uniquement sur la bibliothèque seaborn.
Données
Commençons rapidement à utiliser la bibliothèque seaborn en l’important. L’extrait de code suivant montre comment importer la bibliothèque comme il se doit. Une fois l’importation terminée, nous pouvons procéder à d’autres calculs et visualisations.
# Importation de la bibliothèque seaborn pour la visualisation import seaborn as sns
L’avantage de la bibliothèque seaborn est qu’elle offre un grand nombre de jeux de données par défaut à partir desquels vous pouvez commencer à vous entraîner et à tester vos techniques de visualisation. Bien qu’il existe plusieurs options de jeux de données comme celui sur les planètes, sur les pourboires, celui du Titanic, etc., parmi beaucoup d’autres, nous utiliserons le jeu de données iris pour ce projet. Vous trouverez ci-dessous l’extrait de code permettant de charger le jeu de données iris depuis la bibliothèque seaborn.
# Charger le jeu de données Iris
iris = sns.load_dataset("iris")
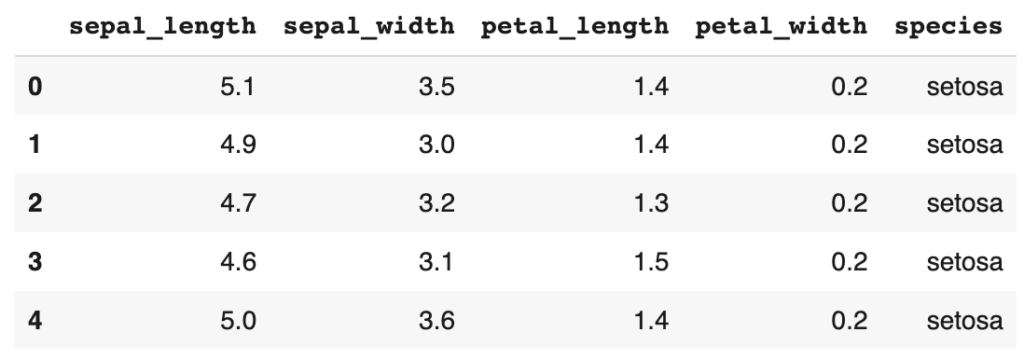
Dans les données Iris, nous avons trois espèces de fleurs, à savoir setosa, versicolor et virginica. Notre tâche consiste à visualiser les nombreux paramètres, tels que la largeur des sépales, la hauteur des sépales, la longueur des pétales et la largeur des pétales, qui sont associés à chacune de ces espèces. À l’aide de ces caractéristiques associées à chacune des espèces mentionnées, nous utiliserons certaines des meilleures options de la bibliothèque de seaborn pour les distinguer en conséquence. Voici un bref aperçu de notre jeu de données.
iris.head()
1. Diagramme de dispersion :
sns.scatterplot(x = "sepal_length",
y = "sepal_width",
data = iris,
hue = "species");
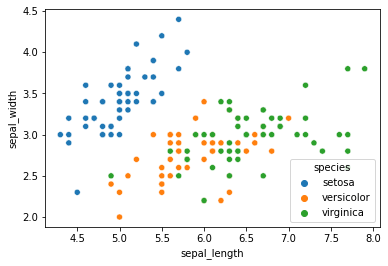
L’une des meilleures techniques pour commencer la visualisation consiste à appliquer un diagramme de dispersion (ou nuage de points) aux données disponibles. Le diagramme de dispersion des données offre à l’utilisateur une option intéressante pour voir dans quelle mesure les données se distinguent les unes des autres. Dans l’image du diagramme ci-dessus, nous pouvons remarquer qu’il est assez facile de distinguer setosa de versicolor et virginica. Cependant, versicolor et virginica semblent partager certaines similitudes étroites.
Pour définir un nuage de points dans la bibliothèque seaborn, nous pouvons directement mentionner les paramètres de l’axe x et de l’axe y que nous devons calculer pour la visualisation. Une fois que nous avons choisi les attributs de l’axe des x et de l’axe des y, nous pouvons mentionner le jeu de données et spécifier la teinte hue pour permettre le codage couleur du graphique visualisé.
2. Histogramme :
sns.histplot(x = "species",
y = "sepal_width",
data = iris);
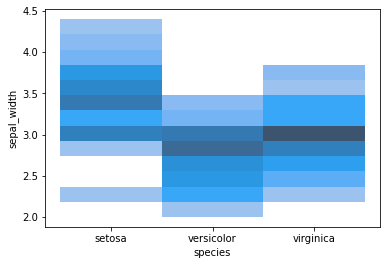
À partir du diagramme de dispersion précédent, nous avons déjà pu générer beaucoup d’informations sur l’ensemble des données relatives aux fleurs d’iris. Nous pouvons également utiliser d’autres graphiques, tels que les histogrammes, afin de permettre à l’utilisateur de visualiser dans quelle mesure certaines caractéristiques peuvent être distinguées. L’image ci-dessus montre un histogramme des espèces basé sur la largeur de leurs sépales.
Dans l’extrait de code ci-dessus, nous avons utilisé la fonction histplot de la bibliothèque seaborn avec le jeu de données iris, en mentionnant les espèces et la largeur des sépales en conséquence. Il est fortement recommandé aux utilisateurs de mesurer les variétés des espèces avec chacun des autres paramètres de caractéristiques.
3. Diagramme à barres
sns.barplot(x = "species",
y = "sepal_width",
data = iris);
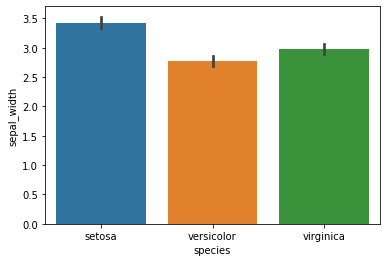
Comme pour l’histogramme, nous pouvons également tracer un diagramme à barres en utilisant la fonction barplot de la bibliothèque seaborn avec l’ensemble de données sur les iris, en mentionnant l’espèce et la largeur du sépale en conséquence. La visualisation ci-dessus représente un diagramme à barres et montre un aspect plus coloré et plus esthétique de la largeur du sépale de chacune des espèces mentionnées.
4. Diagramme en boîte
sns.boxplot(x = "species",
y = "sepal_width",
data = iris);
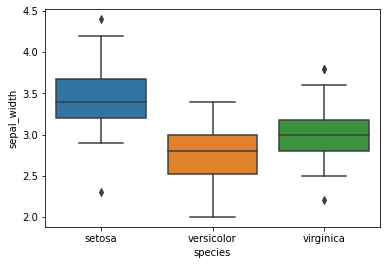
Contrairement aux deux graphiques précédents, nous allons nous concentrer sur deux autres graphiques qui nous donneront une fourchette plus spécifique et plus appropriée dans laquelle se situent les paramètres des différentes variétés de fleurs. Tout d’abord, nous examinerons le diagramme en boîte de la bibliothèque Seaborn qui fournira à l’utilisateur une gamme spécifique de chacune des espèces.
Le concept de médiane, de percentile et de quantile est utilisé dans ces méthodes pour tracer les graphiques. Les extrémités des diagrammes en boîte représentent les moustaches qui sont construites dans un intervalle inter-quartile. Le boxplot peut être tracé dans la bibliothèque seaborn en mentionnant le jeu de données iris, l’espèce et le paramètre particulier.
5. Diagramme en violon
sns.violinplot(x = "species",
y = "sepal_width",
data = iris);

Pour simplifier le concept des diagrammes en boîte et des plages médianes, nous pouvons utiliser les diagrammes en violon qui nous permettent d’avoir une compréhension plus intuitive de la plage de fonctionnement des caractéristiques spécifiques. Tout comme le boxplot, le violinplot peut être tracé dans la bibliothèque seaborn en mentionnant l’ensemble de données iris, l’espèce et le paramètre particulier.
6. Facet Grid avec histplot
sns.FacetGrid(iris, hue="species", height = 5).map(sns.histplot, "petal_width").add_legend();
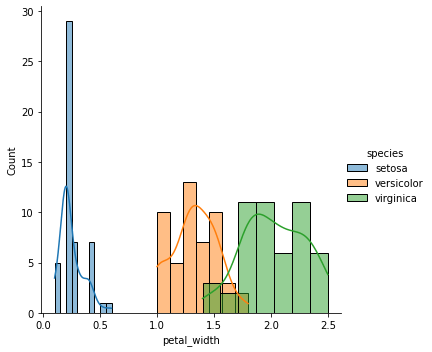
Dans la visualisation suivante, nous pouvons utiliser les graphiques de distribution (histplot) pour comprendre la distribution des données dans l’ensemble de données sur les iris. Le graphique de distribution nous aide à comprendre intuitivement la densité de probabilité de l’espèce, c’est-à-dire la probabilité par unité sur l’axe des abscisses. Nous pouvons tracer le graphique de la manière suivante, comme indiqué dans l’extrait de code ci-dessus.
7. Diagrammes de paires
sns.pairplot(iris, hue="species", height=3);
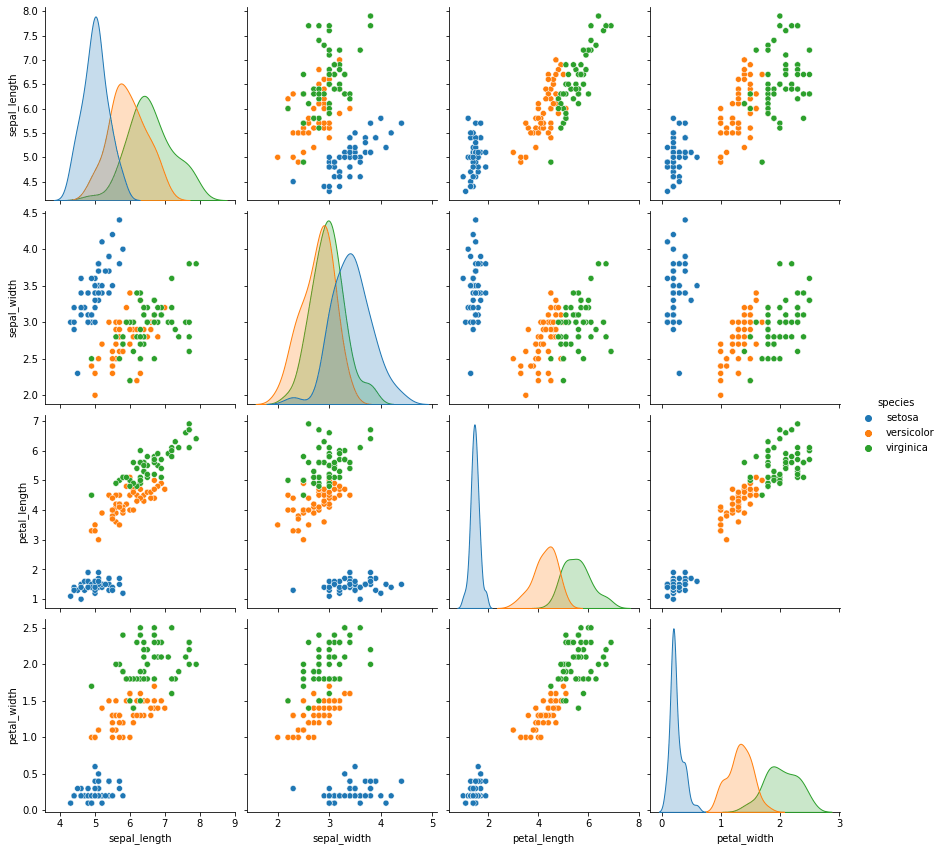
L’une des techniques de visualisation les plus significatives dans seaborn, en particulier pour une tâche comme un ensemble de données sur la fleur d’iris, est l’utilité des diagrammes de paires. L’image ci-dessus montre une représentation détaillée des diagrammes de paires de nombreuses caractéristiques et peut-être la vue la plus détaillée de la compréhension de notre ensemble de données sur l’iris. Les diagrammes par paire aident à caractériser et à distinguer les meilleures caractéristiques parmi deux variables particulières.
L’extrait de code ci-dessus peut être utilisé pour tracer les diagrammes en paires pour les différentes espèces de l’ensemble de données de l’iris. Les diagrammes en paires font partie des meilleures options pour l’analyse des données bidimensionnelles. Cependant, leur utilité diminue avec des données de plus grande dimension et ils ne sont pas extrêmement utiles dans les cas où l’ensemble de données est énorme.
8. Carte de clusters
sns.clustermap(iris.drop("species", axis = 1));
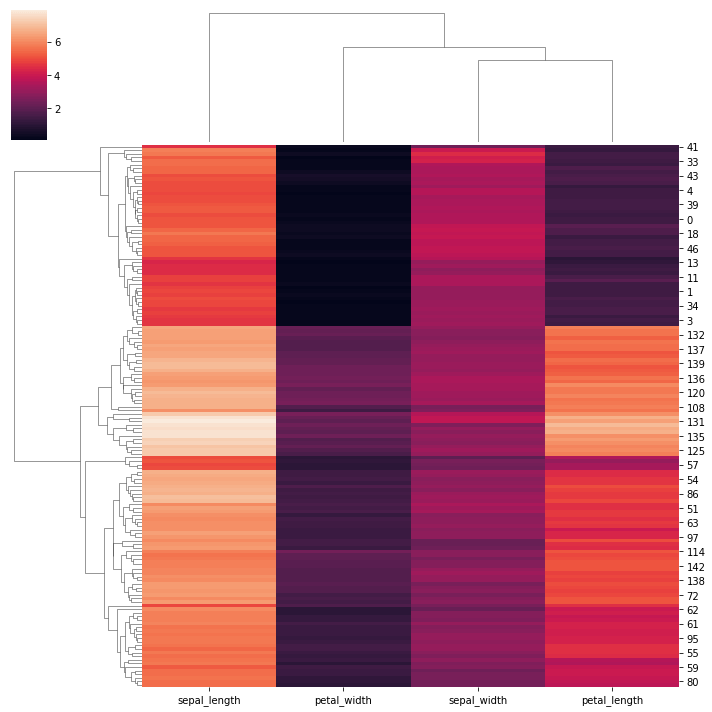
La carte de clusters de seaborn permet à l’utilisateur de tracer un ensemble de données matricielles sous forme de carte thermique à clusters hiérarchiques. Les cartes de clusters sont un excellent outil pour déterminer combien de points de données sont situés dans une région spécifique. La fonction clustermap de seaborn peut être légèrement complexe, mais elle permet à l’utilisateur de comprendre en détail la plupart des caractéristiques fournies par le jeu de données. Les cartes de clusters peuvent être une technique de visualisation importante pour des projets et des tâches spécifiques.
9. Cartes thermiques
sns.heatmap(iris.corr());
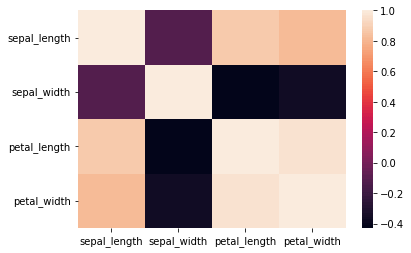
Enfin, nous examinerons la fonction heatmap de la bibliothèque seaborn, qui est l’une des techniques de visualisation les plus utiles. La visualisation de la carte thermique (ou carte de chaleur) nous aide à calculer la corrélation entre les différentes variables et paramètres. En utilisant la fonction heatmap, nous pouvons obtenir une brève compréhension de la façon dont plusieurs variables sont liées les unes aux autres.
Pour effectuer l’opération heatmap sur l’ensemble de données de l’iris, il est préférable de prendre la corrélation des données de l’iris en utilisant la fonction corr(). Une fois que nous avons un tableau de corrélation, nous pouvons le tracer avec la commande indiquée dans l’extrait de code ci-dessus pour produire le résultat montré dans la figure ci-dessus. Les cartes thermiques sont une technique de visualisation importante pour le réglage des hyperparamètres des modèles de Machine Learning.
Conclusion Seaborn pour la Data Science
La visualisation et l’analyse exploratoire des données (EDA) resteront toujours des éléments essentiels des projets de Data Science. Ce sont les seules méthodes qui nous permettent d’avoir une compréhension plus ou moins correcte du type de données que nous traitons dans un projet spécifique. Par conséquent, tout data scientist doit apprendre et se familiariser avec ces techniques de visualisation.
Dans cet article, nous avons découvert la bibliothèque Seaborn, qui est l’un des meilleurs outils de visualisation en Python pour les tâches et les projets de Data Science. Seaborn est plus à l’aise dans la manipulation des DataFrames Pandas. Elle utilise des ensembles de méthodes de base pour fournir de beaux graphiques en Python. Nous avons compris une variété de techniques de visualisation différentes dans la bibliothèque Seaborn, ce qui nous a permis de mieux comprendre les données ou les ensembles de données utilisés dans un projet particulier.
Si tu veux aller plus loin dans la maîtrise de la programmation Python pour la Data Science (avec notamment les bibliothèques NumPy, Pandas, Matplotlib, Seaborn…), j’ai un programme adapté que tu peux rejoindre ici.