Python est le langage de prédilection des spécialistes des données – et ce que pour de bonnes raisons. Il fournit à la fois l’écosystème le plus vaste pour un langage de programmation et la profondeur d’excellentes bibliothèques de calcul scientifique. Si vous ne connaissez pas encore le langage Python, regardez mon cours Python ici (ou même pour aller plus loin le cours de manipulation de données avec Pandas).
Parmi ses bibliothèques de calcul scientifique, Pandas est la plus utile pour les opérations de Data Science. Pandas associé à Scikit-learn, c’est le Graal. Cet article décrit 12 techniques de manipulation de données en Python. J’y partage quelques conseils et astuces qui vous permettront de travailler plus rapidement.
Pour vous aider à mieux comprendre, j’ai pris un dataset pour effectuer ces opérations et manipulations.
Nous utiliserons le dataset sur le problème de prédiction de prêt, à télécharger ici.
On commence ? Yess !
Je vais commencer par importer des modules et charger le dataset dans l’environnement Python :
import pandas as pd
import numpy as np
data = pd.read_csv("train.csv", index_col="Loan_ID")# 1 – Indexation booléenne
Que faites-vous si vous souhaitez filtrer les valeurs d’une colonne (ou plusieurs) en fonction de conditions sur les valeurs d’autres colonnes?
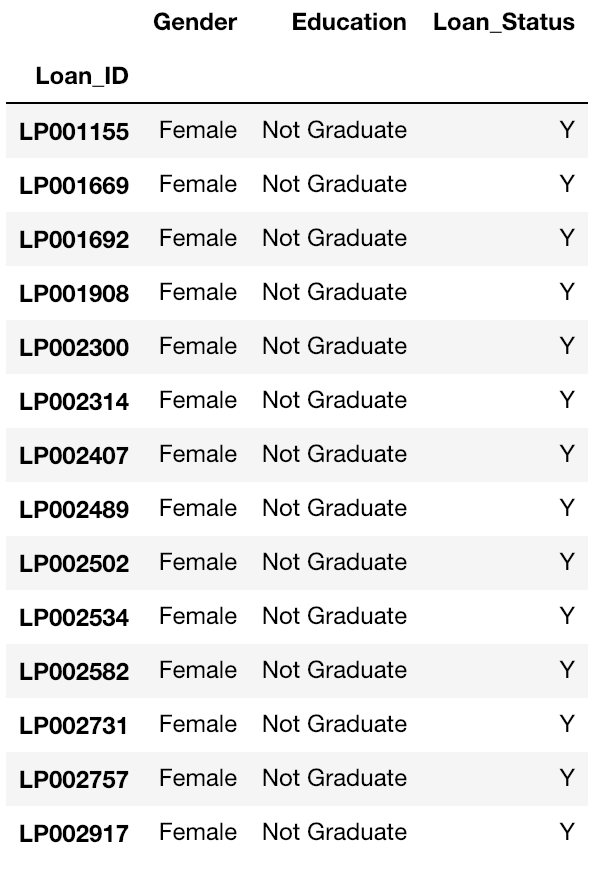
Par exemple, nous voulons une liste de toutes les femmes qui ne sont pas diplômées et ont obtenu un prêt. L’indexation booléenne peut aider ici.
Vous pouvez utiliser le code suivant :
data.loc[(data["Gender"]=="Female") & (data["Education"]=="Not Graduate") & (data["Loan_Status"]=="Y"), ["Gender","Education","Loan_Status"]]
(Pour aller plus loin: documentation Indexing and Selecting Data)
# 2 – La fonction apply
C’est l’une des principales fonctions pour jouer avec les données et créer de nouvelles variables. apply retourne une valeur après avoir passé chaque ligne / colonne d’un DataFRame avec une fonction. La fonction peut être une fonction par défaut ou alors définie par l’utilisateur.
Par exemple, ici, apply peut être utilisé pour trouver les valeurs manquantes de chaque ligne et colonne :
# Créer une nouvelle fonction qui détermine si la valeur en paramètre est manquante:
def num_missing(x):
return sum(x.isnull())
# On applique cette fonction pour chaque colonne:
print("Valeurs manquantes par colonne:")
print(data.apply(num_missing, axis=0)) #axis=0 définit que la fonction sera bien appliquée sur chaque colonne
# Puis application pour chaque ligne:
print("\nValeurs manquantes par ligne:")
print(data.apply(num_missing, axis=1).head()) #axis=1 définit que la fonction sera bien appliquée sur chaque ligne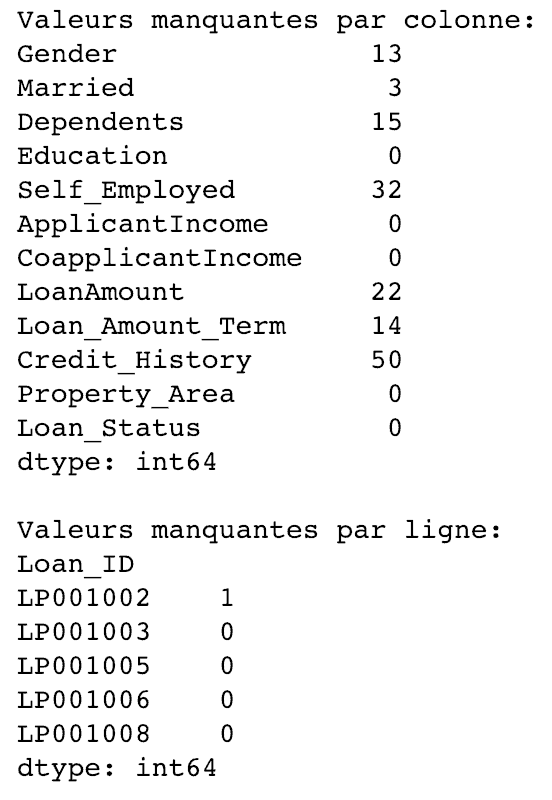
Nous obtenons ainsi le résultat souhaité.
Remarque: la méthode head() est utilisée dans la deuxième application car le résultat contenait beaucoup trop de lignes.
(Pour aller plus loin: documentation apply de Pandas)
# 3 – Imputation des valeurs manquantes
La méthode fillna() le fait en une ligne. On l’utilise pour mettre à jour les valeurs manquantes avec la moyenne globale (mean) / mode / médiane (median) de la colonne. Imputons les colonnes Gender (sexe), Married (mariés) et Self_Employed (à son compte) avec leurs modes respectifs.
# Tout d'abord nous importons une fonction pour déterminer le mode from scipy.stats import mode data['Gender'].mode()
0 Male dtype: object
Cela retourne à la fois le mode et le nombre. Rappelez-vous que le mode peut être un tableau car il peut y avoir plusieurs valeurs avec une fréquence élevée.
Nous prendrons toujours le premier par défaut en utilisant :
data['Gender'].mode()[0]
'Male'
Maintenant, nous pouvons remplir les valeurs manquantes et vérifier en utilisant la technique # 2.
# Imputer les valeurs: data['Gender'].fillna(data['Gender'].mode().iloc[0], inplace=True) data['Married'].fillna(data['Married'].mode().iloc[0], inplace=True) data['Self_Employed'].fillna(data['Self_Employed'].mode().iloc[0], inplace=True) # Puis on re-teste les valeurs manquantes de nouveau pour valider: print(data.apply(num_missing, axis=0))
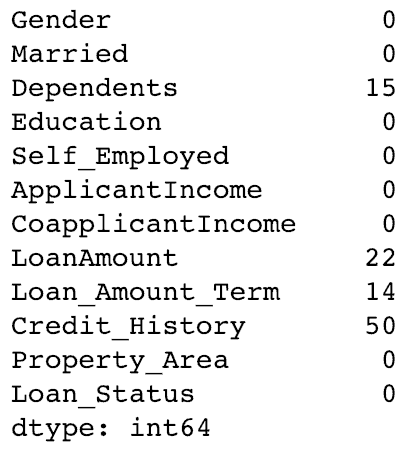
Par conséquent, il est confirmé que les valeurs manquantes sont imputées. Veuillez noter qu’il s’agit de la forme d’imputation la plus primitive. D’autres techniques sophistiquées incluent la modélisation des valeurs manquantes, en utilisant des moyennes groupées (moyenne / mode / médiane).
(Pour aller plus loin: documentation fillna() de Pandas & documentation mode() de Pandas)
#4 – Table Pivot
Pandas peut être utilisé pour créer des tableaux croisés dynamiques de style MS Excel. Par exemple, dans ce cas, une colonne clé est LoanAmount qui a des valeurs manquantes. Nous pouvons l’imputer en utilisant le montant moyen de chaque groupe Gender, Married et Self_Employed.
La moyenne de la colonne LoanAmount de chaque groupe peut être déterminé comme suit :
# Utilisation d'un Pivot de Table impute_grps = data.pivot_table(values=["LoanAmount"], index=["Gender","Married","Self_Employed"], aggfunc=np.mean) print(impute_grps)

(Pour aller plus loin: documentation Pandas Table Pivot)
# 5 – Multi-indexage
Si on regarde la résultat du 3e point, on remarque une propriété étrange. Chaque index est composé d’une combinaison de 3 valeurs. C’est ce qu’on appelle le multi-indexage. Cela aide à effectuer des opérations très rapidement.
En reprenant l’exemple du # 3, nous avons les valeurs pour chaque groupe mais elles n’ont pas été imputées.
Cela peut être fait en utilisant les différentes techniques apprises jusqu’à présent.
# Itérer seulement à travers les lignes avec des valeurs manquantes sur la colonne LoanAmount for i,row in data.loc[data['LoanAmount'].isnull(),:].iterrows(): ind = tuple([row['Gender'],row['Married'],row['Self_Employed']]) data.loc[i,'LoanAmount'] = impute_grps.loc[ind].values[0] # On vérifie les valeurs manquantes: print(data.apply(num_missing, axis=0))
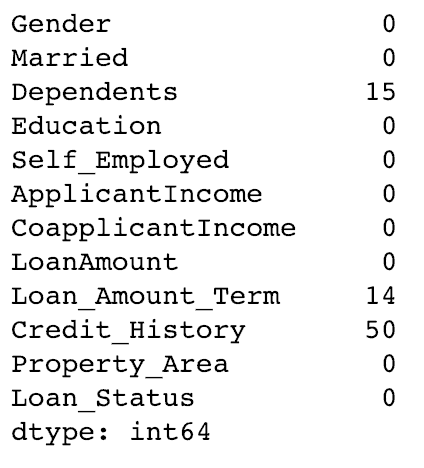
Remarque:
- Le multi-index nécessite un tuple pour définir des groupes d’index dans l’instruction loc. C’est un tuple utilisé dans la fonction.
- Le suffixe .values[0] est requis car, par défaut, un élément de série est renvoyé avec un index ne correspondant pas à celui de la structure de données. Dans ce cas, une affectation directe génère une erreur.
# 6. Fonction crosstab
Cette fonction est utilisée pour obtenir un premier aperçu des données. Ici, nous pouvons valider une hypothèse de base. Par exemple, dans ce cas, la colonne Credit_History devrait affecter de manière significative le statut du prêt. Ceci peut être testé en utilisant la tabulation croisée crosstab, exemple ci-dessous :
pd.crosstab(data["Credit_History"],data["Loan_Status"],margins=True)
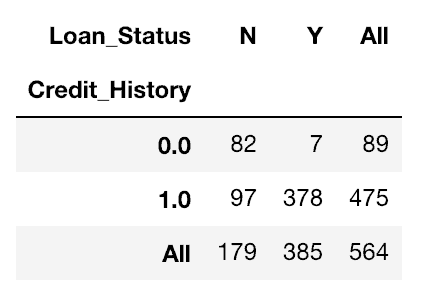
Ce sont des nombres absolus. Cependant, les pourcentages peuvent être plus intuitifs pour permettre une analyse rapide.
Nous pouvons le faire en utilisant la fonction apply :
def percConvert(ser):
return ser/float(ser[-1])
pd.crosstab(data["Credit_History"],data["Loan_Status"],margins=True).apply(percConvert, axis=1)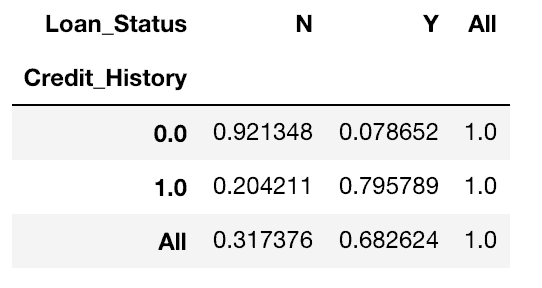
Il est maintenant évident que les personnes ayant des antécédents de crédit ont beaucoup plus de chances d’obtenir un prêt: 80% des personnes ayant des antécédents de crédit ont obtenu un prêt, contre seulement 8% sans antécédents de crédit.
Mais ce n’est pas tout. Cela raconte une histoire intéressante. Puisque je sais qu’avoir des antécédents de crédit est très important, si je prédis que le statut du prêt est égal à Y pour ceux qui ont des antécédents de crédit et à N sinon. Étonnamment, nous aurons raison 82 + 378 = 460 fois sur 614, ce qui représente 75%!
Croyez-moi, augmenter la précision même de 0,001% au-delà de cette marque est une tâche ardue.
Remarque: 75% c’est sur le dataset train. Le dataset test sera légèrement différent mais proche. J’espère aussi que cela donne une certaine idée de la raison pour laquelle même une augmentation de 0,05% de la précision peut entraîner un saut de 500 rangs dans le classement Kaggle.
(Pour aller plus loin: documentation crosstab Pandas)
# 7 – Fusionner des DataFrames
La fusion de DataFrames devient essentielle lorsque nous devons rassembler des informations provenant de différentes sources. Prenons un cas hypothétique où les taux de propriété moyens (prix par mètre carré) sont disponibles pour différents types de propriété.
Définissons un cadre de données comme suit :
prop_rates = pd.DataFrame([1000, 5000, 12000], index=['Rural','Semiurban','Urban'],columns=['rates']) prop_rates
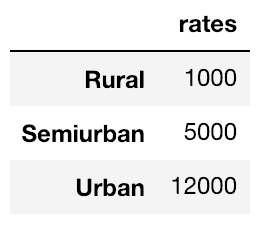
Nous pouvons maintenant fusionner ces informations avec le DataFrame d’origine :
data_merged = data.merge(right=prop_rates, how='inner',left_on='Property_Area',right_index=True, sort=False) data_merged.pivot_table(values='Credit_History',index=['Property_Area','rates'], aggfunc=len)

Le tableau croisé dynamique valide l’opération de fusion réussie. Notez que l’argument values n’est pas pertinent ici car nous comptons simplement les valeurs.
(Pour aller plus loin: documentation merge Pandas)
#8 – Trier des DataFrames
Pandas permet un tri facile en fonction de plusieurs colonnes.
Cela peut être fait comme cela :
data_sorted = data.sort_values(['ApplicantIncome','CoapplicantIncome'], ascending=False) data_sorted[['ApplicantIncome','CoapplicantIncome']].head(10)
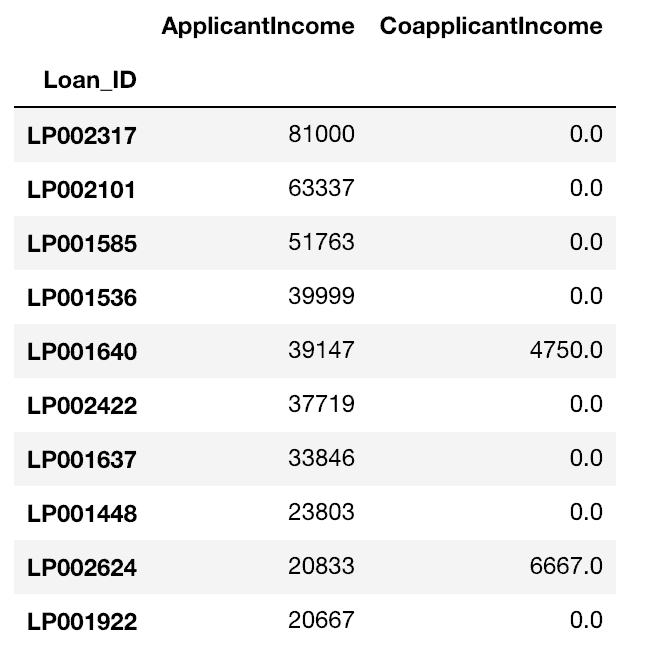
(Pour aller plus loin: documentation sort_values Pandas)
# 9 – Tracer des boîtes à moustache & des histogrammes
Beaucoup d’entre vous ignorent peut-être que les diagrammes en boîte et les histogrammes peuvent être directement tracés avec Pandas et qu’il n’est pas nécessaire d’appeler séparément la librairie matplotlib. C’est juste une commande sur une ligne. Par exemple, si nous voulons comparer la distribution des valeurs ApplicantIncome par les valeurs de Loan_Status :
data.boxplot(column="ApplicantIncome",by="Loan_Status")
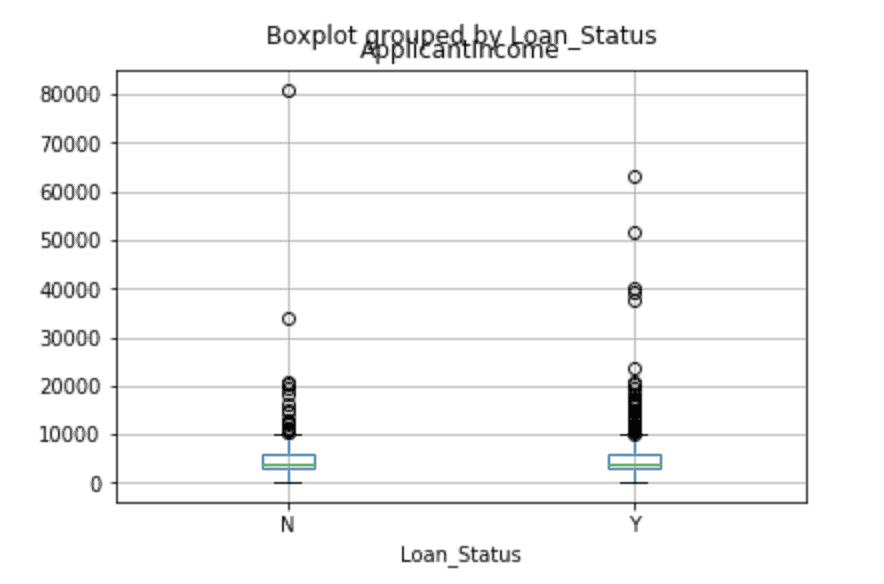
data.hist(column="ApplicantIncome",by="Loan_Status",bins=30)
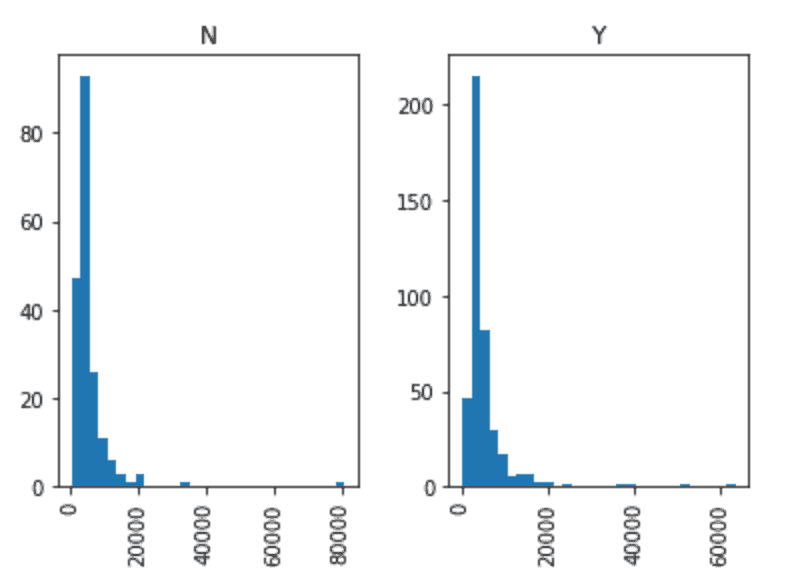
Cela montre que le revenu n’est pas un facteur décisif en soi, car il n’y a pas de différence appréciable entre les personnes qui ont reçu et qui se sont vu refuser le prêt.
(Pour aller plus loin: documentation hist Pandas & documentation boxplot Pandas)
# 10 – Fonction cut pour le regroupement de valeurs
Parfois, les valeurs numériques ont plus de sens si elles sont regroupées. Par exemple, si nous essayons de modéliser le trafic (nombre de voitures sur la route) avec l’heure du jour (minutes). La minute exacte d’une heure peut ne pas être très utile pour prévoir le trafic par rapport à la période réelle de la journée, telle que “Matin”, “Après-midi”, “Soirée”, “Nuit”, “Nuit tardive”. La modélisation du trafic de cette manière sera plus intuitive et évitera les sur-ajustements.
Nous définissons ici une fonction simple qui peut être réutilisée pour regrouper assez facilement n’importe quelle variable :
# Binning:
def binning(col, cut_points, labels=None):
# Définir les valeurs min et max:
minval = col.min()
maxval = col.max()
# Créer une liste en ajoutant min et max à cut_points
break_points = [minval] + cut_points + [maxval]
# Si aucun label, on utilise par défaut les labels 0 ... (n-1)
if not labels:
labels = range(len(cut_points)+1)
# Regroupement en utilisant la fonction cut de Pandas
colBin = pd.cut(col,bins=break_points,labels=labels,include_lowest=True)
return colBin
cut_points = [90,140,190]
labels = ["low","medium","high","very high"]
data["LoanAmount_Bin"] = binning(data["LoanAmount"], cut_points, labels)
print(pd.value_counts(data["LoanAmount_Bin"], sort=False))
(Pour aller plus loin: documentation cut Pandas)
# 11 – Codage des données nominales
Nous trouvons souvent le cas où nous devons modifier les catégories d’une variable nominale.
Cela peut être dû à diverses raisons :
- Certains algorithmes (comme la régression logistique) exigent que toutes les entrées soient numériques. Les variables nominales sont donc généralement codées 0, 1… (n-1)
- Parfois, une catégorie peut être représentée de 2 manières. Par exemple la température peut être enregistrée comme“High”, “Medium”, “Low”, “H”, “low”. Ici, “High” et “H” se réfèrent à la même catégorie. De même, dans «Low» et «low», il n’y a qu’une différence de cas. Mais python les lirait comme des niveaux différents.
- Certaines catégories peuvent avoir de très basses fréquences et il est généralement préférable de les combiner.
J’ai défini une fonction générique qui prend en entrée un dictionnaire et code les valeurs à l’aide de la fonction replace de Pandas.
# Définit une fonction générique en utilisant la fonction replace de Pandas
def coding(col, codeDict):
colCoded = pd.Series(col, copy=True)
for key, value in codeDict.items():
colCoded.replace(key, value, inplace=True)
return colCoded
# Coder LoanStatus avec Y=1 et N=0:
print('Avant codage:')
print(pd.value_counts(data["Loan_Status"]))
data["Loan_Status_Coded"] = coding(data["Loan_Status"], {'N':0,'Y':1})
print('\nAprès codage:')
print(pd.value_counts(data["Loan_Status_Coded"]))
Des comptes similaires avant et après prouvent notre codage est correct.
(Pour aller plus loin: documentation replace Pandas)
# 12 – Itération sur les lignes d’un DataFrame
Ce n’est pas une opération fréquemment utilisée. Cependant, vous ne voulez pas rester coincé. Non? Il peut parfois être nécessaire de parcourir toutes les lignes à l’aide d’une boucle for. Par exemple, un problème courant auquel nous sommes confrontés est le traitement incorrect des variables en Python. Cela se produit généralement lorsque:
- Les variables nominales avec des catégories numériques sont traitées comme des nombres.
- Les variables numériques avec des caractères entrés dans l’une des lignes (en raison d’une erreur de données) sont considérées comme catégoriques.
Il est donc généralement conseillé de définir manuellement les types de colonne.
Si nous vérifions les types de données de toutes les colonnes :
# Vérifier les types de données: data.dtypes

Nous voyons ici que Credit_History est une variable nominale mais apparaissant comme de type float (nombre à virgules). Un bon moyen de résoudre ces problèmes consiste à créer un fichier csv avec des noms et des types de colonnes. De cette façon, nous pouvons créer une fonction générique pour lire le fichier et affecter des types de données de colonne. Par exemple, ici, j’ai créé un fichier csv datatypes.csv.
# Lecture du fichier:
colTypes = pd.read_csv('datatypes.csv')
print(colTypes)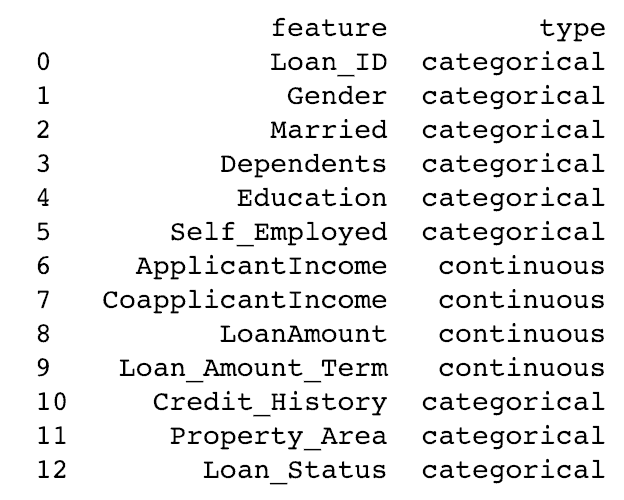
Après avoir chargé ce fichier, nous pouvons parcourir chaque ligne et attribuer le type de données en utilisant la colonne type au nom de variable défini dans la colonne feature.
# Itérer à travers chaque ligne et assigner le type de variable
# Remarque: astype est utilisé pour assigner des types
for i, row in colTypes.iterrows(): # i: dataframe index; row: chaque ligne (row) au format series
if row['type']=="categorical":
data[row['feature']]=data[row['feature']].astype(np.object)
elif row['type']=="continuous":
data[row['feature']]=data[row['feature']].astype(np.float)
print(data.dtypes)Maintenant, la colonne credit_history est modifiée en type object utilisé pour représenter les variables nominales avec Pandas.
(Pour aller plus loin: documentation iterrows Pandas)
Conclusion
Dans cet article, nous avons couvert diverses fonctions de Pandas qui peuvent nous rendre la vie facile tout en effectuant une exploration des données et traiter des caractéristiques. Nous avons également défini certaines fonctions génériques pouvant être réutilisées pour atteindre un objectif similaire sur différents datasets.
Avez-vous trouvé cet article utile? Utilisez-vous de meilleurs techniques (plus faciles / plus rapides) pour effectuer les tâches décrites ci-dessus? Pensez-vous qu’il existe de meilleures alternatives à la librairie Pandas en Python? Partagez vos idées en commentaire ci-dessous, j’en serai heureux 🙂