Dans cet article, nous allons parler de la façon de remodeler les données et les analyser en utilisant les méthodes pivot, pivot_table, stack, unstack, melt.
Vous trouverez le notebook de code ici.
Remodeler les données à l’aide de la méthode pivot()
Lorsque nous voulons organiser le DataFrame par un index et une colonne donnés, nous pouvons utiliser la méthode pivot() sur un DataFrame.
Commençons par préparer des données fictives :
df = pd.DataFrame({
"nom": ["Bastien", "Bastien", "Bastien", "Salma", "Salma", "Salma", "Alain", "Alain", "Alain"],
"cours": ["A", "B", "C", "A", "B", "C", "A", "B", "C"],
"note": [66, 75, 80, 70, 77, 81, 80, 85, 90],
"genre": ["H", "H", "H", "F", "F", "F", "H", "H", "H"],
})
Comme vous pouvez le constater, afin de représenter les données sous forme tabulaire, le nom de la même personne et le cours apparaissent de manière répétée dans de nombreuses lignes.
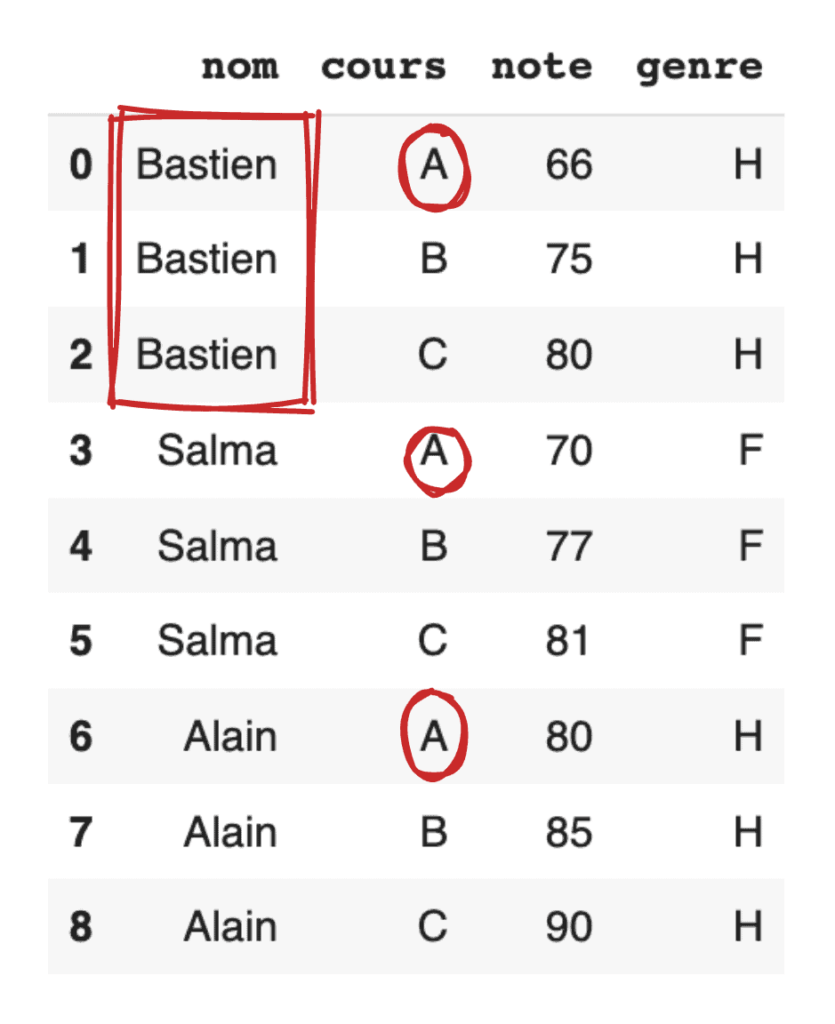
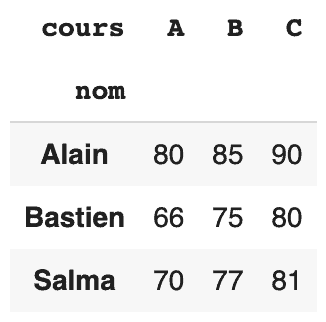
Si nous voulons afficher la note de chaque cours pour chaque étudiant, nous pouvons écrire le code ci-dessous :
df.pivot(index="nom", columns="cours", values="note")
L’index est l’axe vertical, et les colonnes sont sur l’axe horizontal, la valeur s’affichera dans chaque cellule du tableau.
Pivoter et agréger les données à l’aide de la fonction pivot_table()
La fonction pivot_table() peut gérer les valeurs dupliquées pour une paire index/colonne pivotée. Spécifiquement, vous pouvez donner à pivot_table une liste de fonctions d’agrégation en utilisant l’argument mot-clé aggfunc. L’argument aggfunc par défaut de pivot_table est numpy.mean (pour calculer la moyenne).
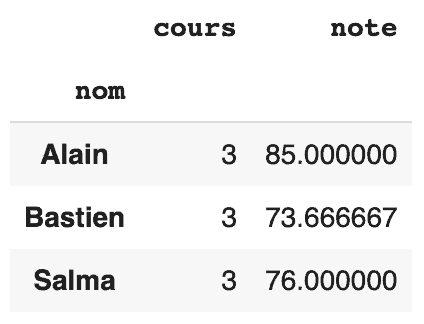
Si nous voulons compter le nombre de cours et la moyenne des notes pour chaque étudiant, nous pouvons utiliser le code ci-dessous :
pd.pivot_table(df, index="nom", values=["cours", "note"], aggfunc={"cours": "count", "note": np.mean})
L’index est l’axe vertical, et les valeurs seront les noms des colonnes, la valeur de la cellule sera le résultat de l’agrégation pour chaque colonne.
Remodeler les données en utilisant les méthodes stack() et unstack()
Si nous voulons empiler les valeurs de toutes les colonnes (horizontales) sur plusieurs lignes (verticales), nous pouvons utiliser la méthode stack() sur un DataFrame.
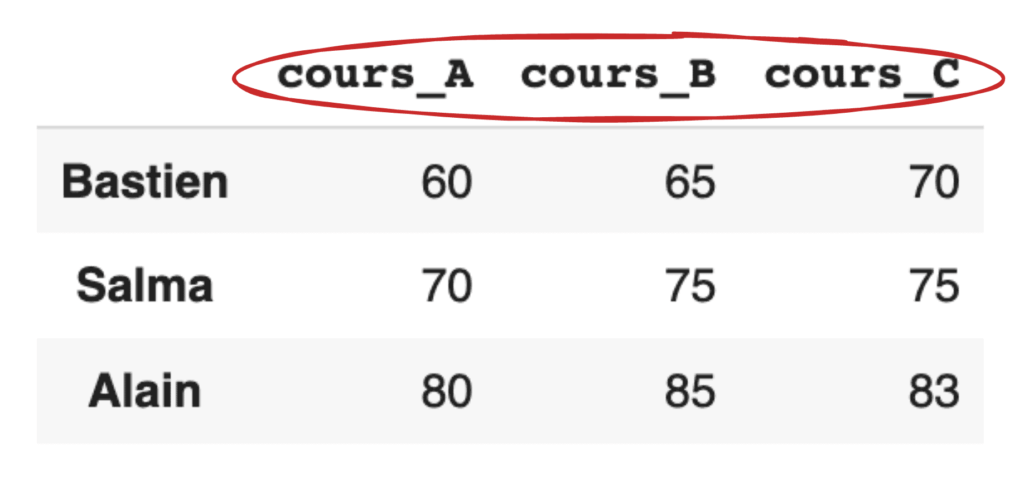
Par exemple, nous avons le DataFrame ci-dessous :
df = pd.DataFrame({
"cours_A": [60, 70,80],
"cours_B": [65, 75,85],
"cours_C": [70, 75,83],
}, index= ["Bastien", "Salma", "Alain"])
Dans le DataFrame, tous les cours d’un étudiant sont affichés en colonnes dans le sens horizontal.
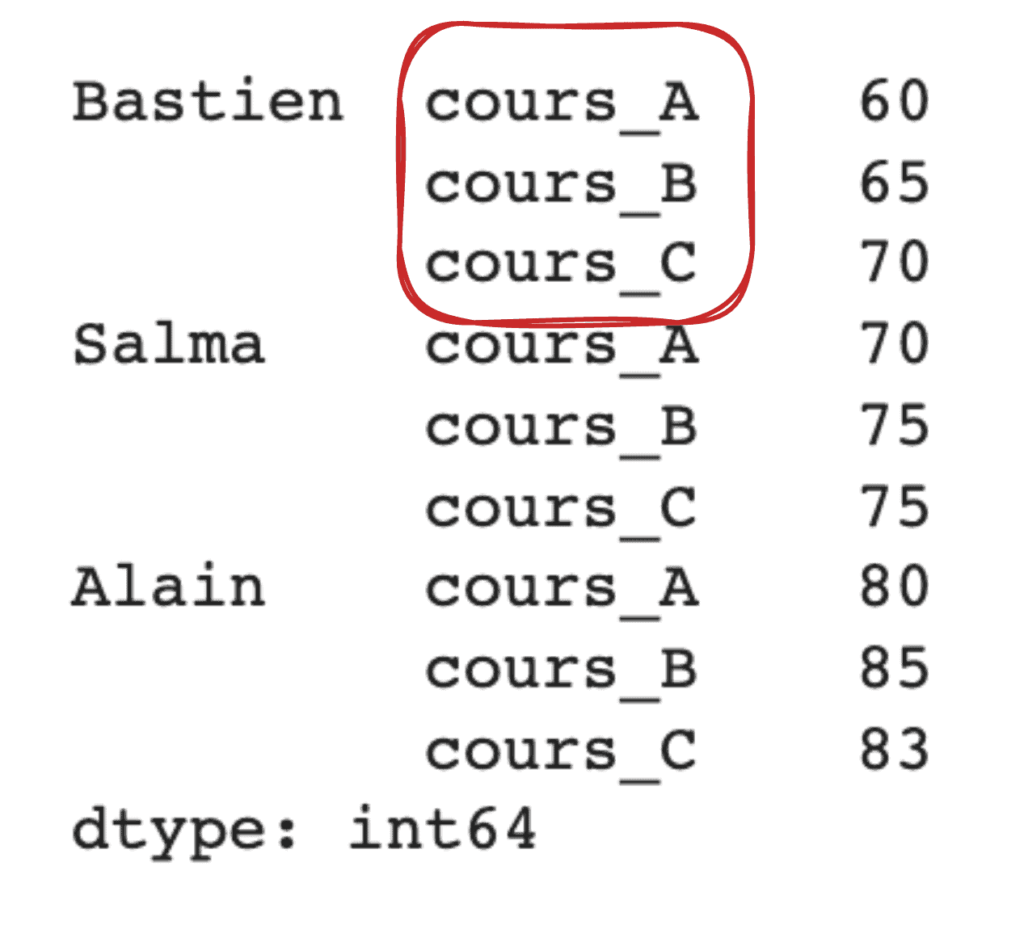
Si nous voulons empiler toutes les colonnes à la verticale en tant que rangées multiples, nous utilisons la méthode stack().
df_stack = df.stack() df_stack
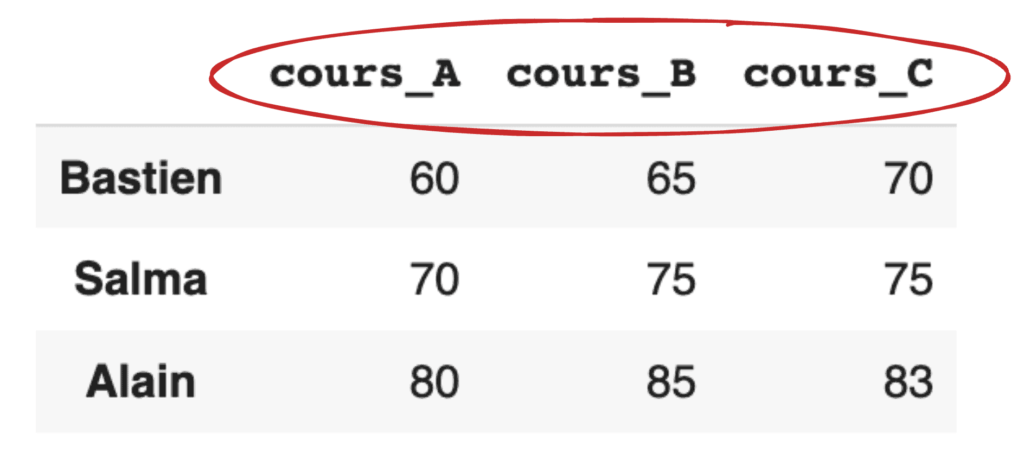
Si nous voulons étendre une colonne à plusieurs colonnes, nous pouvons utiliser la méthode unstack().
La méthode unstack() est finalement l’opération inverse de la méthode stack().
Par exemple, si nous appliquons l’opération unstack() au DataFrame df_stack ci-dessus, nous pouvons obtenir de nouveau le DataFrame d’origine df.
df_stack.unstack()
Remodeler les données en utilisant la méthode melt()
Si nous voulons conserver uniquement certaines colonnes comme éléments clés de la ligne et empiler les autres colonnes dans une seule colonne, nous pouvons utiliser la méthode melt() sur un DataFrame.
Préparons de nouveau des données :
df = pd.DataFrame({
"nom": ["bastien", "Salma", "Alain"],
"genre": ["H", "F", "H"],
"cours_A": [74, 85,90],
"cours_B": [65, 75,85],
"cours_C": [70, 75,83],
})
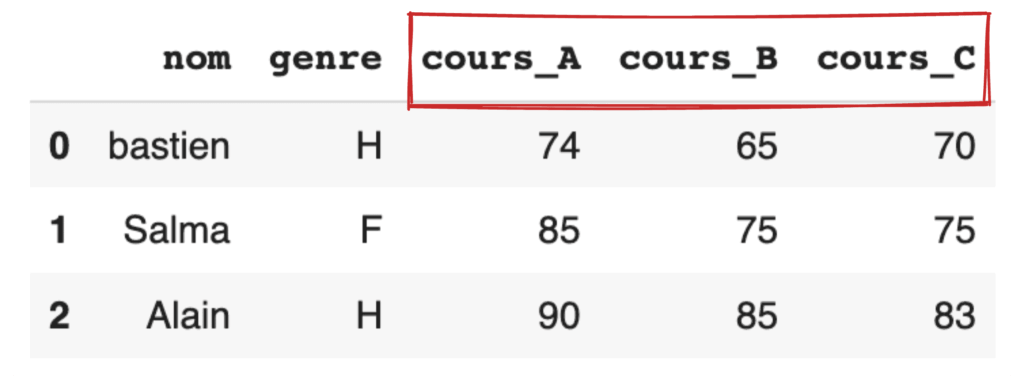
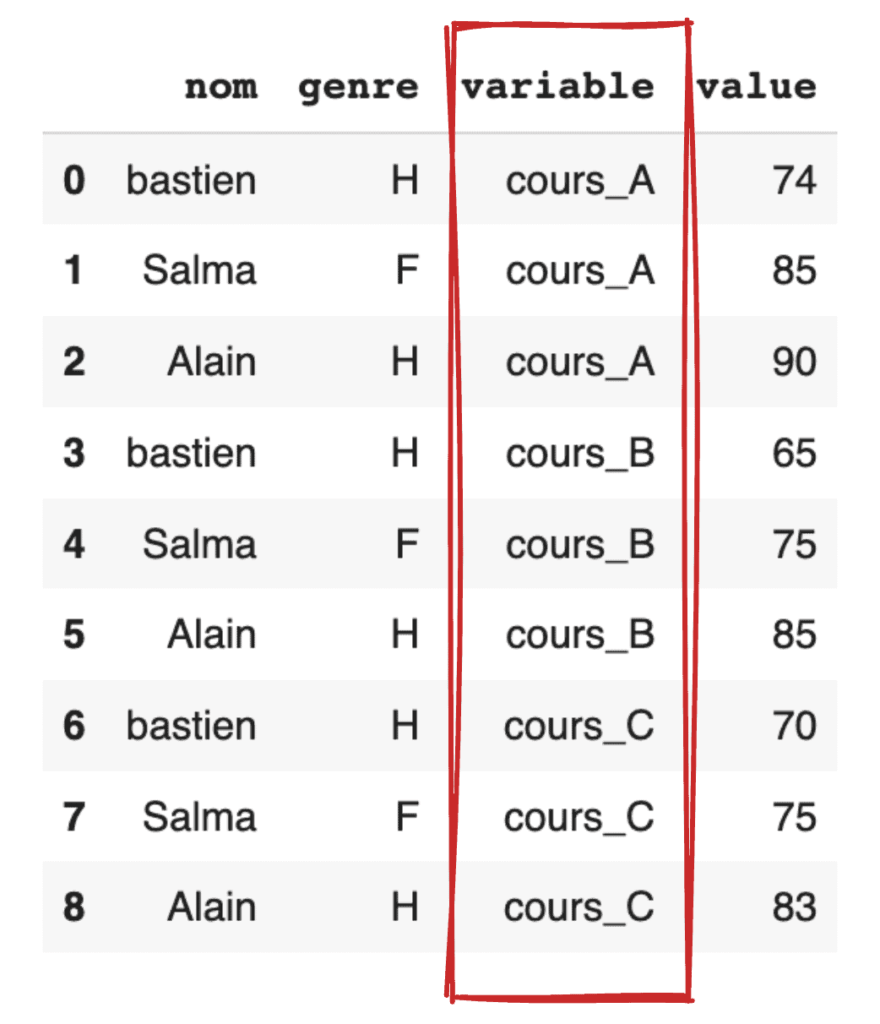
Gardons les colonnes nom et genre comme éléments clés de la ligne et empilons cours_A, cours_B et cours_C dans la colonne variable.
df.melt(id_vars=["nom", "genre"])
Conclusion
- pivot() : Remodèle (Reshape) le DataFrame en fonction d’un indiex et d’une colonne donnés, avec l’index comme axe vertical et la colonne comme axe horizontal. Les valeurs dupliquées ne sont pas supportées.
- pivot_table() : Pivotement des données comme dans Excel avec agrégation des données numériques.
- stack() : Empile plusieurs colonnes sur une colonne unique avec plusieurs lignes de données et insère un index.
- unstack() : Développe une colonne contenant plusieurs lignes en plusieurs colonnes.
- melt() : Empile plusieurs colonnes sur une colonne unique contenant plusieurs lignes et insère une colonne qui se nomme ‘variable’.
Pour aller plus loin sur Pandas, je vous recommande de lire le guide pratique du Filtrage de Données.