

Dans cet article, nous allons effectuer une exploration de données statistiques. Nous utiliserons la bibliothèque Pandas pour l’analyse de données et la bibliothèque Seaborn pour la visualisation de données. Seaborn est un formidable outil de visualisation d’un point de vue esthétique.
Seaborn utilise la bibliothèque Matplotlib. Sauf que Seaborn configure les graphiques avec des valeurs de style par défaut qui les rendent beaucoup plus beaux visuellement. Nous allons examiner un ensemble de données et je vais essayer de vous expliquer comment utiliser différentes caractéristiques. Qui sait, peut-être que nous en tirerons des hypothèses ou conclusions intéressantes !
Lorsque l’on rencontre un problème de Data Science, nous devons d’abord nous plonger dans le jeu de données (ou dataset): étudier ses propriétés, ses distributions, etc. Vous trouverez le Notebook de cette analyse ici.
Le Dataset
Pour cette analyse, j’utilise le dataset “120 ans d’histoire olympique: athlètes et résultats” que vous pouvez télécharger et lire la description en cliquant ici.
Je l’ai téléchargé gratuitement sur Kaggle, le site d’organisation de compétition Machine Learning. Ce site est génial si vous devez vous procurer un jeu de données pour essayer un nouvel algorithme d’Apprentissage Automatique, mettre à jour l’API d’une infrastructure ou tout simplement vous amuser un peu.
Je n’utiliserai que le fichier CSV ‘athlete_events’ qui répertorie tous les compétiteurs à chaque compétition olympique depuis 1900. Il contiendra le pays de naissance de chaque compétiteur, s’ils ont obtenu une médaille, etc.
Fait intéressant, la colonne des médailles est vide à 85%, de sorte qu’en moyenne, environ 15% seulement des athlètes des Jeux Olympiques obtiennent une médaille. Ajoutez à cela que certains athlètes en ont plus d’une. Il y a donc peu de médaillés parmi les participants aux JO. Cela montre la difficulté de gagner une médaille…et le mérite qu’ont ces fantastiques athlètes!
Début de l’analyse: à quoi ressemble le jeu de données?
Tout d’abord, avant d’essayer de recueillir des informations, j’aimerais avoir une meilleure connaissance du jeu de données.
Combien de données sont manquantes? Combien y a-t-il de colonnes différentes? Ce sont les questions que j’ai commencé par me poser pour commencer l’exploration.
J’utilise pour cette analyse un notebook jupyter qui est parfait pour explorer rapidement un jeu de données. Pour la suite, j’ajouterai des extraits de code pour chaque ligne pertinente que je lance afin que vous puissiez suivre.
Ce que je vais faire en premier est de charger les données avec la bibliothèque Pandas et de vérifier leur dimension :
import pandas as pd
import seaborn as sns
df = pd.read_csv('athlete_events.csv')
df.shape
#(271116, 15)
Le jeu de données possède 15 colonnes différentes et 271116 lignes entières! C’est plus de 270 000 athlètes! Je me demande combien d’athlètes différents il y a en réalité. Aussi, combien d’entre eux ont réellement gagné des médailles?
Afin de vérifier cela, je vais d’abord lister les lignes du jeu de données appelant la fonction list sur le jeu de données. Cela nous retourne de nombreuses caractéristiques intéressantes.
list(df) #['ID','Name','Sex','Age','Height','Weight','Team','NOC','Games','Year','Season','City', # 'Sport','Event','Medal']
Que pouvons-nous faire maintenant?
Nous pourrions regarder la taille (colonne Height) et le poids (colonne Weight) moyens des athlètes olympiques par sport.
Nous pourrions également voir la distribution de ces deux variables en fonction du sexe.
Nous pouvons même voir le nombre de médailles que chaque pays a reçues en séries chronologiques et voir l’ascension et le déclin des pays au cours du XXe siècle.
Les possibilités sont infinies! Mais abordons d’abord les problèmes qui fâchent: notre ensemble de données est-il complet ?
def NaN_percent(df, column_name):
row_count = df[column_name].shape[0]
empty_values = row_count - df[column_name].count()
return (100.0*empty_values)/row_count
for i in list(df):
print(i +': ' + str(NaN_percent(df,i))+'%')
'''
0% de valeurs incomplètes pour les autres colonnes.
Age: 3.49444518214%
Height: 22.193821095%
Weight: 23.191180159%
Medal: 85.3262072323% --Notez ici les 15% d'athlètes qui ont obtenu au moins une médaille
'''
En utilisant la méthode count de Pandas sur une série, je peux ainsi obtenir la quantité de lignes non vides. Cependant, en regardant la propriété shape, je peux voir le nombre total de lignes, qu’elles soient vides ou non.
Après cela, il suffit de soustraire et de diviser. Nous voyons que quatre colonnes sont incomplètes: Height, Weight, Age et Medals.
La valeur de la colonne Medals est incomplète chaque fois qu’un athlète ne remporte pas une médaille. On s’attend donc à ce qu’elle ne soit pas très remplie. Cependant, pour les colonnes Weight, Height et Age, il y a pas mal de challenges.
J’ai essayé de filtrer les lignes selon différentes années, mais l’incomplétude semble être constante dans le temps, ce qui me laisse penser que quelques pays pourraient ne pas fournir ces données sur leurs athlètes.
Analyse: quel est le problème avec les médailles ?
La première question que nous nous sommes posés sus le sujet: combien de personnes différentes ont réellement remporté une médaille depuis 1900 ?
Le code suivant répond à cette question :
total_rows = df.shape[0]
unique_athletes = len(df.Name.unique())
medal_winners = len(df[df.Medal.fillna('None')!='None'].Name.unique())
"{0} {1} {2}".format(total_rows, unique_athletes, medal_winners)
#'271116 134732 28202'
Comme vous le voyez, près de 135 000 personnes différentes ont participé aux Jeux olympiques au cours des 120 dernières années, mais seulement un peu plus de 28 000 ont remporté au moins une médaille.
C’est à peu près un sur cinq, ce qui n’est pas si mal. Ce n’est pas si optimiste si vous considérez que beaucoup de ces athlètes sont effectivement en compétition dans plus d’une catégorie.
Maintenant que nous y sommes, combien de médailles ont été réellement gagnées au cours de ces 120 années ?
# Distribution des médailles.
print(df[df.Medal.fillna('None')!='None'].Medal.value_counts())
# Nombre total de médailles (détail or, argent et bronze).
df[df.Medal.fillna('None')!='None'].shape[0]
'''
Gold 13372
Bronze 13295
Silver 13116
Total: 39783
'''
Sans surprise, la distribution des médailles est presque uniforme: presque autant de médailles d’or, d’argent et de bronze ont été gagnées.
Cependant, près de 39 000 médailles ont été attribuées, ce qui signifie que si vous appartenez à ce top 20% des athlètes qui remportent une médaille, vous êtes censé en gagner plus d’une en moyenne.
Qu’en est-il de la distribution par pays ?
Pour l’obtenir, nous allons exécuter les extraits de code suivants :
team_medal_count = df.groupby(['Team','Medal']).Medal.agg('count')
# trier par quantité
team_medal_count = team_medal_count.reset_index(name='count').sort_values(['count'], ascending=False)
#team_medal_count.head(40) pour voir les 40 premières lignes
def get_country_stats(country):
return team_medal_count[team_medal_count.Team==country]
# get_country_stats('un_pays') pour obtenir les médailles de ce pays
En utilisant cette fonction, nous pourrions obtenir le nombre de médailles de chaque type obtenu par un pays donné. En affichant les premières valeurs du DataFrame, nous pourrions voir les pays avec le plus de médailles.
Il est intéressant de noter que l’Union soviétique est toujours le deuxième pays à avoir remporté le plus de médailles depuis 1900, même si elle n’existe plus depuis près de 30 ans.
La première place est réservée aux États-Unis – toutes catégories confondues – et la troisième à l’Allemagne. J’ai aussi regardé la France (ma nation) qui se classe 6e au classement des médailles d’or.
Ecrire un script pour obtenir les différentes années auxquelles un pays a participé aux Jeux olympiques peut être un bon exercice pour vous !
Participation féminine
On peut se poser une autre question: quelle était la part féminine aux Jeux olympiques au cours du siècle? Le code suivant répond à la question :
unique_women = len(df[df.Sex=='F'].Name.unique())
unique_men = len(df[df.Sex=='M'].Name.unique())
women_medals = df[df.Sex=='F'].Medal.count()
men_medals = df[df.Sex=='M'].Medal.count()
print("{} {} {} {} ".format(unique_women, unique_men, women_medals, men_medals ))
df[df.Sex=='F'].Year.min()
# 33808 100979 11253 28530
# 1900
J’ai été surpris de voir des femmes participer aux jeux dès le début du siècle en 1900. Cependant, il y a toujours eu trois hommes aux Jeux olympiques pour une femme. Surpris par la participation des femmes aux jeux de 1900, j’ai décidé de vérifier leur nombre au fil du temps. J’ai finalement utilisé Seaborn!
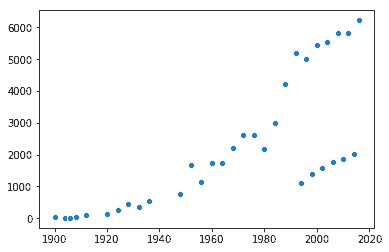
Nous pouvons constater que la participation féminine a augmenté très rapidement ces dernières décennies, en commençant de presque zéro et en atteignant des milliers.
Participation des femmes vs. participation des hommes ?
Cependant, leur taux de participation augmente-t-il plus vite que celui des hommes? Ou est-ce juste une question de population mondiale? Pour résoudre ce problème, j’ai créé ce deuxième graphique :
f_year_count = df[df.Sex=='F'].groupby('Year').agg('count').Name
m_year_count = df[df.Sex=='M'].groupby('Year').agg('count').Name
(sns.scatterplot(data= m_year_count), sns.scatterplot(data =f_year_count))
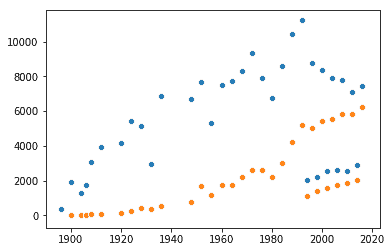
Cette fois, nous pouvons voir clairement qu’une tendance se dessine: la participation des femmes s’approche de celle des hommes au cours du temps! Une autre chose amusante émerge ici: regardez ces petits points ci-dessus, en bas à droite? Je pense que ce sont les Jeux olympiques d’hiver! Quoi qu’il en soit, la situation semble plutôt optimiste en ce qui concerne la représentation féminine, même s’il n’y a pas encore eu une seule année comptant plus de femmes que d’hommes.
Analyse annexe: Taille et Poids
J’ai passé beaucoup de temps à regarder les graphiques de taille et de poids, mais je n’ai tiré aucune conclusion intéressante.
- Les deux sont clairement distribués normalement pour la plupart des sports.
- Les hommes sont toujours plus lourds et plus grands que les femmes dans tous les sports que j’ai vérifiés.
- La seule variation intéressante semble être la répartition de chaque sexe en fonction du sport.
Si vous avez des idées intéressantes sur des éléments que vous pourriez analyser en utilisant Weight et Height, faites-le moi savoir en commentaire! Je n’ai pas assez approfondi le regroupement par sport, il est donc possible que l’on puisse en tirer quelques enseignements.
C’est tout pour cet article, j’espère que vous avez trouvé cette exploration intéressante, ou du moins vous en avez appris un peu sur la librairie Pandas et l’analyse de données.
La deuxième partie sur l’extraction de données sur les Jeux Olympiques est disponible, elle traite de la taille et du poids des athlètes en fonction du sport pratiqué.









