La Data Science est un domaine en constante évolution qui révolutionne la façon dont nous analysons et prenons des décisions basées sur des données. À l’ère de la prise de décision fondée sur les données, la bibliothèque Pandas de Python a changé la donne. Grâce à ses puissants outils de manipulation et d’analyse des données, elle est devenue un outil indispensable pour les data scientists du monde entier. Prenons 9 minutes ensemble pour comprendre les concepts clés de la Data Science avec Pandas avec une rapide manipulation de données sur un cas du monde réel.
Si tu débutes dans la Data Science ou si tu cherches à affiner tes compétences, ce tuto est fait pour toi ! Nous allons nous plonger dans le monde de Pandas et explorer les concepts clés qui t’aideront à libérer tout le potentiel de cette puissante bibliothèque. Du nettoyage et du filtrage des données à la fusion et au regroupement, nous couvrirons tout ce que tu dois savoir pour devenir un pro de Pandas.
Mais il ne s’agira pas d’un simple tuto ennuyeux. Nous utiliserons des exemples du monde réel et des morceaux de code pratique pour en faire une réelle expérience d’apprentissage engageante. Que tu sois un data scientist chevronné ou que tu débutes, ce post te permettra de maîtriser Pandas et de faire passer tes compétences en matière d’analyse de données au niveau supérieur. Alors, attache ta ceinture et viens avec moi dans le monde passionnant de la Data Science avec Pandas !
Importation de Pandas
Avant de commencer à travailler avec Pandas, nous devons importer la bibliothèque dans notre environnement Python. Nous pouvons le faire en exécutant le code suivant :
import pandas as pd
Cela permet d’importer la bibliothèque Pandas et de lui donner l’alias “pd” afin de pouvoir s’y référer facilement dans notre code.
Lecture dans un DataFrame
Un DataFrame est une structure de données bidimensionnelle de type tableau qui est utilisée pour stocker et manipuler des données. La façon la plus courante de créer un DataFrame est de lire les données à partir de différents formats de fichiers tels que CSV, Excel et les fichiers texte.
# lire un fichier CSV
csv_df = pd.read_csv('path_of_file/filename.csv')
# lire un fichier texte
text_df = pd.read_csv('path_of_file/filename.txt')
# lire un fichier excel
excel_df = pd.read_excel('path_of_file/filename.xlsx')Nous utiliserons un ensemble de données contenant les films et les émissions de télévision présents sur Netflix et nous apprendrons à utiliser Pandas pour effectuer des analyses sur cet ensemble de données. Les données peuvent être téléchargées sur Kaggle.
J’ai téléchargé les jeux de données (titles.csv et credits.csv) et les ai placés dans le même dossier que celui où j’exécute le code python.
Voici le notebook de l’ensemble du code python de ce tuto.
Lisons les jeux de données :
netflix_titles = pd.read_csv('titles.csv')
netflix_credits = pd.read_csv('credits.csv')Observation des données
Une fois que nous avons le DataFrame, nous pouvons utiliser différentes méthodes pour visualiser les données. Par exemple, nous pouvons utiliser la méthode head() pour afficher les premières lignes du DataFrame :
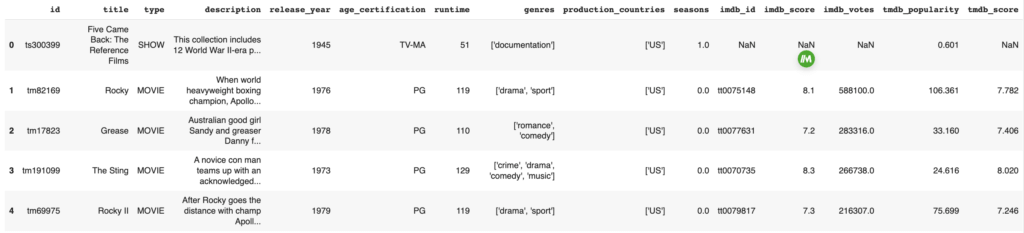
netflix_titles.head()

Les données relatives aux titres contiennent des informations telles que le nom des films ou des émissions de télévision, l’année de sortie, les genres, le numéro de la saison, le classement IMDB, etc.
netflix_credits.head()
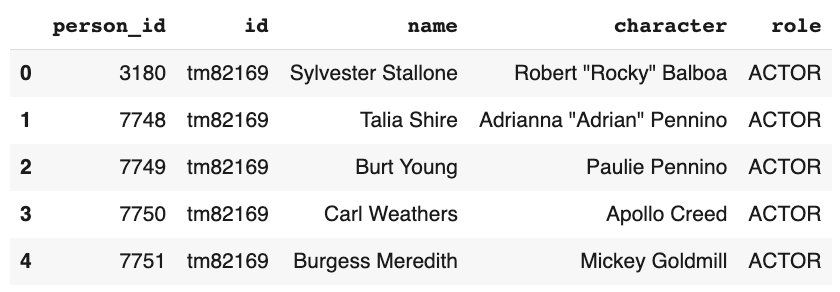
Les données du générique contiennent des informations sur l’acteur et le réalisateur qui ont été associés au film.
Sélection de données
Nous pouvons sélectionner des lignes ou des colonnes spécifiques d’un DataFrame en utilisant l’indexation (en utilisant des crochets). Par exemple, nous pouvons sélectionner la colonne ‘description’ comme suit :
netflix_titles['description']
0 This collection includes 12 World War II-era p...
1 When world heavyweight boxing champion, Apollo...
2 Australian good girl Sandy and greaser Danny f...
3 A novice con man teams up with an acknowledged...
4 After Rocky goes the distance with champ Apoll...
...
6132 Two young boys must work together to stop robb...
6133 ‘Theatre is my life,’ Yıldız Kenter admits in ...
6134 This Queen of Comedy shines as she takes the s...
6135 The lives of three teenagers and a hit-man int...
6136 A story about young boy sultan, 11 years old l...
Name: description, Length: 6137, dtype: objectIl est également possible de sélectionner plusieurs colonnes, ce qui renvoie un DataFrame. Il est possible d’accéder à plusieurs colonnes à l’aide de doubles crochets.
netflix_titles[['title','description']]

Filtrage des données
Nous pouvons filtrer les données d’un DataFrame en fonction de certaines conditions. Par exemple, nous pouvons filtrer les films/expositions dont la note IMDB est supérieure à 8.
netflix_titles[netflix_titles['imdb_score']>8]
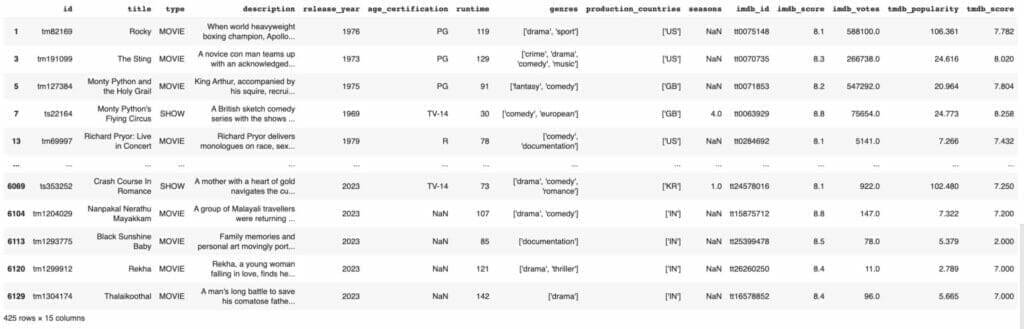
Cette opération renvoie un nouveau DataFrame contenant les lignes dont la note IMDB est supérieure à 8.
Aggrégation de données
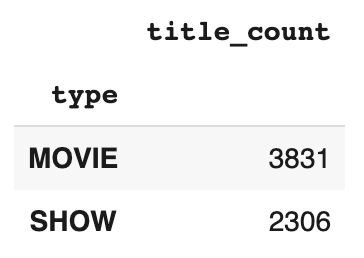
Nous pouvons utiliser la méthode groupby() pour regrouper les données d’un DataFrame par une ou plusieurs colonnes, puis appliquer des fonctions d’agrégation à chaque groupe. Par exemple, nous pouvons regrouper les données par “type” et calculer le nombre de titres pour chaque type (film ou spectacle) comme suit :
netflix_titles.groupby(['type']).agg(title_count = ('title','count'))Cette méthode renvoie un objet de type DataFrame contenant le nombre de titres pour chaque type.
Gestion des valeurs manquantes
Nous observons souvent des valeurs manquantes ou nulles dans nos DataFrame en raison d’erreurs de saisie, de non-réponses, d’erreurs de traitement des données, de causes naturelles, etc.
Pandas fournit plusieurs méthodes pour gérer les valeurs manquantes dans un DataFrame, telles que dropna(), fillna(). Nous pouvons supprimer les lignes contenant des valeurs manquantes à l’aide de la méthode dropna(). Nous pouvons remplir les valeurs manquantes avec une constante en utilisant la méthode fillna().
Par exemple, dans notre ensemble de données, la colonne ‘seasons’ comporte des valeurs manquantes (null) correspondant aux films, car les films n’ont pas de saisons en général. Nous pouvons remplir ces valeurs null avec 0.
netflix_titles['seasons'] = netflix_titles['seasons'].fillna(0) netflix_titles.head()
Tri des données
Nous pouvons trier les données d’un DataFrame sur la base d’une ou plusieurs colonnes à l’aide de la méthode sort_values().
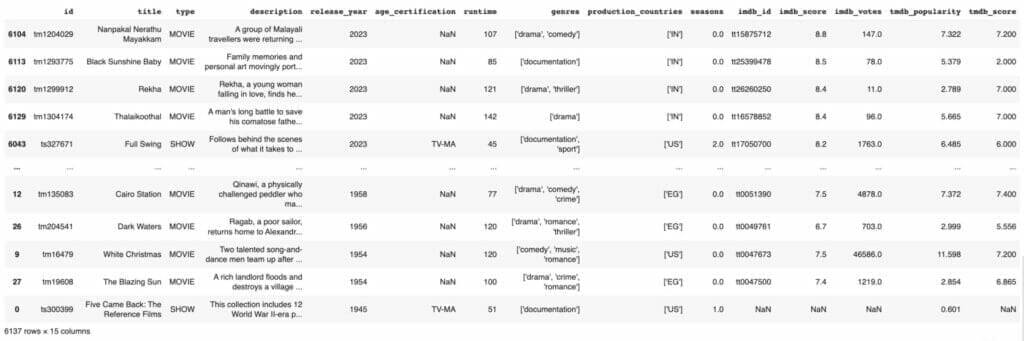
# trier les données en fonction de l'année de publication
netflix_titles.sort_values('release_year')# trier le DataFrame sur la base de l'année de sortie et du classement IMDB, tous deux dans l'ordre décroissant netflix_titles.sort_values(['release_year', 'imdb_score'], ascending=[False, False])
Fusion et assemblage de données
Pandas nous permet de fusionner et de joindre plusieurs DataFrames sur la base des colonnes communes en utilisant des méthodes telles que merge(), join() et concat().
Dans notre jeu de données Netflix, nous pouvons joindre les données du titre et les données du générique pour obtenir les deux informations dans le même DataFrame.
# fusionner les DataFrames sur la base de la colonne 'id'. joined_df = pd.merge(netflix_titles, netflix_credits, on = 'id', how = 'inner') joined_df.head()

Application de fonctions
Nous pouvons appliquer des fonctions à une ou plusieurs colonnes d’un DataFrame à l’aide de méthodes telles que apply() et lambda.
Par exemple, dans le code ci-dessous, nous convertissons la durée de diffusion des films/émissions de minutes en heures.
# convertir la durée d'exécution en heures en utilisant apply et la fonction lambda joined_df['runtime'] = joined_df['runtime'].apply(lambda x: x/60) joined_df.head()

Visualisation de données
Pandas fournit une variété de fonctions intégrées pour créer des graphiques et des visualisations à partir d’objets DataFrame. Ces fonctions s’appuient sur la célèbre bibliothèque matplotlib, ce qui facilite la création de visualisations personnalisées.
Par exemple, dans le code ci-dessous, nous étudions la distribution du nombre d’acteurs/réalisateurs dans les films/expositions.
import matplotlib.pyplot as plt
role_count = joined_df.groupby('id').agg(count_role = ('role','count')).reset_index()
plt.hist(role_count['count_role'], bins=15)
plt.xlabel("Nombre d'acteurs et de réalisateurs")
plt.ylabel("# Titres")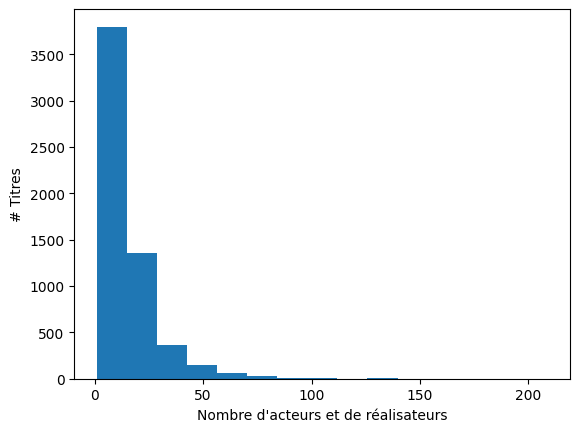
Travail avec des dates et heures
Nous travaillons souvent avec des colonnes de date et d’heure pour effectuer des analyses à différentes périodes. Il est donc important de comprendre comment travailler avec la date et l’heure dans pandas.
Définir la colonne date comme index du DataFrame :
dates = pd.date_range('2023-01-01', periods=10)
df = pd.DataFrame({'A': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 'B': [11, 12, 13, 14, 15, 16, 17, 18, 19, 20]}, index=dates)
print(df)A B 2023-01-01 1 11 2023-01-02 2 12 2023-01-03 3 13 2023-01-04 4 14 2023-01-05 5 15 2023-01-06 6 16 2023-01-07 7 17 2023-01-08 8 18 2023-01-09 9 19 2023-01-10 10 20
Dans cet exemple, nous créons un DataFrame avec des dates comme index en utilisant la méthode date_range(). Les dates commencent le 1er janvier 2022 et vont jusqu’au 10 janvier 2023, avec 10 périodes au total. Nous ajoutons également deux colonnes, ‘A’ et ‘B’, avec des valeurs aléatoires.
Nous pouvons ensuite travailler avec les dates et les heures de ce DataFrame à l’aide de diverses méthodes fournies par Pandas. Par exemple, nous pouvons sélectionner un sous-ensemble du DataFrame pour une plage de dates spécifique :
# sélectionner un sous-ensemble de DataFrame pour une plage de dates spécifique subset = df['2023-01-03':'2023-01-07'] print(subset)
A B 2023-01-03 3 13 2023-01-04 4 14 2023-01-05 5 15 2023-01-06 6 16 2023-01-07 7 17
Nous pouvons également rééchantillonner les données du DataFrame sur la base d’un intervalle de temps spécifique, par exemple quotidien ou hebdomadaire :
# rééchantillonner les données sur la base d'un intervalle de temps
daily = df.resample('D').sum()
print(daily)
weekly = df.resample('W').mean()
print(weekly) A B
2023-01-01 1 11
2023-01-02 2 12
2023-01-03 3 13
2023-01-04 4 14
2023-01-05 5 15
2023-01-06 6 16
2023-01-07 7 17
2023-01-08 8 18
2023-01-09 9 19
2023-01-10 10 20
A B
2023-01-01 1.0 11.0
2023-01-08 5.0 15.0
2023-01-15 9.5 19.5Conclusion de la Data Science avec Pandas
Dans ce post, nous avons abordé quelques concepts clés de la Data Science avec Pandas. Nous avons appris à importer Pandas, à créer un DataFrame, à visualiser des données, à sélectionner des données, à filtrer des données et à agréger des données. Ces concepts ne sont que la partie émergée de l’iceberg, et tu peux bien entendu faire beaucoup plus avec Pandas. Cependant, la compréhension de ces concepts est essentielle si tu veux travailler avec des données en Python.
J’espère que tu as appris quelque chose de nouveau grâce à ce tuto 🙂
Pour aller plus loin dans la Data Science avec Pandas (et Python), tu peux suivre le programme Python pour la Data Science.