Explorons ensemble des cas d’utilisation de la Data Science avec l’API GPT-3 avec Python ! On va lui poser des questions pointues sur le Machine Learning et le Deep Learning, on va également lui demander de nous générer du code Python pour effectuer des tâches de Data Science. Et tout ça, en écrivant nous-même du code Python, promis ça va être fun !
Commençons par parler de GPT-3…
GPT-3 est un modèle de Machine Learning du langage humain qui a été publié par Open AI fin 2022. Il a attiré l’attention des médias pour sa capacité à écrire des essais, des chansons, de la poésie, des images et même du code ! L’utilisation de l’outil est gratuite.
GPT-3 est un type de modèle de Machine Learning appelé transformateur. Plus précisément, il s’agit d’une extension du Generative Pre-training Transformer, d’où “GPT”. L’architecture du transformateur utilise l’auto-attention et l’apprentissage par renforcement pour modéliser du texte conversationnel. En général, elle fonctionne en traitant le texte un mot à la fois et elle utilise les mots précédents pour prédire le mot suivant dans une séquence. Tu vois l’idée.
Outre les réponses basiques sur des sujets pour lesquels il existe un grand nombre de contenus précis sur le Web, j’ai vu de nombreuses autres applications intéressantes de cet outil. Par exemple, un développeur a utilisé GPT-3 pour orchestrer des services cloud afin de réaliser des tâches complexes. D’autres utilisateurs ont généré des scripts python et SQL, et tout plein d’autres langages de programmation, avec GPT-3. Les applications potentielles de GPT-3 sont nombreuses dans pratiquement tous les domaines.
Bien que GPT-3 ait ses limites, son large éventail d’applications est impressionnant. J’ai pensé qu’il serait amusant de poser des questions à GPT-3 au sujet de la Data Science et du Machine Learning afin de voir si elles peuvent compléter certains workflow en Data Science.
Pour commencer, nous allons générer du texte relatif à la Data science à partir de quelques questions très simples. Une fois que nous serons un peu plus familiarisés avec l’outil, nous verrons si nous pouvons poser des questions qui peuvent nous aider à réaliser certaines tâches de Data Science.
Une autre application intéressante consiste à utiliser GPT-3 pour décider du modèle ML à utiliser pour une application particulière. Enfin, nous pouvons essayer d’utiliser GPT-3 pour écrire du code python pour certaines tâches de Data Science. Par exemple, nous verrons si nous pouvons l’utiliser pour écrire du code qui génère des données artificielles pour des cas d’utilisation particuliers.
Pour cette démonstration de GPT-3, voici le notebook Google Colab que j’ai utilisé permettant de reproduire le code chez toi !
Code GPT-3 avec Python
Mise en place de GPT-3
Pour commencer, installons OpenAI en utilisant pip dans la première cellule du notebook :
!pip install openai !pip install catboost
Importation OpenAI
Commençons par importer la bibliothèque OpenAI et par stocker notre clé dans l’attribut api_key de notre objet openAI :
import openai openai.api_key = "ta-clé-openai
Tu peux demander ta clé openAI sur leur site web.
Quelques questions simples sur la Data Science et le Machine Learning en Python
Maintenant, testons le code avec une question très basique, par exemple “A-t-on besoin de Python pour la Data Science et le Machine Learning ?”. Regardons ce que nous dit GPT-3 :
completion = openai.Completion.create(engine="text-davinci-003", prompt="A-t-on besoin de Python pour la Data Science et le Machine Learning ?", max_tokens=1000) print(completion.choices[0]['text'])
La réponse est sans appel :
Oui, Python est l’une des principales technologies utilisées dans la data science et le machine learning. C’est un des outils les plus populaires pour la programmation et l’analyse des données. Python est utilisé pour créer des algorithmes prédictifs puissants pour le traitement des données et la prise de décisions, ainsi que pour des applications de visualisation et de manipulation des données. Il est également utilisé pour créer des systèmes d’apprentissage par machine et des systèmes d’intelligence artificielle qui sont utiles pour le traitement des données et l’analyse prédictive.
Pour apprendre Python appliqué à la Data Science et au Machine Learning, j’ai un programme complet disponible.
Ensuite, posons des questions sur certaines bibliothèques python bien connues. Si nous demandons “qu’est-ce que la bibliothèque Pandas ?”, GPT-3 donnera une réponse :
completion = openai.Completion.create(engine="text-davinci-003", prompt="Qu'est-ce que la bibliothèque pandas ?", max_tokens=1000) print(completion.choices[0]['text'])
La bibliothèque Pandas est une bibliothèque open source Python qui fournit des structures de données et des outils d’analyse destinés à rendre plus facile le traitement et l’analyse numérique des données. Elle offre une variété de fonctionnalités pour manipuler, filtrer, trier et fusionner des données facilement, comme la sélection, l’ajout et la suppression d’informations. Elle peut également être utilisée pour les diagrammes, la visualisation de données, l’analyse descriptive et prédictive et bien d’autres choses encore.
Nous pouvons même poser des questions plus spécifiques telles que “quels sont les cas d’utilisation courants de Pandas ?”. Il donne des réponses sensées énumérant le traitement des données, la visualisation des données, l’agrégation de données et l’analyse des séries temporelles :
completion = openai.Completion.create(engine="text-davinci-003", prompt="Quels sont les cas d'utilisation courants de Pandas ? (donne moi 10 points précis)", max_tokens=1000) print(completion.choices[0]['text'])
1. Analyse de données et préparation des données, notamment le nettoyage et l’agrégation. 2. Manipulation des données, notamment le filtrage et le tri. 3. Transformations des données, telles que le calcul de statistiques d'agrégation. 4. Visualisation de données complexes et génération de rapports. 5. Export des données dans des tableaux électroniques ou des bases de données. 6. Intégration avec d'autres bibliothèques Python pour le traitement plus approfondi des données. 7. Création et manipulation des dates et des heures. 8. Analyse des données temporelles. 9. Fusion de données, fusion par index et jointures. 10. Exportation de tableaux pivot et de tableaux croisés dynamiques.
Demandons “quelles sont les bibliothèques de Deep Learning les plus courantes ?”:
completion = openai.Completion.create(engine="text-davinci-003", prompt="Quelles sont les bibliothèques de Deep Learning les plus courantes ?", max_tokens=240) print(completion.choices[0]['text'])
Les bibliothèques de deep learning les plus courantes sont : - TensorFlow - Keras - PyTorch - Caffe - Theano - Microsoft Cognitive Toolkit (CNTK) - Apache MXNet - Deeplearning4j - Chainer - Caffe2
Nous pouvons même demander quelque chose comme “Qu’est-ce qu’un réseau de neurones de Deep Learning ?” :
completion = openai.Completion.create(engine="text-davinci-003", prompt="Qu'est-ce qu'un réseau de neurones de Deep Learning ?", max_tokens=1000) print(completion.choices[0]['text'])
Un réseau de neurones de deep learning est une forme d’intelligence artificielle qui imite le fonctionnement du cerveau humain en créant des “réseaux” de neurones artificiels interconnectés qui communiquent entre eux pour apprendre et prendre des décisions. Ces réseaux, basés sur des algorithmes de calcul d’apprentissage profond (deep learning), peuvent être très adaptables et s’utiliser dans des domaines très divers, comme le traitement du langage naturel, les réseaux sociaux ou la recherche d’images.
Feature engineering
Un autre cas d’utilisation intéressant pour GPT-3 est son utilisation comme aide pour guider le travail de Data science. Par exemple, GPT-3 peut-il donner des idées sur les transformations de Features qui peuvent améliorer les performances du modèle ? Demandons à GPT-3 :
completion = openai.Completion.create(engine="text-davinci-003", prompt="Donne-moi quelques idées sur les transformations de Features qui peuvent améliorer les performances d'un modèle de Machine Learning ou Deep Learning.", max_tokens=1000) print(completion.choices[0]['text'])
- Catégorisation des variables : convertir les variables continues en catégories afin de les représenter sous forme de nombres entiers ou de noms.
- Réduction de Dimensionnalité : Utilisation de techniques comme l’ACP (Analyse en Composantes Principales) et LDA (Discriminant Linéaire Discriminant) pour réduire la dimension des variables et ainsi améliorer les performances du modèle.
- Normalisation des variables : Permet de mettre toutes les variables dans la même ligne de valeurs afin de les rendre plus compatibles pour l’apprentissage.
- Combiner et transformer des variables : Combiner et transformer des variables entre elles pour créer de nouvelles variables qui peuvent être plus prédictives.
- Régularisation des variables : Utilisation de la régularisation pour limiter les paramètres en les réduisant à des valeurs plus petites et plus stables.
- Ajouter un bruit aléatoire aux données : L’ajout de bruit aléatoire aux données peut aider à améliorer la performance en créant une distribution plus réaliste et plus riche qui se reflète dans les résultats.
Nous constatons qu’il donne quelques bonnes suggestions de transformation de fonctionnalités ainsi que des explications sur chacune d’entre elles.
Voyons si nous pouvons aller encore plus loin. Demandons-lui d’écrire du code python dans lequel il effectue une normalisation :
completion = openai.Completion.create(engine="text-davinci-003", prompt="Écris un exemple de code python qui effectue de la normalisation de données", max_tokens=1000) print(completion.choices[0]['text'])
Essayons le code fourni. parGPT-3 🙂
Copions et collons ceci dans une nouvelle cellule et exécutons-le :
# Exemple de code python d'un algorithme de normalisation import numpy as np # Données à normaliser data = np.array([1.0, 2.0, 3.0, 4.0, 5.0]) # Calcul de la moyenne des données mean = np.mean(data) # Calcul de l'écart type des données std_dev = np.std(data) # Normalisation des données normalized_data = (data - mean) / std_dev #Vérification du résultat print(normalized_data)
[-1.41421356 -0.70710678 0. 0.70710678 1.41421356]
Sélection du modèle
Un autre cas d’utilisation cool : la sélection de modèles. Voyons si GPT-3 peut nous guider dans la sélection de nos modèles de Machine Learning. Demandons “Comment puis-je sélectionner un modèle de série temporelle ?”.
completion = openai.Completion.create(engine="text-davinci-003", prompt="Comment puis-je sélectionner un modèle de série temporelle ?", max_tokens=1000) print(completion.choices[0]['text'])
Pour sélectionner un modèle de série temporelle, vous devez d’abord examiner les données pour déterminer la tendance, le comportement saisonnier et les anomalies. Ensuite, vous devrez choisir le modèle qui mieux se convenir aux caractéristiques de vos données. Les modèles populaires incluent les régressions Linéaire, Exponentiel et Autorégressive. Une fois que vous aurez sélectionné le modèle approprié, vous devrez l’évaluer en utilisant des métriques telles que le coefficient de corrélation, l’erreur quadratique moyenne et l’erreur relative.
Les réponses sont correctes, des vérifications de la stationnarité, de la saisonnalité, des tendances et l’évaluation des performances du modèle. Posons une question plus spécifique comme “Quand utiliser ARIMA vs Prophète de FB ?” :
completion = openai.Completion.create(engine="text-davinci-003", prompt="Quand utiliser ARIMA vs prophète FB ?", max_tokens=1000) print(completion.choices[0]['text'])
ARIMA est une technique de prévision des séries chronologiques utilisée pour prédire des valeurs futures basées sur des informations passées. Elle est utile pour prévoir des informations comme le climat et les stocks, car elle permet d’utiliser des informations passées pour créer des prédictions futures précises.
Par contraste, Prophet FB est un modèle de prévision de séries chronologiques basé sur les séries temporelles. Il est principalement utilisé pour la prévision à court terme et les données à haute fréquence. Il est particulièrement bon pour les données sporadiques et saisonnières et peut prendre en compte des informations externes telles que les jours fériés, les points de données non observés et les régressions non linéaires. Il est utile pour prédire des informations telles que les ventes et la demande de produits.
En résumé, ARIMA est un outil de prévision de séries chronologiques plus général qui est utile lorsque des informations détaillées sont disponibles, tandis que Prophet FB est utile pour la prévision à court terme et permet de prendre en compte des informations externes. Chacune des deux méthodes est très précise et peut être utilisée pour obtenir des prédictions précises et fiables à des fins différentes.
Génération de données synthétiques
Peut-on utiliser GPT-3 pour générer des données synthétiques ? C’est ce que nous allons voir ! Nous allons examiner des exemples bien connus de données de réadmission dans le secteur de la santé et de données de transaction financière ou commerciale.
Données de réadmission de patients à des soins de santé
Demandons à GPT-3 d’écrire un exemple de code python qui génère des données synthétiques de réadmission aux soins de santé stockées dans un DataFrame :
completion = openai.Completion.create(engine="text-davinci-003", prompt="Donne-moi un exemple de code python qui génère des données synthétiques sur les réadmissions de patients dans les services de santé. Stocke-moi ces données dans un DataFrame.", max_tokens=1000) print(completion.choices[0]['text'])
Testons le immédiatement :
# Importation des modules nécessaires
import pandas as pd
import numpy as np
# Création de la liste de données
data_list = [['001', 'John', 'Admitted', '2020-01-01', '2020-01-19'], ['002', 'Sara', 'Admitted', '2020-03-10', '2020-04-19'],
['003', 'Grace', 'Not Admitted', '2020-05-01', '2020-05-09'], ['004', 'Jack', 'Admitted', '2020-06-20', '2020-07-09']]
# Conversion de la liste en DataFrame
readmission_data = pd.DataFrame(data_list, columns=["PatientID", "Name", "Status", "Admission Date", "Discharge Date" ])
# Génération aléatoire de données de retour
np.random.seed(42)
readmission_data['Readmitted'] = np.random.choice(a=['Yes', 'No'], size=len(readmission_data))
# Affichage des données
readmission_data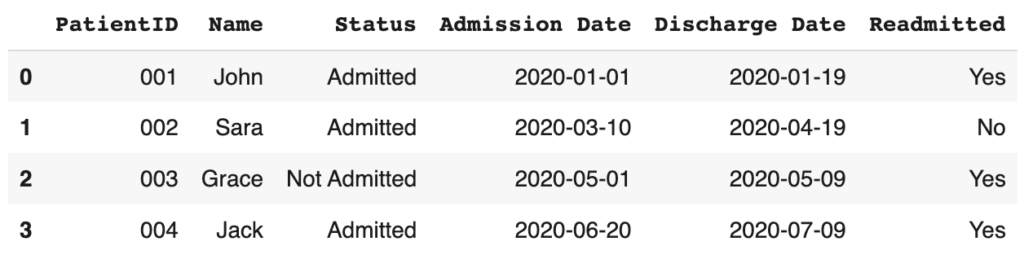
Voyons si nous pouvons lui demander de construire un modèle de classification sur ces données synthétiques qui prédit la réadmission et évalue la performance. L’invite sera la suivante :
completion = openai.Completion.create(engine="text-davinci-003", prompt="Donne-moi un exemple de code python qui génère des données synthétiques sur les réadmissions de patients dans les services de santé, stockées dans un DataFrame. À partir de ces données, écris-moi un code Python qui construit un modèle catboost qui prédit les résultats des réadmissions. Écris également du code pour calculer et imprimer les performances", max_tokens=3000) print(completion.choices[0]['text'])
Et copions et exécutons ce code :
import numpy as np
np.random.seed(1)
# Définir une fonction pour générer des données
def generateData(num_examples):
# Définir les entrées
x_data = np.random.rand(num_examples, 3)
# Définir les étiquettes
y_labels = np.random.randint(2, size=num_examples)
return x_data, y_labels
# Générer nos données
x_data, y_labels = generateData(100)
# Code Python pour construire le modèle de classification:
from sklearn.svm import SVC
# Instancier le modèle de classification
model = SVC()
# Entraîner le modèle avec les données et les étiquettes
model.fit(x_data, y_labels)
# Code pour calculer et imprimer les performances du modèle:
from sklearn.metrics import accuracy_score
# Prédire les résultats avec le jeu de données et les étiquettes
predicted_labels = model.predict(x_data)
# Calculer la précision du modèle
performance = accuracy_score(y_labels, predicted_labels)
# Imprimer les résultats
print(f"Le modèle a une précision de {performance*100:.2f}%")Le modèle a une précision de 68.00%
Données de transaction
Demandons à GPT-3 d’écrire un exemple de code python qui génère des données de transaction synthétiques stockées dans un DataFrame :
completion = openai.Completion.create(engine="text-davinci-003", prompt="Écrire un exemple de code python qui génère des données de transaction synthétiques stockées dans un DataFrame. Y inclure le nom du client, l'ID du client et de la trasaction, la date et le montant de la transaction.", max_tokens=1000) print(completion.choices[0]['text'])
Copions ce code et exécutons-le dans une nouvelle cellule :
import pandas as pd
data = {'client_name' : ['John', 'Anna', 'Mark', 'Emily', 'Paul'],
'client_id' : [1, 2, 3, 4, 5],
'transaction_id': [101, 102, 103, 104, 105],
'date' : ['21/05/2020', '25/05/2020', '28/05/2020', '30/05/2020', '02/06/2020'],
'amount': [150.25, 400.31, 2000.56, 543.09, 12.50]
}
df = pd.DataFrame(data)
df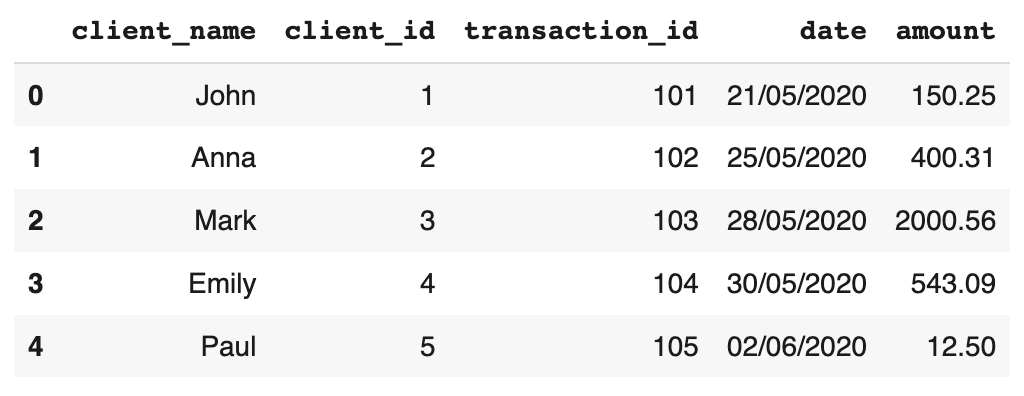
Assez impressionnant !
Datasets open source
Une autre application consiste à demander à GPT-3 des ensembles de données publiques. Demandons à GPT-3 de lister quelques ensembles de données publiques :
completion = openai.Completion.create(engine="text-davinci-003", prompt="liste-moi 10 bons sites pour trouver des ensembles de données publiques", max_tokens=1000) print(completion.choices[0]['text'])
- 1. Kaggle Datasets
- 2. UCI Machine Learning Repository
- 3. FiveThirtyEight
- 4. Reddit: r/datasets
- 5. Data.gov
- 6. Awesome-Public-Datasets Github
- 7. Google Dataset Search
- 8. The World Bank
- 9. Harvard Dataverse
- 10. Amazon Web Services Open Data Registry
Mine de rien, de nombreux sites proposés par GPT-3 font parti de ma liste des meilleurs sites de datasets pour nos projets de Data science.
Questions en Machine Learning
Pour notre dernier exemple, nous allons voir si GPT-3 peut nous aider à formuler des problèmes de Machine Learning. Nous examinerons la formulation des “cas d’utilisation”
Posons la question suivante : “Quels sont les cas d’utilisation émergents du Machine Learning dans les médias sociaux ?”.
completion = openai.Completion.create(engine="text-davinci-003", prompt="Quels sont les cas d'utilisation émergents du Machine Learning dans les médias sociaux ?", max_tokens=1000, temperature=0) print(completion.choices[0]['text'])
1. Détection de contenu inapproprié : Les réseaux sociaux peuvent utiliser des algorithmes de Machine Learning pour détecter automatiquement le contenu inapproprié et le supprimer.
2. Ciblage publicitaire : Les réseaux sociaux peuvent utiliser des algorithmes de Machine Learning pour cibler les publicités en fonction des intérêts et des préférences des utilisateurs.
3. Analyse des tendances : Les réseaux sociaux peuvent utiliser des algorithmes de Machine Learning pour analyser les tendances et les préférences des utilisateurs et ainsi mieux cibler leurs contenus.
4. Détection de la fraude : Les réseaux sociaux peuvent utiliser des algorithmes de Machine Learning pour détecter les comportements suspects et prévenir la fraude.
5. Analyse des sentiments : Les réseaux sociaux peuvent utiliser des algorithmes de Machine Learning pour analyser les sentiments des utilisateurs et ainsi mieux comprendre leurs préférences et leurs intérêts.
Voyons également la réponse pour les soins de santé :
completion = openai.Completion.create(engine="text-davinci-003", prompt="Quels sont les nouveaux cas d'utilisation du Machine Learning dans le secteur des soins de santé ?", max_tokens=1000, temperature=0) print(completion.choices[0]['text'])
1. Diagnostic précoce des maladies: Les algorithmes d’apprentissage automatique peuvent être utilisés pour analyser les données médicales et les symptômes pour détecter les maladies précocement.
2. Prédiction des réponses aux médicaments: Les algorithmes d’apprentissage automatique peuvent être utilisés pour prédire la réponse d’un patient à un médicament donné en fonction de ses antécédents médicaux et de ses caractéristiques génétiques.
3. Surveillance des patients à distance: Les algorithmes d’apprentissage automatique peuvent être utilisés pour surveiller les patients à distance et détecter les signes de détérioration de leur état de santé.
4. Prédiction des épidémies: Les algorithmes d’apprentissage automatique peuvent être utilisés pour prédire les épidémies et aider à prendre des mesures préventives.
5. Amélioration de la qualité des soins: Les algorithmes d’apprentissage automatique peuvent être utilisés pour améliorer la qualité des soins en analysant les données médicales et en identifiant les pratiques médicales les plus efficaces.
Conclusions GPT-3 avec Python
Dans cet article, nous avons discuté de la façon d’utiliser GPT-3 pour une variété de tâches de Data Science et de Machine Learning. Tout d’abord, nous avons donné à l’API quelques questions simples liées aux bibliothèques python, au Feature Engineering et à la sélection de modèles. Ensuite, nous avons montré comment utiliser l’API GPT-3 pour générer des données synthétiques sur les soins de santé et les transactions. Nous avons également pu générer une requête pour construire un modèle de réadmission à partir de données synthétiques. Nous avons ensuite interrogé l’API pour obtenir des informations sur des ensembles de données accessibles en open source. Enfin, nous avons interrogé l’API sur les cas d’utilisation émergents du Machine Learning.
J’espère que vous avez apprécié cet article. N’hésite pas à télécharger le code et à voir si tu peux intégrer GPT-3 dans ton workflow de Data science.