

À l’université, SQL est considéré comme un langage très facile à apprendre. En gros, il “suffit” juste de connaître SELECT, FROM, GROUP BY et WHERE.
Facile, hein ?
C’est pourquoi j’ai envie de vous partager 3 pratiques SQL très efficaces !
SQL a en effet une courbe d’apprentissage rapide, il a été conçu comme un langage de programmation de haut niveau pour interroger toute base de données relationnelle. On parle d’ailleurs de language de requête.
Aujourd’hui, tout entrepôt de données (warehouse) ou framework Bigdata comprend un connecteur SQL.
Cependant, SQL peut s’avérer délicat, surtout lorsque vous passez de la théorie chez vous à l’application sur le terrain. De plus, certains opérateurs peu connus mais puissants étendent ce que vous pouvez faire avec SQL.
Laissez-moi vous montrer ces 3 pratiques SQL que j’ai apprises sur le terrain au cours de mes toutes premières années en tant qu’ingénieur Data.
Mes 3 pratiques SQL :
Utilisation de l’expression de la table commune (WITH)
J’ai une table contenant des évaluations ou ratings qui sont associées à un film. Et disons que je souhaite calculer le nombre moyen de ratings par film.
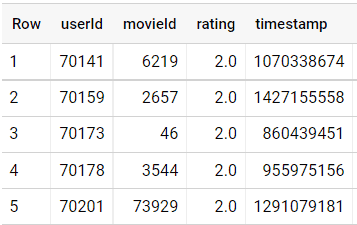
Pour répondre à cette question, on calcule dans une première requête le nombre de ratings par movie_id (comme ci-dessous) et on prend la moyenne.
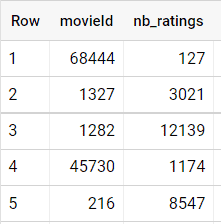
En termes de syntaxe, vous avez deux approches :
Utilisation d’une sous-requête (subquery)
SELECT
AVG(nb_ratings)
FROM (
SELECT
movieId
,count(*) as nb_ratings
FROM `allocine-bq.movielens.ratings`
GROUP BY 1)Utilisation d’une CTE (Common Table Expression)
WITH ratings_by_movie AS (
SELECT
movieId
,count(*) as nb_ratings
FROM `allocine-bq.movielens.ratings`
GROUP BY 1)
SELECT
AVG(nb_ratings)
FROM ratings_by_moviePourquoi utiliser le CTE au lieu de la sous-requête ?
Cela rend votre code plus clair : en effet, les étapes de traitement sont exposées linéairement et dans l’ordre, au lieu d’être encapsulées. L’exemple ci-dessus est simple, mais il est particulièrement utile lorsque vous avez des requêtes avec de longues séries d’étapes et beaucoup plus de champs dans le SELECT.
Notez que lorsque vous travaillez avec des RDMS comme postgresql ou mysql, cette commande peut avoir des effets secondaires sur les performances. Cet opérateur a été implémenté à l’origine dans un but d’optimisation. Cela ne devrait pas être le cas sur les bases de données modernes.
Les effets des valeurs NULL…
…sur des opérations arithmétiques
Voici l’exemple classique qui a fait perdre du temps à beaucoup de débutants SQL la première fois qu’ils l’ont rencontré : l’opération ci-dessous renvoie une valeur NULL.
DECLARE a INT64 DEFAULT 10; DECLARE b INT64 DEFAULT NULL; SELECT a + b
Croyez-moi, si vous n’en êtes pas sûrs, vous pouvez passer beaucoup de temps à déboguer des requêtes qui calculent des KPI complexes.
Vous pouvez utiliser l’opérateur IFNULL comme solution de rechange :
IFNULL(expr, null_result) : if expr is NULL then return null_result else return expr
SELECT a + IFNULL(b,0)
Notez que cette propriété est très utile pour effectuer des divisions. L’opération ci-dessous retourne une valeur NULL et non une “division by zero”.
DECLARE a INT64 DEFAULT 10; DECLARE b INT64 DEFAULT NULL; SELECT a / b
Ainsi, dans certains cas, vous pourriez vouloir remplacer volontairement la valeur 0 par NULL.
…sur des fonctions d’aggrégation
Dans le même esprit, les valeurs NULL sont ignorées par les fonctions AVG(), vous devez les remplacer par un 0 si vous voulez les prendre en compte.
De même, COUNT(field_a) comptera toutes les valeurs non NULL pour le field_a.
Fonctions Analytiques
Ce modèle est un peu plus compliqué et vous permet de calculer des indicateurs ou KPIs avancés comme la somme courante ou la moyenne mobile. Je vais le présenter ci-dessous avec un exemple plus simple.
Disons que vous avez une table des commandes par client avec les revenus et que vous voulez numériser par client ses commandes en fonction de la date. Dans le domaine du e-commerce, il s’agit de la première étape nécessaire pour effectuer une analyse des acquisitions ou de la rétention.
Vous pouvez utiliser cette requête :
SELECT
*
,RANK() OVER (PARTITION BY customer_id ORDER BY date ASC) as order_number
FROM orders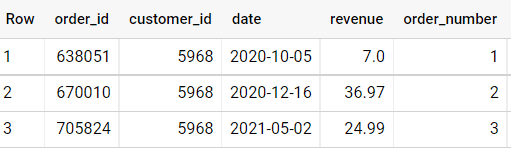
Vous avez ainsi dit : pour chaque client, créer un rang d’ordre itératif basé sur la date de la commande.
Ce modèle est similaire à une fonction d’agrégation :
- Vous remplacez GROUP BY par PARTITION BY
- ORDER BY est nécessaire pour utiliser une fonction de classement
- OVER() déclare l’utilisation d’une fonction analytique
Une fonction analytique est le seul moyen d’utiliser les fonctions qui nécessitent un opérateur ORDER BY.
Pour terminer avec cet exemple, sachez qu’il existe une différence entre RANK() et ROW_NUMBER() :
- RANK() si 2 commandes ont été passées à la même date, elles auront le même rang.
- ROW_NUMBER() : ils auront un numéro de rang différent (arbitraire).
J’utilise parfois les fonctions analytiques pour calculer des fonctions d’agrégation que je pourrais calculer avec un GROUP BY. Si je veux utiliser les opérateurs SUM() ou AVG() mais avec des partitions différentes, les fonctions analytiques simplifieront ma requête en évitant les sous-requêtes et les jointures supplémentaires.
Pour aller plus loin, vous pouvez suivre notre cours d’analyse de données avec SQL ou celui d’apprentissage rapide de SQL pour le marketing.










