
Le Web Scraping est une technique permettant d’extraire automatiquement de grandes quantités d’informations d’un site Web, ce qui permet d’économiser énormément de temps et d’efforts. Dans cet article, nous allons passer en revue un exemple simple d’automatisation du téléchargement de centaines de fichiers à partir du MTA de New York (transports New Yorkais). Il s’agit d’un excellent exercice pour les débutants sur le Web qui cherchent à comprendre comment scraper le Web. De premier abord le Web Scraping peut sembler légèrement intimidant, dans cet article je vais vous prendre par la main afin d’y voir plus clair.
Si cela vous donne envie d’aller plus dans le scraping, vous pouvez jeter un œil à ma formation complète de Scraping, c’est par ici.
Données du MTA New York
Nous allons télécharger les données à partir de ce site web: http://web.mta.info/developers/turnstile.html
Les données turnstile sont compilées chaque semaine depuis mai 2010 à aujourd’hui, il existe donc des centaines de fichiers .txt sur le site. Vous trouverez ci-dessous un extrait de certaines des données. Chaque date est un lien vers le fichier .txt que vous pouvez télécharger.
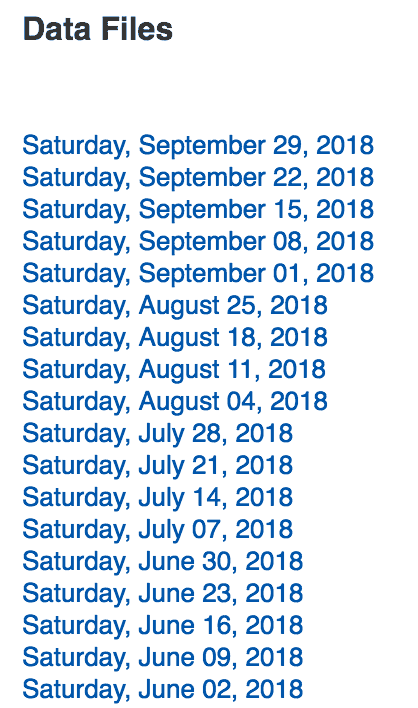
Il serait long et pénible de cliquer manuellement sur chaque lien avec le bouton droit de la souris et de l’enregistrer sur votre bureau. C’est ici qu’entre en jeu le Web Scraping!
Remarques importantes sur le Web Scraping
- Lisez les conditions générales du site Web pour comprendre comment vous pouvez utiliser les données en toute légalité. La plupart des sites vous interdisent d’utiliser les données à des fins commerciales.
- Assurez-vous de ne pas télécharger les données trop rapidement, car cela pourrait endommager le site Web. Vous pourriez également être bloqué du site.
Inspecter le site web
La première chose à faire est de savoir où trouver les liens vers les fichiers à télécharger dans les multiples niveaux de balises HTML. En termes simples, il y a beaucoup de code sur une page de site Web et nous voulons trouver les éléments de code pertinents contenant nos données. Si vous ne connaissez pas bien les balises HTML, reportez-vous aux tutos w3schools. Il est important de comprendre les bases du HTML pour réussir à scraper le Web.
Sur le site Web, faites un clic droit et cliquez sur «Inspecter». Cela vous permet de voir le code brut derrière le site.
Une fois que vous avez cliqué sur «Inspecter», cette console devrait apparaître :
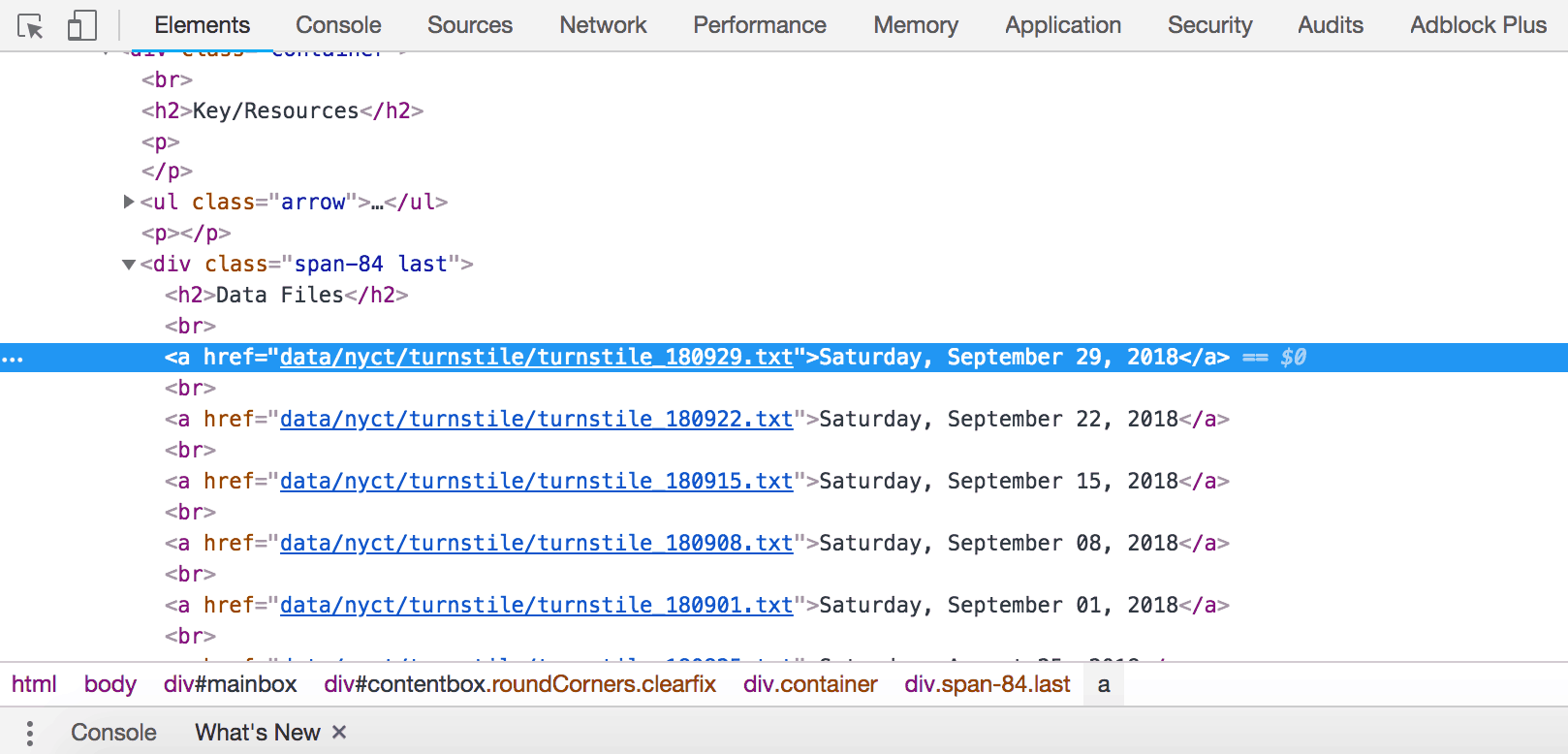

Notez qu’en haut à gauche de la console, il y a un symbole de flèche

Si vous cliquez sur cette flèche puis sur une zone du site lui-même, le code de cet élément particulier sera mis en surbrillance dans la console. J’ai cliqué sur un fichier de données au hasard, le samedi 26 mai 2018, et la console a surligné en bleu le lien vers ce fichier en particulier.
<a href="data/nyct/turnstile/turnstile_180526.txt">Saturday, May 26, 2018</a
Notez que tous les fichiers .txt se trouvent dans la balise <a> suivant la ligne ci-dessus. Au fur et à mesure que vous scrapez le Web, vous constaterez que le <a> est utilisé pour les hyperliens.
Maintenant que nous avons identifié l’emplacement des liens, commençons à coder!
Code Python
Nous commençons par importer les bibliothèques suivantes:

Ensuite, nous définissons l’URL du site Web et accédons au site avec notre bibliothèque de requests :

Si l’accès a réussi, vous devriez voir le résultat suivant:

Ensuite, nous analysons le code HTML avec BeautifulSoup afin de pouvoir utiliser une structure de données BeautifulSoup plus belle et imbriquée. Si vous souhaitez en savoir plus sur cette bibliothèque, consultez la documentation de BeatifulSoup.

Nous utilisons la méthode .findAll pour localiser toutes nos balises.
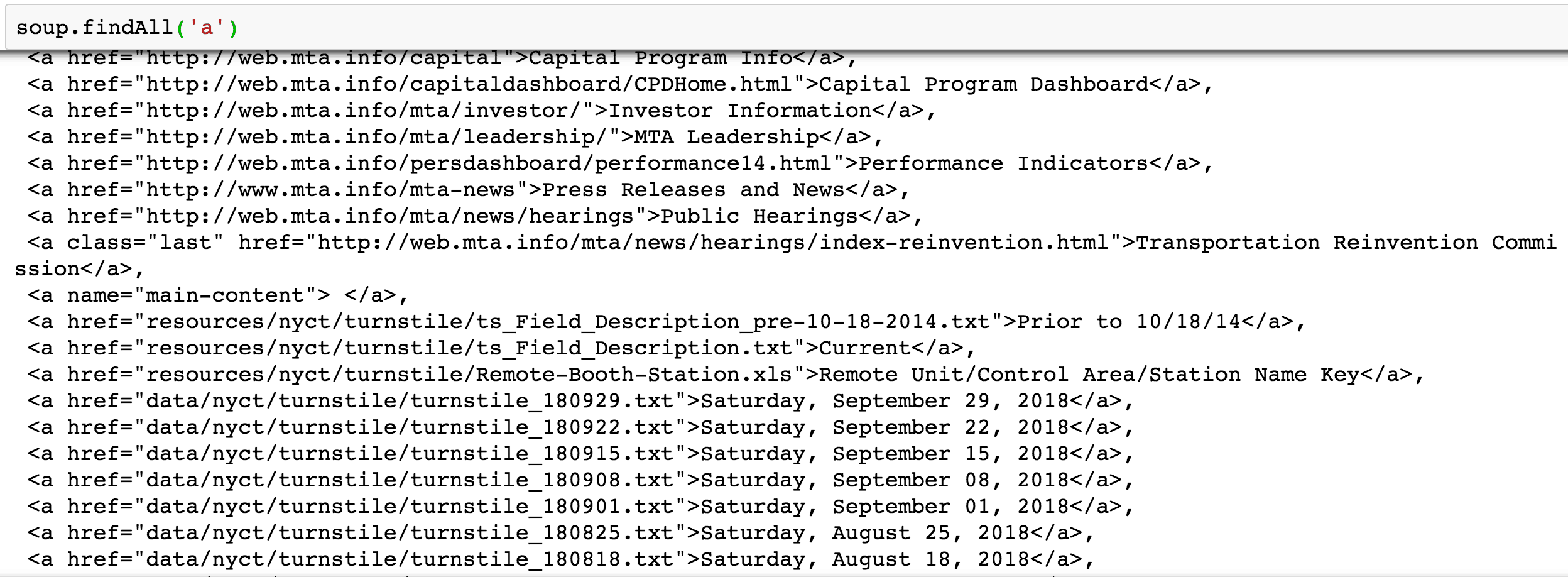
Ce code nous donne chaque ligne de code qui a une balise <a>. Les informations qui nous intéressent (dans l’affichage ci-dessus) commencent à la ligne 36. Tous les liens ne correspondent pas forcément à notre recherche. Nous pouvons donc facilement commence notre scraping à partir de la ligne 36.
Ensuite, nous pouvons extraire le lien que nous voulons. Par exemple le premier à la ligne 36:

Vérifions que cela retourne bien notre premier lien:

Ce code enregistre ‘data/nyct/turnstile/turnstile_180929.txt’ dans notre lien de variable. L’URL complète pour télécharger les données est en fait “http://web.mta.info/developers/data/nyct/turnstile/turnstile_180929.txt” que j’ai découvert en cliquant sur le premier fichier de données du site Web (pour tester). Il faut donc ajouter “http://web.mta.info/developers/” devant chaque lien scrapé.
Nous pouvons utiliser la bibliothèque urllib.request pour télécharger ce fichier sur notre ordinateur.
Nous donnons à request.urlretrieve deux paramètres : le fichier url et le nom du fichier. Pour mes fichiers, je les ai nommés “turnstile_180929.txt”, “turnstile_180922”, etc.
Voici le lien de téléchargement d’un fichier et la méthode de téléchargement de ce fichier:

Enfin, nous devrions inclure cette ligne de code afin de pouvoir suspendre notre code pendant une seconde afin de ne pas envoyer de requêtes au site Web. Cela nous aide à ne pas être signalé comme spam.

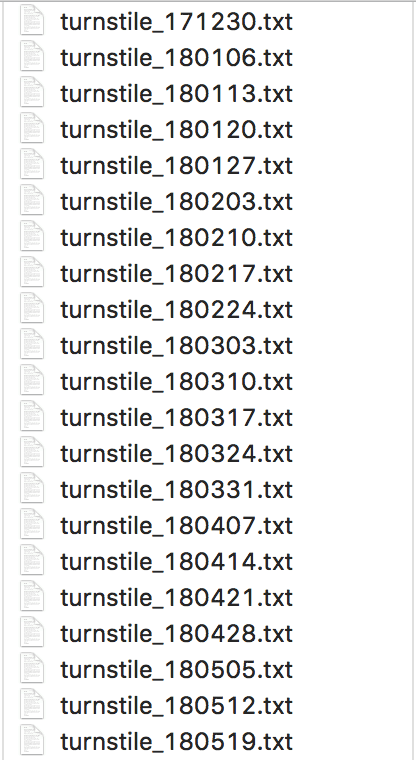
Maintenant que nous savons comment télécharger un fichier, essayons de télécharger l’ensemble des fichiers de données avec une boucle for. Le code ci-dessous contient l’ensemble du code permettant de récupérer la centaine de fichiers txt MTA de New York.

Résultat cela télécharge tous les fichiers texte… :
Si vous souhaitez aller plus loin et voir plus de techniques de scraping, jetez un œil à ma formation complète d’APIs et Web Scraping en cliquant ici.










est-ce que c’est possible d’utiliser Selenium en multithreading ? prévoir un nombre exact de navigateur et les faire travailler en toute indépendance, tous en même temps ?
Oui tout à fait possible !