Python est un langage scientifique très mature. On y trouve des librairies pour tout un tas d’utilisation différentes: notamment le Machine Learning et l’analyse de data. La visualisation de données est une partie importante pour explorer nos données et pour communiquer les résultats.
Au cours des dernières années, de nombreuses nouvelles librairies de visualisation de données ont vu le jour sur Python pour combler son retard avec le langage R. Matplotlib est devenu la principale librairie de visualisation de données. Mais il existe également des librairies telles que vispy, bokeh, seaborn, pygal, folium et networkx qui s’appuient sur matplotlib (certaines fonctionnalités de ces librairies ne sont pas toutes supportées par matplotlib).
Dans cet article, nous utiliserons chacune des librairies ci-dessus pour créer des graphiques.Et en faisant cela, nous découvrirons les forces et faiblesses de chaque librairie.
Quelle est la plus performante ? Comment tirer le meilleur de Python en termes de visualisation de données ?
Si tu veux apprendre l’analyse de données plus en profondeur, regarde ma formation complète ici (Analyse et Visualisation de données avec Python).
Exploration des données
Avant de rentrer dans le vif du sujet de la visualisation de données, jetons un coup d’œil sur le dataset avec lequel nous travaillerons. Nous utiliserons les données provenant d’openflights (données de routes aériennes, d’aéroport et de compagnie aérienne). Voici les différents datasets utilisés pour reproduire chez vous: routes, airports et airlines. Chaque ligne dans les données de route correspond à une route aérienne entre deux aéroports. Chaque ligne dans les données de l’aéroport correspond à un aéroport dans le monde et contient des informations à ce sujet. Chaque ligne dans les données de compagnie aérienne représente une compagnie aérienne tout simplement.
Lecture des données

Les données n’ont pas d’en-têtes de colonne. Nous les ajoutons donc manuellement en les affectant à l’attribut columns. Nous voulons lire chaque colonne en tant que chaîne de caractères – cela facilitera la comparaison entre les données plus tard (lorsque nous aurons besoin de faire correspondre les lignes en fonction de leur identifiant — id). Nous faisons cela en définissant le paramètre dtype lors de la lecture des données.
Regardons le résultat de chaque dataframe:



Nous pouvons faire une variété d’explorations intéressantes avec chaque dataset. Mais ce sera le plus bénéfique en les combinant. La bibliothèque Pandas nous aidera dans notre analyse car elle permet de filtrer facilement les matrices ou encore appliquer des fonctions sur des colonnes. Nous allons nous intéresser à quelques metrics telles que les compagnies aériennes et les itinéraires aériens.
Avant ça, nous devons faire un peu de nettoyage de données (data cleaning):

Cette ligne nous assure d’avoir uniquement des données numériques dans la colonne airline_id.
Réalisation d’un histogramme
Maintenant nous pouvons aller plus loin et commencer à faire des graphiques pour explorer nos données. Pour notre premier graphique, nous utiliserons Matplotlib. Matplotlib est une bibliothèque assez basique permettant de tracer des graphiques avec Python. Il faut donc généralement plus de commandes pour faire des graphiques attrayants qu’avec d’autres librairies. D’un autre côté, vous pouvez faire presque n’importe quel type de graphique avec Matplotlib. Cette flexibilité se fait au détriment du nombre de commandes nécessaires pour tracer un graphique un peu plus élaboré.
Nous allons d’abord faire un histogramme montrant la distribution des longueurs des routes aériennes pour les compagnies aériennes. Pour rappel un histogramme divise toutes les longueurs d’itinéraire aérien en intervalles (ou «boîtes») et compte le nombre d’itinéraires qui tombent dans chaque intervalle. Cela peut nous indiquer si les compagnies aériennes effectuent des trajets plutôt courts ou plutôt longs.
Pour cela, nous devons d’abord calculer les longueurs des routes aériennes. La première étape est une formule de distance. Nous utiliserons la formule d’haversine qui calcule la distance entre deux points d’une sphère, à partir de leurs longitudes et latitudes.

Ensuite, nous pouvons écrire une fonction qui calcule la distance entre les aéroports source et dest pour un seul itinéraire. Pour cela, nous devons obtenir les source_id et dest_id des aéroports à partir du dataframe routes. Puis nous devons les faire correspondre avec la colonne id dans le dataframe airports pour obtenir la latitude et la longitude de ces aéroports. Enfin c’est plus qu’une question de calcul.
Voici la fonction :

La fonction peut échouer s’il y a une valeur invalide dans les colonnes source_id ou dest_id. D’où le bloc try / except pour les éviter.
Pour finir, nous utiliserons la méthode apply de la librairie pandas pour appliquer la fonction de calcul de la distance (calc_dist) sur l’ensemble de données de routes. Cela nous donnera une objet Series pandas contenant toutes les longueurs de route. À noter que toutes les longueurs d’itinéraire sont toutes en kilomètres.

Maintenant que nous avons une série contenant la longueurs des itinéraires, nous pouvons créer un histogramme. Celui-ci va classer les valeurs dans des intervalles et compter le nombre d’itinéraires dans chaque gamme.
Regardons le résultat :

Nous importons pyplot depuis matplotlib que l’on renomme plt. Nous avons ensuite configuré matplotlib pour afficher les tracés notebook Jupyter avec % matplotlib inline. Finalement, nous pouvons faire un histogramme avec plt.hist(route_lengths, bins = 20). Comme vous pouvez le voir les compagnies aériennes effectuent beaucoup plus de trajets courts que de trajets longs.
Utilisation de la bibliothèque Seaborn
Nous pouvons réaliser un graphique similaire avec Seaborn, une bibliothèque un peu plus élaborée pour Python. Seaborn s’appuie sur Matplotlib et simplifie certains types de graphiques liés à des statistiques. Nous pouvons utiliser la fonction distplot pour tracer un histogramme avec une estimation de densité de noyau. Une estimation de densité de noyau est une courbe – qui est en réalité une version lissée de l’histogramme plus facile à analyser.

Comme vous pouvez le voir, seaborn est par défaut esthétiquement plus agréable que Matplotlib. Seaborn offre une bonne opportunité d’obtenir rapidement des graphiques plus beaux que Matplotlib par défaut. C’est aussi une bonne bibliothèque si vous avez besoin d’approfondir votre travail et de l’axer d’un point de vue statistique.
Diagramme en barres
Les histogrammes c’est bien…mais voir la longueur moyenne d’un itinéraire par compagnie aérienne c’est mieux :). Pour cela, nous pouvons utiliser un diagramme en barres. On aura une barre individuelle pour chaque compagnie aérienne nous indiquant la longueur moyenne des itinéraires par compagnie aérienne. Cela nous permettra de voir quelles compagnies sont nationales et lesquelles sont internationales. Nous allons utiliser la librairie Pandas pour déterminer la longueur moyenne d’un itinéraire par compagnie aérienne.

Nous créons d’abord un nouveau DataFrame avec les longueurs d’itinéraire et les ids des compagnies aériennes. Nous divisons route_length_df en groupes à partir du paramètre airline_id. Il en résulte la création d’un DataFrame par compagnie aérienne. Nous utilisons ensuite la fonction aggregat de la bibliothèque Pandas pour calculer la moyenne de la colonne length de chacun des DataFrames. Ensuite, nous ajoutons chaque résultat dans un nouveau DataFrame airline_route_lengths. Nous trions ensuite les données de telle sorte que les itinéraires les plus longs sortent en premier.
Nous pouvons enfin tracer notre diagramme en barres avec matplotlib:

La méthode matplotlib plt.bar trace le temps moyen de vol de chaque compagnie aérienne (airline_route_lengths [« length »]).
Le problème du graphique ci-dessus c’est que nous ne pouvons pas déterminer facilement la longueur moyenne de vol pour une compagnie aérienne donnée. Pour cela, nous devrons être en mesure d’ajouter des intitulés sur l’axe horizontal. Ce n’est pas évident au vu du nombre de compagnies aériennes. Une solution serait de rendre le graphique interactif, ce qui nous permettrait de zoomer pour voir les noms de compagnie aérienne. Nous pouvons utiliser la bibliothèque bokeh pour cela. Elle rend la création de graphiques interactifs et zoomables assez facile.
Pour utiliser Bokeh, nous devons d’abord réaliser un traitement de nos données :
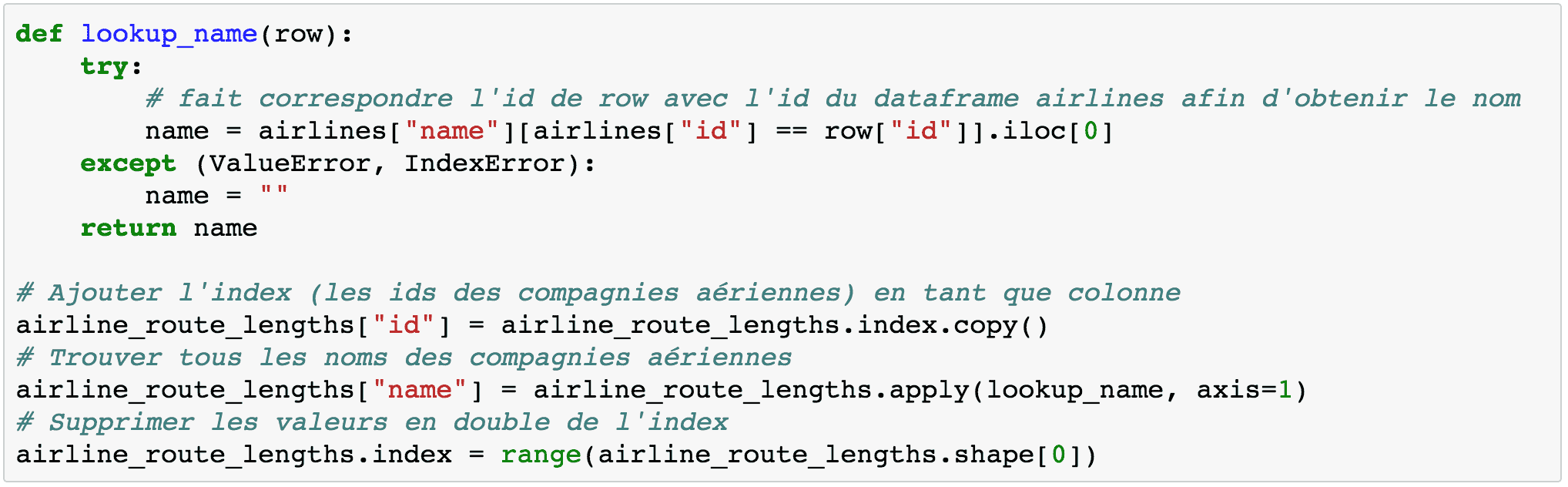
Le code ci-dessus obtiendra les noms de chaque ligne dans airline_route_lengths. Il ajoutera une colonne name contenant le nom de chaque compagnie aérienne. Nous ajoutons également dans la colonne id afin que nous puissions faire cette recherche (la fonction apply ne s’applique aux ids de l’index).
Enfin, nous réinitialisons la colonne d’index pour avoir toutes les valeurs uniques. La bibliothèque Bokeh ne fonctionne pas correctement sans cela.
Maintenant, nous pouvons passer à la partie graphique:

Nous appelons output_notebook pour configurer Bokeh pour afficher le graphique interactif dans notre notebook. Ensuite à partir de la librairie bkcharts, nous faisons un diagramme en barres en utilisant certaines colonnes de notre DataFrame. Enfin, la fonction show affiche le graphique.
Le graphique généré n’est pas une image – c’est en fait un widget javascript. Pour cette raison, la capture d’écran (contrairement au graphique réel) n’est pas interactive.

Avec ce graphique, nous pouvons zoomer et voir quelles compagnies aériennes effectuent les plus longs trajets. L’image ci-dessus donne l’impression que les noms des compagnies se superposent. En réalité, elles sont beaucoup plus faciles à voir lorsque vous effectuez un zoom avant.
Graphique à barres horizontales
Pygal est une bibliothèque Python d’analyse de données python qui peut rendre nos graphiques rapidement attrayants. Nous pouvons l’utiliser pour faire une ventilation des itinéraires par longueur. Nous allons d’abord séparer nos itinéraires en 3 catégories : court, moyen et long. Puis on calcule le pourcentage de chacune de ces 3 catégories.

Nous pouvons ensuite tracer chacune de ces catégories dans un graphique à barres horizontales pygal:


Ci-dessus, nous créons d’abord un graphique vide. Ensuite, nous ajoutons des éléments: un titre et des barres. Chaque barre a un pourcentage (sur 100) indiquant la fréquence de ce type de route.
Enfin, nous créons le graphique dans un fichier et utilisons les capacités d’affichage SVG de jupyter pour charger et afficher le fichier. Ce graphique est plus sympa que les graphiques Matplotlib par défaut. En contre-partie nous avons dû écrire plus de code pour le créer. Pygal est très bon pour des graphiques nécessitant une qualité de présentation supérieure.
Graphique à nuage de points
Les diagrammes à nuage de points nous permettent de comparer des colonnes de données. Nous pouvons par exemple faire un simple diagramme à dispersion de points pour comparer le numéro d’identification id de la compagnie aérienne à la longueur des noms des compagnies aériennes :

Nous calculons d’abord la longueur de chaque nom en utilisant la méthode apply de la bibliothèque Pandas. Cela retourne le nombre de caractères de chaque nom de compagnie aérienne.
Nous réalisons ensuite un nuage de points comparant les ids des compagnies aériennes à la longueur des noms (le tout grâce à Matplotlib). Lorsque nous traçons, nous convertissons la colonne id de airlines en un élément de type entier. En effet le graphique a besoin de valeurs numériques sur l’axe des x. Nous pouvons voir qu’un certain nombre de noms plus longs apparaissent dans les ids précédents. Cela peut signifier que les compagnies aériennes fondées il y a plus longtemps, ont tendance à avoir des noms plus longs.
Nous pouvons vérifier cette intuition en utilisant Seaborn. Seaborn a une version améliorée du diagramme à dispersion de points, un jointplot, qui montre à quel point les deux variables sont corrélées, ainsi que les distributions individuelles de chacune.

Le graphique ci-dessus montre qu’il n’y a pas de corrélation réelle entre les deux variables – la valeur r² est faible.
Cartes statiques
Nos données sont intrinsèquement adaptées à la cartographie – nous avons des paires de latitude et de longitude pour les aéroports ainsi que pour les sources de départ et points de destination des aéroports.
La première carte que nous pouvons faire montrant les aéroports du monde entier. Nous pouvons le faire avec l’extension basemap de Matplotlib. Cela permet de dessiner des cartes du monde et d’ajouter des points, tout en étant très personnalisable.

Dans le code ci-dessus, nous dessinons d’abord une carte du monde, en utilisant une projection de Mercator. Une projection de Mercator est une façon de projeter toute la carte du monde sur une surface 2D. Puis, nous dessinons les aéroports sur la carte à l’aide de points rouges.
Le problème avec la carte ci-dessus est qu’il est difficile de voir où se trouve chaque aéroport – ils se fondent dans une zone rouge dans les zones à forte densité d’aéroports.
Tout comme avec bokeh, il y a une bibliothèque de cartographie interactive : folium que nous pouvons utiliser pour zoomer sur la carte. Cela pourra nous aider à trouver des aéroports individuels.


Folium utilise leaflet.js pour créer une carte entièrement interactive.Vous pouvez cliquer sur chaque aéroport pour voir le nom dans la fenêtre contextuelle. Une capture d’écran est montrée ci-dessus mais la carte actuelle est beaucoup plus impressionnante. Folium vous permet également de modifier assez largement les options pour créer de meilleurs marqueurs ou ajouter plus d’éléments à la carte.
Dessiner de grands cercles
Ce qui serait vraiment cool, c’est de voir toutes les routes aériennes sur une carte. Heureusement, nous pouvons utiliser basecamp pour cela. Nous dessinerons de grands cercles (orthodromie) reliant les aéroports source et ceux de destination. Chaque cercle montrera l’itinéraire unique d’un avion de ligne. Malheureusement, il y a tellement de routes que toutes les montrer serait une sacrée pagaille. Au lieu de cela, nous allons montrer les 3000 premières routes.

Le code ci-dessus va dessiner une carte puis dessiner les routes dessus. Nous ajoutons des filtres pour éviter que les routes trop longues n’obscurcissent les autres.
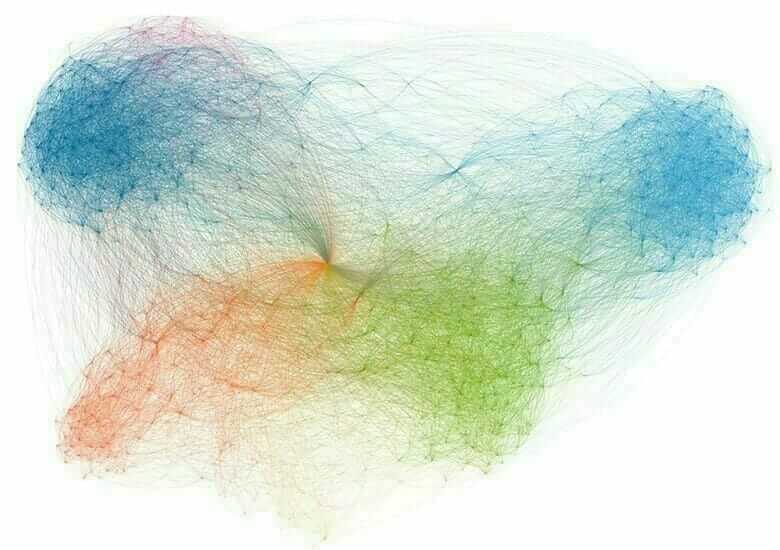
Dessiner un diagramme de réseaux
L’exploration finale que nous ferons est de dessiner un diagramme de réseau des aéroports. Chaque aéroport sera un nœud dans le réseau. Nous tracerons des liaisons entre les nœuds s’il y a une route entre les aéroports. S’il y a plusieurs routes, nous ajouterons un poids de réseau pour montrer que les aéroports sont plus connectés.< Nous allons utiliser la bibliothèque networkx pour cela.
Tout d’abord, nous devrons calculer les poids marginaux entre les aéroports.

Une fois que le code ci-dessus a fini de s’exécuter, le dictionnaire des poids contient toutes les liaisons entre deux aéroports dont le poids est supérieur à 2. Ainsi, tous les aéroports connectés par 2 routes ou plus apparaîtront.
Maintenant, traçons le graphique !


Conclusion
Dernièrement, il y a eu une prolifération de librairies Python pour la visualisation de données. Il est maintenant possible de faire presque n’importe quel type de visualisation. La plupart des bibliothèques s’appuient sur Matplotlib et simplifient certains cas d’utilisation. Si vous voulez apprendre plus en profondeur la Data Science, vous pouvez regarder les formations MonCoachData.