Si tu veux travailler dans la Data, que ce soit Data Analyst, Data Scientist ou Data Engineer, tu dois nécessairement maîtriser SQL et Pandas. Voici 30 requêtes SQL expliquées avec le code Pandas équivalent.
Petit retour dans le passé, dans un monde dominé par SQL depuis 1974, Pandas est apparu en 2008, offrant des fonctionnalités attrayantes telles que la visualisation intégrée et la manipulation flexible des données. Il est rapidement devenu l’outil de prédilection pour l’exploration des données, éclipsant SQL.
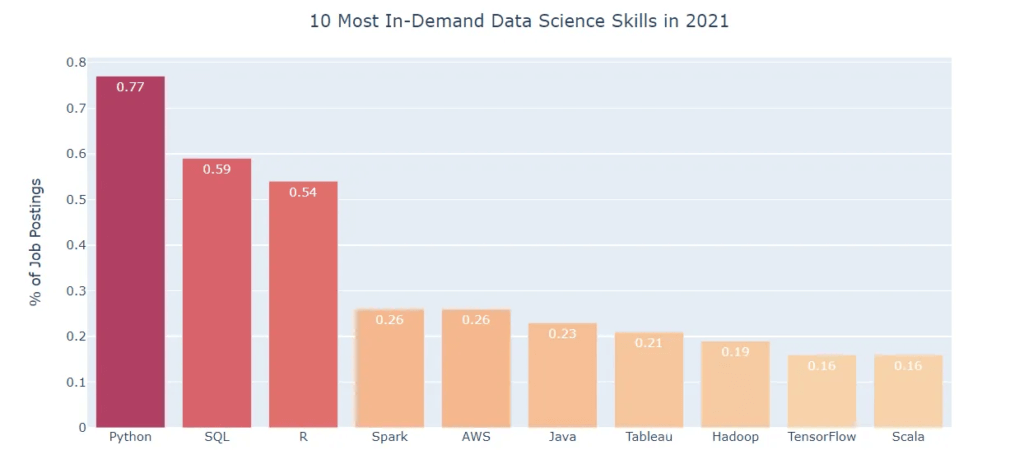
Mais ne vous y trompez pas, le langage SQL a encore de beaux jours devant lui. C’est le deuxième langage le plus demandé et le troisième qui connaît la plus forte croissance dans le domaine de la Data Science. Ainsi, même si Pandas vole la vedette, SQL reste une compétence essentielle pour tout data scientist.
Voyons à quel point il est facile d’apprendre SQL quand on connaît déjà Pandas.
Connexion à une base de données
La configuration d’un espace de travail SQL et la connexion à une base de données d’échantillons peuvent s’avérer très difficiles. Tout d’abord, tu dois installer ta version préférée de SQL (PostgreSQL, MySQL, etc.) et télécharger un IDE SQL. Faire cela ici nous éloignerait de l’objectif de l’article, c’est pourquoi nous utiliserons un raccourci.
Plus précisément, nous exécuterons directement des requêtes SQL dans un notebook Jupyter sans étapes supplémentaires. Tout ce que nous avons à faire est d’installer le paquetage ipython-sql à l’aide de pip :
pip install ipython-sql
Après l’installation, démarre une nouvelle session Jupyter et exécute cette commande dans le notebook :
%load_ext sql
et le tour est joué !
Pour illustrer le fonctionnement des instructions SQL de base, nous utiliserons la base de données Chinook SQLite, qui comporte 11 tables.
Pour charger l’ensemble de données et ses 11 tables en tant que variables distinctes dans notre environnement, nous pouvons exécuter :
%sql sqlite:///data/chinook.db
La déclaration commence par %sql, une commande magique en ligne qui indique à l’interpréteur du notebook que nous allons exécuter des commandes SQL. Elle est suivie par le chemin d’accès à la base de données Chinook téléchargée.
Les chemins valides doivent toujours commencer par le préfixe sqlite:/// pour les bases de données SQLite. Ci-dessus, nous nous connectons à la base de données stockée dans le dossier ‘data’ du répertoire courant. Si tu souhaites transmettre un chemin absolu, le préfixe doit commencer par quatre barres obliques – sqlite:////
Premier aperçu des tables
La première chose que nous faisons toujours dans Pandas est d’utiliser la fonction .head() pour jeter un premier coup d’œil aux données. Voyons comment faire cela en SQL :
%%sql SELECT * FROM customers LIMIT 5
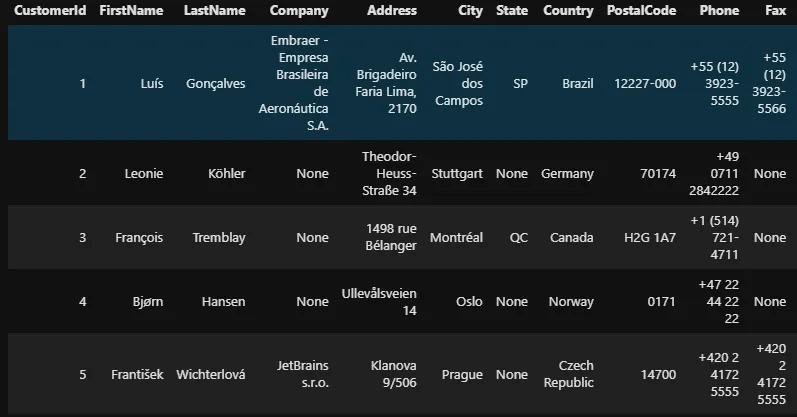
Le premier mot-clé de la requête ci-dessus est SELECT. Il est équivalent à l’opérateur crochets dans Pandas, qui permet de sélectionner des colonnes spécifiques. Mais le mot-clé SELECT est suivi d’un * (astérisque). * est un opérateur SQL qui sélectionne tout (toutes les lignes et toutes les colonnes) dans une table spécifiée après le mot-clé FROM. LIMIT est utilisé pour limiter le nombre de résultats renvoyés. La requête ci-dessus est donc équivalente à la fonction df.head().
Si tu ne souhaites pas sélectionner toutes les colonnes, tu peux spécifier un ou plusieurs noms de colonnes après le mot-clé SELECT :
%%sql SELECT Name, Composer, UnitPrice FROM tracks LIMIT 10
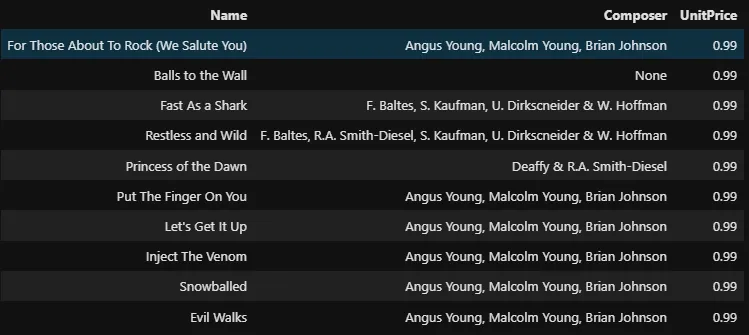
L’opération Pandas équivalente est la suivante :
tracks[['Name', 'Composer', 'UnitPrice']].head(10)
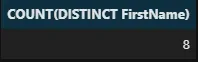
Un autre mot-clé utile en SQL est DISTINCT. L’ajout de ce mot-clé devant le nom d’une colonne permet d’obtenir des valeurs uniques :
%%sql SELECT DISTINCT FirstName FROM employees -- équivalent à `.unique()`
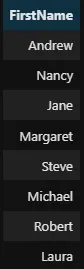
Les commentaires en SQL sont écrits avec des doubles tirets.
Compter le nombre de lignes
Tout comme Pandas dispose d’un attribut .shape sur ses DataFrames, SQL dispose d’une fonction COUNT pour afficher le nombre de lignes d’une table :
%%sql SELECT COUNT(*) FROM tracks
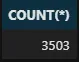
Une information plus utile serait de compter le nombre de valeurs uniques dans une colonne particulière. Nous pouvons le faire en ajoutant le mot-clé DISTINCT dans COUNT :
%%sql SELECT COUNT(DISTINCT FirstName) FROM employees -- équivalent à `employees['FirstName'].nunique()`
Filtrer les résultats avec les clauses WHERE
Se contenter de regarder et de compter les lignes est plutôt maladroit. Voyons comment nous pouvons filtrer les lignes en fonction de conditions.
Tout d’abord, regardons les chansons qui coûtent plus d’un dollar :
%%sql SELECT * FROM tracks WHERE UnitPrice > 1.0 LIMIT 10 --tracks[tracks['UnitPrice' > 1.0]]
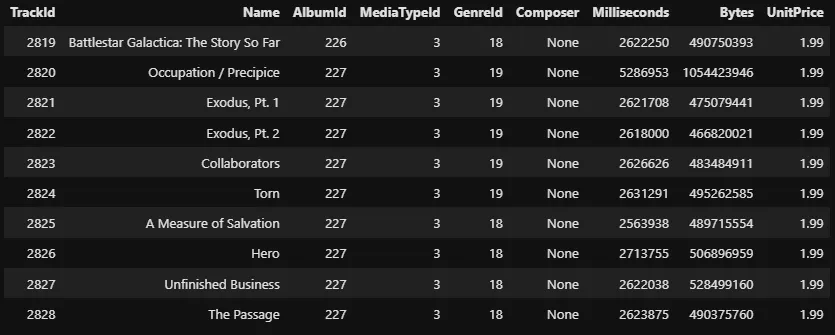
Les instructions conditionnelles sont écrites dans la clause WHERE, qui vient toujours après FROM et avant les mots-clés LIMIT. L’utilisation des conditionnelles est assez similaire à la façon dont nous le faisons dans Pandas, mais j’ose dire que la version SQL est plus lisible.
Tu peux également utiliser la fonction COUNT lorsque tu utilises des conditionnelles. Par exemple, voyons le nombre de chansons dont le prix est compris entre 1 et 10 dollars :
%%sql SELECT COUNT(*) FROM tracks WHERE UnitPrice > 1.0 AND UnitPrice < 10 -- tracks[(tracks['UnitPrice'] > 1) & (tracks['UnitPrice'] < 10)]
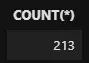
Comme tu peux le constater, la version SQL est beaucoup plus lisible.
Ci-dessus, nous avons enchaîné deux conditions à l’aide de l’opérateur booléen AND. D’autres opérateurs booléens (OR, NOT) sont utilisés de la même manière.
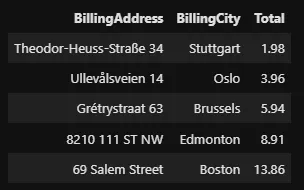
Voyons maintenant toutes les factures dont la ville de facturation est Paris ou Berlin :
%%sql SELECT BillingAddress, BillingCity, Total FROM invoices WHERE BillingCity = 'Paris' OR BillingCity = 'Berlin' LIMIT 5 --invoices[(invoices['BillingCity'] == 'Paris') | -- (invoices['BillingCity'] == 'Berlin')]
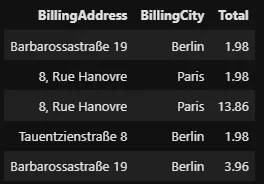
L’opérateur d’égalité en SQL ne nécessite qu’un seul signe “=” (égal). L’opérateur d’inégalité est représenté par les opérateurs “!=” ou “<>” :
%%sql SELECT BillingAddress, BillingCity, Total FROM invoices WHERE BillingCity != 'Paris' AND BillingCity <> 'Berlin' LIMIT 5
Filtrage plus facile avec BETWEEN et IN
Des conditionnelles similaires sont utilisées très souvent, et les écrire avec de simples booléens devient encombrant. Par exemple, Pandas possède la fonction .isin() qui vérifie si une valeur appartient à une liste de valeurs.
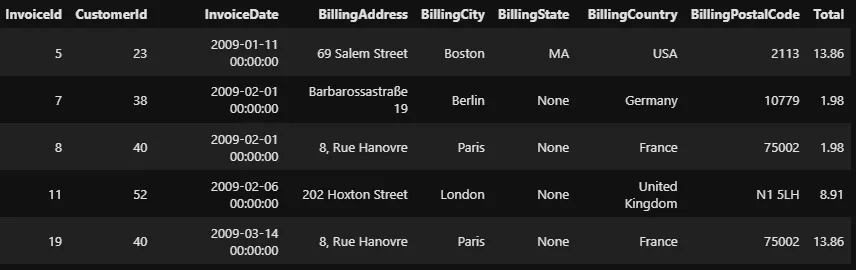
Si nous voulions sélectionner les factures de cinq villes, nous devrions écrire cinq conditions enchaînées. Heureusement, SQL prend en charge un opérateur IN similaire à .isin(), ce qui nous évite d’avoir à le faire :
%%sql
SELECT *
FROM invoices
WHERE BillingCity IN ('Berlin', 'Paris', 'New York', 'Boston', 'London')
LIMIT 5
--invoices[invoices['BillingCity'].isin(
-- ('Berlin', 'Paris', 'New York', 'Boston', 'London')
--)]
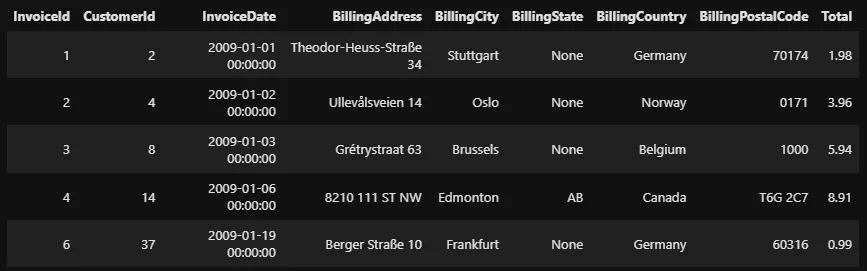
La liste des valeurs après IN doit être donnée sous la forme d’un tuple, et non d’une liste. Tu peux également neutraliser la condition à l’aide du mot-clé NOT :
%%sql
SELECT *
FROM invoices
WHERE BillingCity NOT IN ('Berlin', 'Paris', 'New York', 'Boston', 'London')
LIMIT 5
--invoices[~invoices['BillingCity'].isin(
-- ('Berlin', 'Paris', 'New York', 'Boston', 'London')
--)]
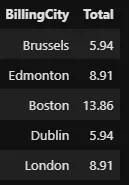
Une autre opération de filtrage courante sur les colonnes numériques consiste à sélectionner des valeurs à l’intérieur d’une plage. Pour cela, le mot-clé BETWEEN peut être utilisé, ce qui est équivalent à pd.Series.between() :
%%sql SELECT BillingCity, Total FROM invoices WHERE Total BETWEEN 5 AND 15 LIMIT 5 --invoices[invoices['Total'].between(5, 15)]
Vérifier les éléments manquants
Toutes les sources de données comportent des valeurs manquantes, et les bases de données ne font pas exception. Tout comme il existe plusieurs façons d’explorer les valeurs manquantes dans Pandas, il existe des mots-clés spécifiques qui vérifient l’existence de valeurs nulles dans SQL. La requête ci-dessous compte le nombre de lignes avec des valeurs manquantes dans BillingState :
%%sql SELECT COUNT(*) FROM invoices WHERE BillingState IS NULL --invoices['BillingState'].isnull().sum()
Tu peux ajouter le mot-clé NOT entre IS et NULL pour écarter les valeurs manquantes d’une colonne particulière :
%%sql SELECT InvoiceDate, BillingCountry FROM invoices WHERE Total IS NOT NULL LIMIT 10
Meilleure correspondance des chaînes de caractères avec LIKE
Dans la clause WHERE, nous avons filtré les colonnes sur la base de valeurs textuelles exactes. Mais il arrive souvent que l’on veuille filtrer des colonnes textuelles sur la base d’un motif (ou pattern). Dans Pandas (et Python pur), nous utiliserions des expressions régulières (regex) pour la recherche de motifs, qui sont très puissantes, mais les expressions régulières demandent du temps pour être maîtrisées.
SQL propose une alternative : le caractère générique “%“, qui permet de faire correspondre n’importe quel caractère 0 fois ou plus. Par exemple, la chaîne “gr%” correspond à “great”, “groom”, “greed”, et “%ex%” correspond à tout texte contenant “ex” au milieu, etc. Voyons comment l’utiliser avec SQL :
%%sql
SELECT Name, Composer, UnitPrice
FROM tracks
WHERE Name LIKE 'B%'
LIMIT 5
--tracks[tracks['Name'].str.startswith('B')]
La requête ci-dessus permet de trouver toutes les chansons qui commencent par “B”. La chaîne qui contient le caractère générique doit venir après le mot-clé LIKE.
Trouvons maintenant toutes les chansons dont le titre contient le mot “beautiful” :
%%sql
SELECT Name, Composer, UnitPrice
FROM tracks
WHERE Name LIKE '%beautiful%'
--tracks[tracks['Name'].str.contains('beautiful')]
Tu pourrais également utiliser d’autres opérateurs booléens en plus de LIKE :
%%sql
SELECT Name, Composer, UnitPrice
FROM tracks
WHERE (Name LIKE 'F%') AND (UnitPrice > 1.0)
--tracks[(tracks['Name'].str.startswith('F')) & (tracks['UnitPrice'] > 1.0)]
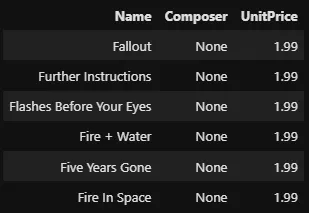
Il existe de nombreux autres caractères génériques dans SQL qui ont des fonctionnalités différentes. Tu peux consulter la liste complète et leur utilisation ici.
Fonctions d’agrégation en SQL
Il est également possible d’effectuer des opérations arithmétiques de base sur les colonnes. Ces opérations sont appelées fonctions d’agrégation en SQL, et les plus courantes sont AVG, SUM, MIN, MAX. Leur fonction devrait être claire d’après leur nom :
%%sql
SELECT SUM(Total), MAX(Total),
MIN(Total), AVG(Total)
FROM invoices
Les fonctions d’agrégation ne donnent qu’un seul résultat pour la colonne sur laquelle elles sont utilisées. Cela signifie que tu ne peux pas agréger une colonne et sélectionner d’autres colonnes non agrégées :
%%sql SELECT AVG(Total), BillingCity, BillingAddress FROM invoices; -- the result will be a single row because -- of the presence of aggregate functions

Il est tout aussi facile de combiner des fonctions agrégées avec des conditions à l’aide de clauses WHERE :
%%sql SELECT AVG(Total), BillingCity FROM invoices WHERE BillingCity = 'Paris' -- invoices[invoices['BillingCity']]['Total'].mean()
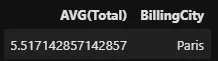
Il est également possible d’utiliser des opérateurs arithmétiques tels que +, –, *, / sur les colonnes et les nombres simples. Lorsqu’ils sont utilisés sur des colonnes, l’opération est effectuée par élément :
%%sql SELECT SUM(Total) / COUNT(Total) FROM invoices -- recherche manuelle de la moyenne
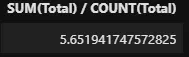
Une chose à noter à propos des opérations arithmétiques : si tu effectues des opérations sur des nombres entiers uniquement, SQL pense que tu attends un nombre entier comme réponse :
%%sql SELECT 10 / 3

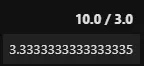
Au lieu de renvoyer 3.33…, le résultat est 3. Pour obtenir un résultat flottant, tu dois utiliser au moins un nombre flottant dans la requête ou utiliser que des nombres flottants pour être sûr :
%%sql SELECT 10.0 / 3.0
Sur la base de ces connaissances, calculons la durée moyenne d’une chanson en minutes :
%%sql SELECT Milliseconds / 1000.0 / 60.0 FROM tracks LIMIT 10
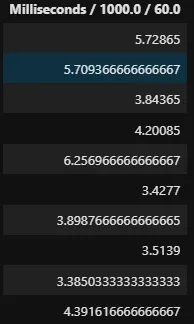
Si tu prêeetes attention à la colonne ci-dessus, son nom est écrit comme “la requête utilisée pour générer cette colonne“. En raison de ce comportement, l’utilisation de longs calculs, tels que la recherche de l’écart type ou de la variance d’une colonne, peut poser problème, car le nom de la colonne sera aussi grand que la requête elle-même.
Pour éviter cela, SQL permet l’aliasing, similaire à l’aliasing des instructions d’importation en Python. Par exemple :
%%sql SELECT SUM(Total) as sum_total FROM invoices
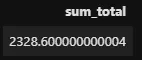
L’utilisation du mot-clé as après un seul élément dans une instruction SELECT indique à SQL qu’il s’agit d’un alias. Voici d’autres exemples :
%%sql
SELECT SUM(Total) as sum_total,
MAX(Total) as max_total,
MIN(Total) as min_total,
SUM(Total) / COUNT(Total) as mean_total
FROM invoices

Tu peux utiliser l’alias tout aussi facilement pour les colonnes dont le nom est long.
Ordonner les résultats en SQL
Tout comme la méthode sort_values de Pandas, SQL prend en charge l’ordonnancement des colonnes via la clause ORDER BY. En passant le nom d’une colonne après la clause, les résultats sont triés par ordre croissant :
%%sql
SELECT Name, Composer, UnitPrice
FROM tracks
WHERE Composer <> 'None'
ORDER BY Composer
LIMIT 10
-- tracks.sort_values('Compose')[['Name', 'Compose', 'UnitPrice']]
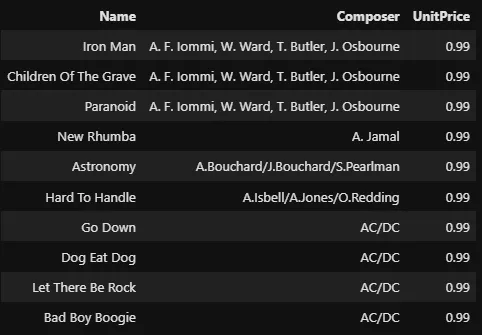
Nous classons la table tracks dans l’ordre croissant du nom du compositeur. Note que l’instruction ORDER BY doit toujours être placée après la clause WHERE. Il est également possible de passer deux colonnes ou plus à l’instruction ORDER BY :
%%sql SELECT Name, Composer, UnitPrice FROM tracks WHERE Composer <> 'None' ORDER BY UnitPrice, Composer, Name LIMIT 10 -- tracks.sort_values(['UnitPrice', 'Composer', 'Name'])\ -- [['Name', 'Compose', 'UnitPrice']]
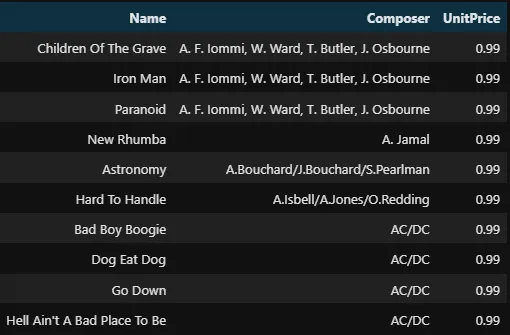
Tu peux également inverser l’ordre en utilisant le mot-clé DESC après chaque nom de colonne :
%%sql SELECT Name, Composer, UnitPrice FROM tracks WHERE Composer != 'None' ORDER BY UnitPrice DESC, Composer DESC, Name ASC LIMIT 10 -- tracks.sort_values(['UnitPrice', 'Composer', 'Name'])\ -- [['Name', 'Compose', 'UnitPrice']]
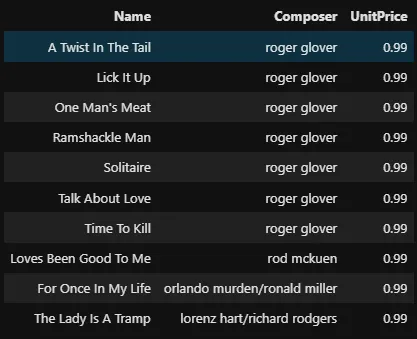
La requête ci-dessus renvoie trois colonnes après avoir ordonné le prix unitaire et la composition par ordre décroissant et le nom par ordre croissant (ASC est un mot-clé par défaut).
Grouper en SQL
L’une des fonctions les plus puissantes de Pandas est le groupby. Tu peux l’utiliser pour transformer une table en pratiquement n’importe quelle forme. Sa cousine très proche en SQL – la clause GROUP BY – peut être utilisée pour obtenir la même fonctionnalité. Par exemple, la requête ci-dessous compte le nombre de chansons dans chaque genre :
%%sql
SELECT GenreID, COUNT(*) as genre_count
FROM tracks
GROUP BY GenreId
LIMIT 10
-- tracks.groupby('GenreId')['GenreID'].count()

La différence entre GROUP BY en SQL et groupby en Pandas est que SQL ne permet pas de sélectionner des colonnes qui n’ont pas été données dans la clause GROUP BY. Par exemple, l’ajout d’une colonne libre supplémentaire dans la requête ci-dessus génère une erreur :
%%sql SELECT Name, GenreID, COUNT(*) as genre_count FROM tracks GROUP BY GenreId
syntax error at or near "GROUP" LINE 1: GROUP BY GenreId;
Toutefois, tu peux choisir autant de colonnes que tu le souhaites dans l’instruction SELECT, à condition d’utiliser une fonction d’agrégation sur ces colonnes :
%%sql
SELECT GenreId, AlbumId,
COUNT(*) as genre_count,
AVG(Milliseconds) / 1000.0 / 60.0 as avg_duration,
AVG(UnitPrice) as avg_price
FROM tracks
GROUP BY GenreId, AlbumId
LIMIT 10
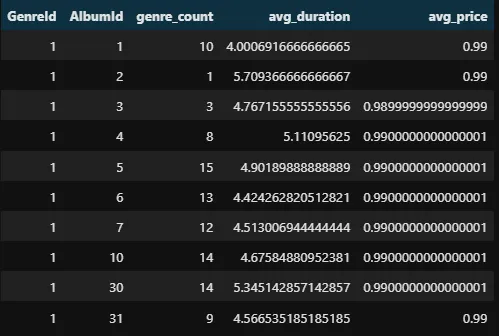
La requête ci-dessus inclut presque tous les sujets que nous avons appris jusqu’à présent. Nous regroupons les données par ID d’album et ID de genre, et pour chaque groupe, nous calculons la durée et le prix moyens d’une chanson. Nous faisons également un usage efficace de l’aliasing.
Nous pouvons rendre la requête encore plus puissante en l’ordonnant en fonction de la durée moyenne et du nombre de genres :
%%sql
SELECT GenreId, AlbumId,
COUNT(*) as genre_count,
AVG(Milliseconds) / 1000.0 / 60.0 as avg_duration,
AVG(UnitPrice) as avg_price
FROM tracks
GROUP BY GenreId, AlbumId
ORDER BY avg_duration DESC, genre_count DESC
LIMIT 10
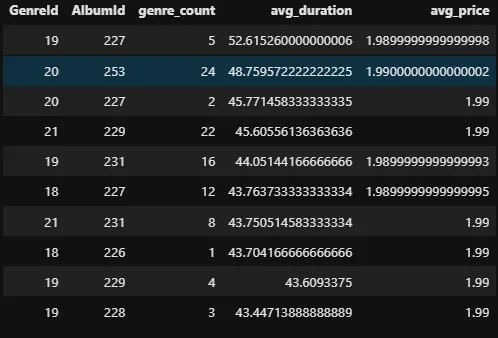
Attention à la façon dont nous utilisons les noms d’alias des fonctions d’agrégation dans la clause ORDER BY. Une fois que tu as donné un alias à une colonne ou au résultat d’une fonction d’agrégation, tu ne peux t’y référer que par leur alias pour le reste de la requête.
Utiliser des conditionnels avec HAVING
Par défaut, SQL n’autorise pas le filtrage conditionnel à l’aide de fonctions d’agrégation dans la clause WHERE. Par exemple, nous voulons sélectionner uniquement les genres dont le nombre de chansons est supérieur à 100. Essayons avec la clause WHERE :
%%sql SELECT GenreId FROM tracks GROUP BY GenreId WHERE COUNT(GenreId) > 10 syntax error at or near "WHERE" LINE 1: where COUNT(GenreId) > 10
La manière correcte de filtrer les lignes sur la base des résultats des fonctions d’agrégation est d’utiliser la clause HAVING :
%%sql SELECT GenreId FROM tracks GROUP BY GenreId HAVING COUNT(GenreId) > 100

La clause HAVING est généralement utilisée avec GROUP BY. Lorsque tu souhaites filtrer des lignes à l’aide de fonctions d’agrégation, la clause HAVING est la meilleure solution !
Conclusion
Tu devrais maintenant avoir réalisé à quel point SQL peut être puissant et combien il est plus lisible que Pandas. Même si nous avons appris beaucoup de choses, nous n’avons fait qu’effleurer la surface.
Tu peux également consulter la première partie du post SQL vs. Pandas.
Pour des problèmes pratiques, je te recommande Data Lemur si tu te sens aventureux.