Une série temporelle ou Time Series est une série de points de données indexés dans le temps. L’analyse des séries temporelles est très fréquemment utilisée, notamment dans les études financières. Pour maîtriser de A à Z, l’analyse et la prévision de Séries Temporelles, tu peux suivre mon programme complet sur le sujet en suivant ce lien.
Dans cet article, pour découvrir ce concept d’analyse de Time Series, je vais te partager le TOP des méthodes de Séries Temporelles avec Pandas.
On va pour cela voir les concepts suivants :
- Qu’est-ce que le ré-échantillonnage ? (resampling)
- Qu’est-ce que le décalage dans le temps ? (shifting)
- Opérations de fenêtre de temps
- Gestion du fuseau horaire
- Changement de fuseau horaire
C’est parti !
Le TOP des méthodes de Séries Temporelles avec Pandas
Exemple de données de Séries Temporelles
Pour faire la démonstration suivante, je vais utiliser l’ensemble de données du cours de l’action Meta (ex-facebook). Tu trouveras ce dataset ici sur Kaggle. Importons ce jeu de données ensemble :
fb = pd.read_csv('FB.csv', parse_dates=['Date'], index_col='Date')Note bien que j’ai utilisé le paramètre parse_dates pour convertir la colonne ‘Date’ en un objet datetime. J’ai également défini le paramètre index_col pour spécifier cette colonne en tant qu’index. Examinons les premières lignes de notre ensemble de données.
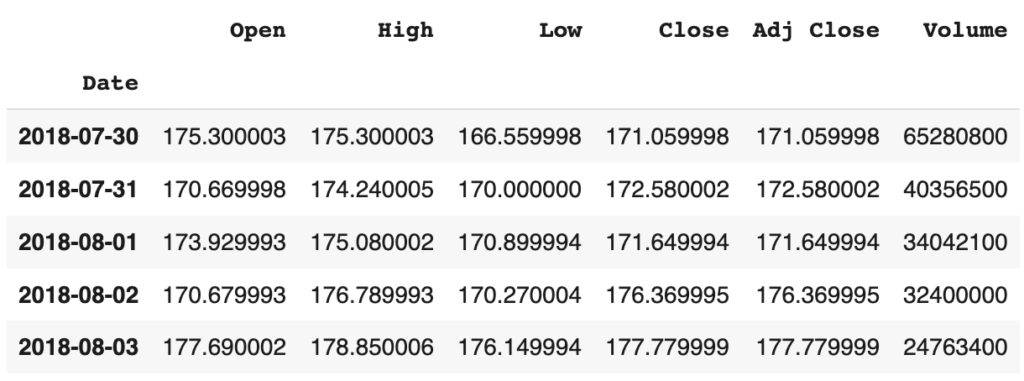
Maintenant que nous avons notre dataframe prêt à l’usage, explorons les méthodes Pandas que l’on peut appliquer à nos objets de Time Series !
Qu’est-ce que le ré-échantillonnage de Séries Temporelles ?
Dans Pandas, le ré-échantillonnage est en quelque sorte un groupby basé sur le temps, suivi d’une méthode de réduction temporelle sur chacun de ses groupes. Avec le ré-échantillonnage, tu peux convertir la série temporelle d’une fréquence à une autre.
La méthode de ré-échantillonnage resample est très souple et te permet de spécifier de nombreux paramètres différents pour contrôler la conversion de fréquence et l’opération de ré-échantillonnage. Examinons les valeurs moyennes mensuelles avec la méthode .resample().
fb.resample('M').mean()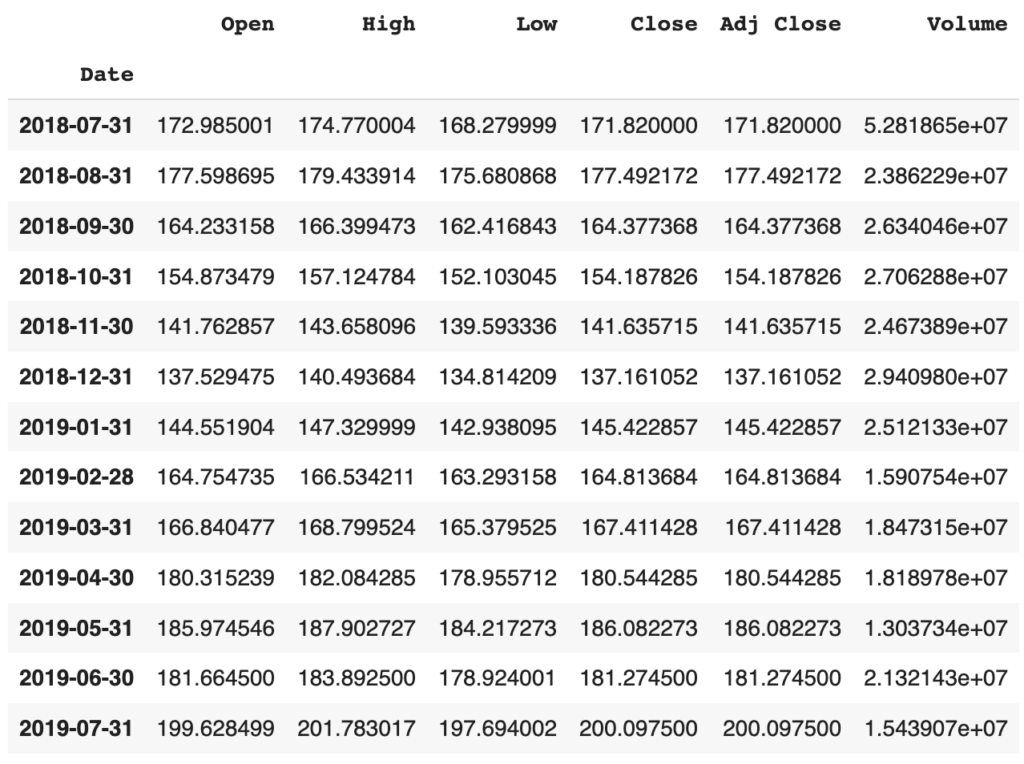
Ensuite, je vais tracer l’évolution des prix à la clôture. Pour afficher le graphique des valeurs moyennes mensuelles, tu peux utiliser la méthode .plot().
fb['Close'].resample('M').mean().plot()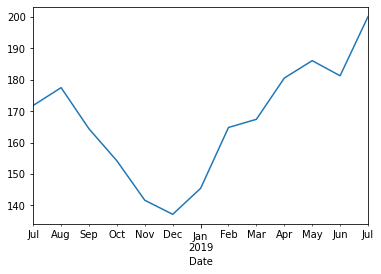
Examinons le graphique à barres des prix moyens des valeurs trimestrielles (Q = Quarter) :
fb['Close'].resample('Q').mean().plot(kind='bar')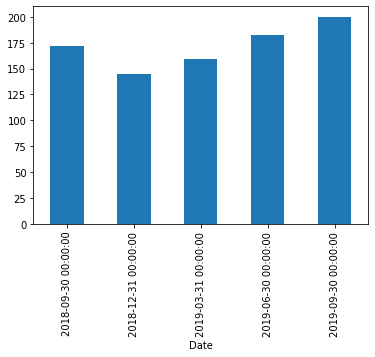
Qu’est-ce que le décalage de temps ?
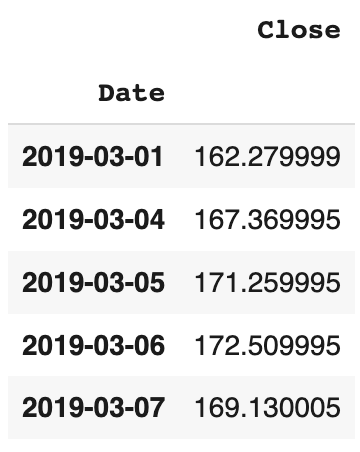
Tu peux souhaiter décaler ou retarder les valeurs d’une série temporelle dans le temps à l’aide de la méthode .shift(). Les séries et les DataFrame possèdent tous deux l’attribut shift. Prenons les valeurs des prix de clôture de Facebook pour le mois de mars et attribuons-les à la variable fb1.
fb1 = pd.DataFrame(fb['Close']['2019-03'])
Jetons un coup d’œil à la variable fb1 résultante :
La méthode .shift() accepte le paramètre freq qui peut accepter une classe DataOffset ou un autre timedelta comme un objet ou un alias offset. Lorsque tu peux déterminer le paramètre freq, la méthode shift modifie toutes les dates de l’index. Décalons les valeurs d’une série temporelle de deux dates en avant.
fb1.shift(2)
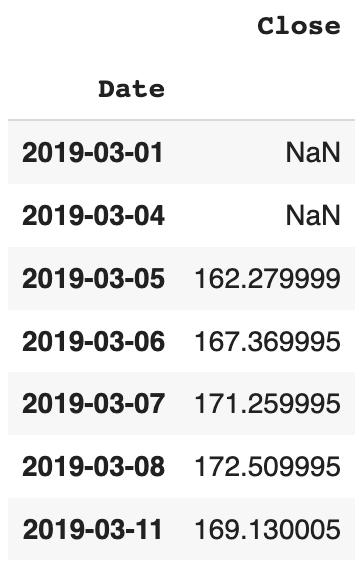
On constate que les valeurs du 1er et 4 mars ont été décalées au 5 et 6 mars (d’où les valeurs manquantes NaN à la place).
De même, décalons les valeurs d’une série temporelle de deux pas en arrière dans le temps.
fb1.shift(-2)
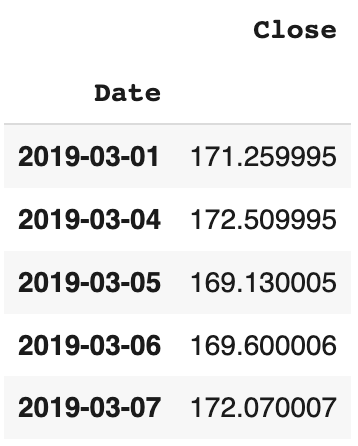
On peut enregistrer ce changement dans le même dataframe pour bien s’en rendre compte :
fb1['Précédent Prix'] = fb1.shift(1)
Examinons à nouveau la variable fb1 (les 10 premières valeurs par exemple) :
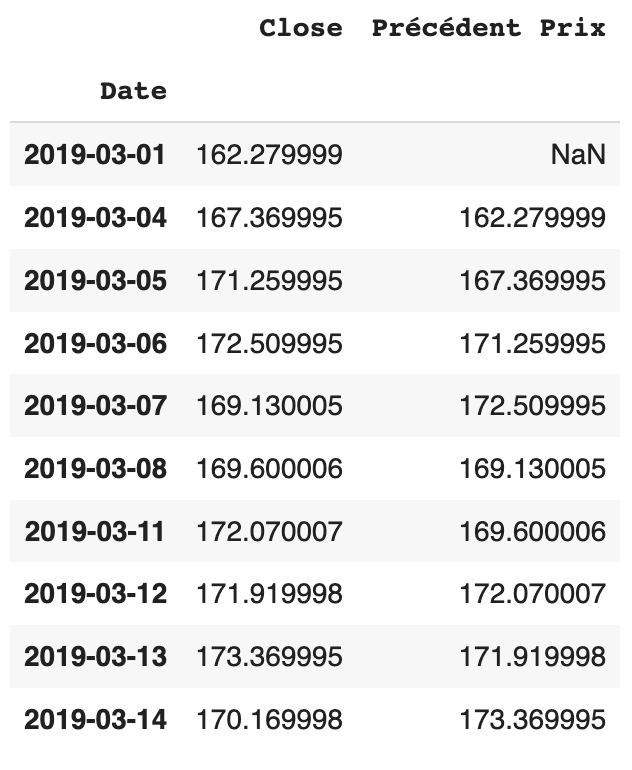
Dans les séries temporelles, on souhaite parfois trouver le pourcentage de variation en un jour. Trouvons maintenant la différence de valeurs en un jour :
fb1["Variation d'un jour"] = fb1['Close'] - fb1['Précédent Prix']
Regardons de nouveau la variable fb1 :
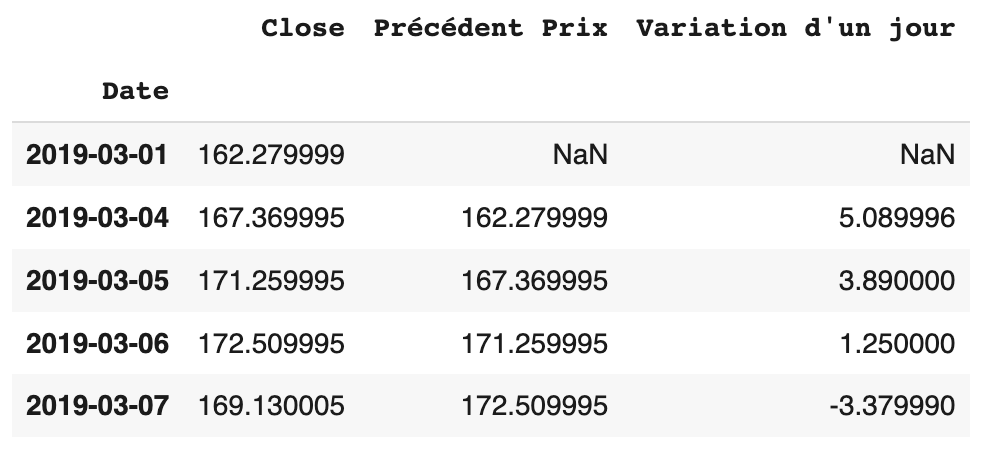
On peut souhaiter afficher le résultat en pourcentage :
fb1['% de variation'] = (fb1['Close'] - fb1['Précédent Prix']) * 100 / fb1['Précédent Prix']
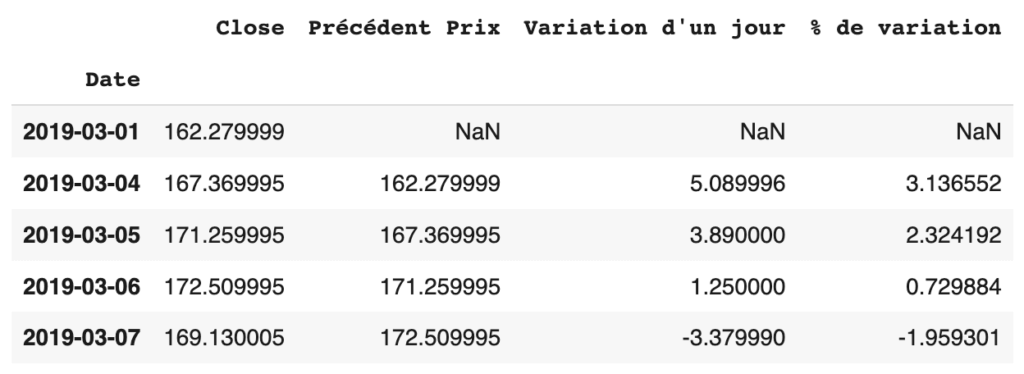
Regardons maintenant comment attribuer des fréquences à nos valeurs de date en index. Pour le montrer, prenons d’abord la colonne ‘Close’ (prix à la clôture).
Sélectionnons la colonne ‘Close’ :
fb2 = fb1[['Close']]
Examinons les premières lignes de la variable fb2 :
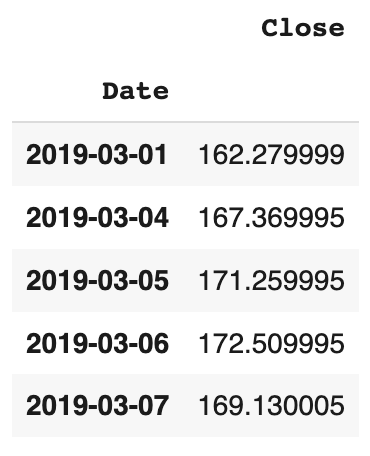
Examinons la structure de l’index de ces données.
fb2.index
DatetimeIndex(['2019-03-01', '2019-03-04', '2019-03-05', '2019-03-06',
'2019-03-07', '2019-03-08', '2019-03-11', '2019-03-12',
'2019-03-13', '2019-03-14', '2019-03-15', '2019-03-18',
'2019-03-19', '2019-03-20', '2019-03-21', '2019-03-22',
'2019-03-25', '2019-03-26', '2019-03-27', '2019-03-28',
'2019-03-29'],
dtype='datetime64[ns]', name='Date', freq=None)Note que les valeurs de date n’ont pas de valeur de fréquence. Attribuons des fréquences à ces index. Je vais utiliser la fonction date_range pour cela.
fb2.index = pd.date_range('2019-03-01', periods=21, freq='B')Examinons à nouveau les index des données fb2 :
DatetimeIndex(['2019-03-01', '2019-03-04', '2019-03-05', '2019-03-06',
'2019-03-07', '2019-03-08', '2019-03-11', '2019-03-12',
'2019-03-13', '2019-03-14', '2019-03-15', '2019-03-18',
'2019-03-19', '2019-03-20', '2019-03-21', '2019-03-22',
'2019-03-25', '2019-03-26', '2019-03-27', '2019-03-28',
'2019-03-29'],
dtype='datetime64[ns]', freq='B')Note que les dates se réfèrent à des jours ouvrables. Tu peux déplacer les indices vers l’avant ou vers l’arrière.
Opérations de fenêtrage de temps
Pandas comprend un ensemble compact d’API pour effectuer des opérations de fenêtrage de temps, une opération qui effectue une agrégation sur une partition glissante de valeurs. Les fonctions de l’API sont similaires à celles de l’API groupby.
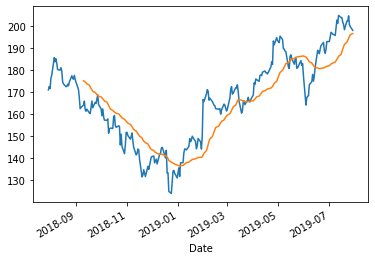
Les opérations de fenêtrage de temps sont utilisées pour lisser les données. Reprenons l’ensemble de données sur les actions Facebook et discutons de la fonction de roulement (rolling). Cette fonction est similaire aux méthodes groupby et resample. Tu peux regrouper les données à l’aide de la fonction rolling. Par exemple, rolling(30) implique la moyenne de 30 jours. Pour illustrer cela, traçons d’abord les prix de clôture de fb.
fb['Close'].plot()
Trouvons maintenant les moyennes sur 30 jours à l’aide de la fonction rolling et montrons ces valeurs sur le graphique.
fb['Close'].plot() fb['Close'].rolling(30).mean().plot()
Gestion du fuseau horaire
Comme tu le sais, chaque région du monde a un fuseau horaire différent. De nombreux chercheurs travaillent selon l’abréviation UTC international time.
La bibliothèque pytz est utilisée pour le fuseau horaire avec Python. Cette bibliothèque est fournie avec Anaconda (et pré-installé sur Google Colab). Tu peux également l’installer avec pip ou conda. Importons cette bibliothèque.
import pytz
Tu peux afficher la liste de tous les fuseaux horaires avec :
pytz.all_timezones
Par exemple, prenons le fuseau horaire de Paris en France.
pytz.timezone('Europe/Paris')<DstTzInfo 'Europe/Paris' LMT+0:09:00 STD>
Trouvons le fuseau horaire de la région américaine de New York.
pytz.timezone('America/New_York')<DstTzInfo 'America/New_York' LMT-1 day, 19:04:00 STD>
Par exemple, trouvons des lieux qui ont 7 heures de retard sur le fuseau horaire central.
pytz.common_timezones[-7:]
['US/Arizona', 'US/Central', 'US/Eastern', 'US/Hawaii', 'US/Mountain', 'US/Pacific', 'UTC']
Changement de fuseau horaire
Tu peux modifier le fuseau horaire de ton ensemble de données. Pour ce faire, créons un objet date.
x = pd.date_range('12/9/2022', periods=6, freq='D')Créons une série temporelle avec cet objet date :
ts = pd.Series(np.random.randn(len(x)), index=x)
Jetons un coup d’œil à cette variable ts :
2022-12-09 -2.453961 2022-12-10 0.431716 2022-12-11 0.256313 2022-12-12 0.655868 2022-12-13 -1.311629 2022-12-14 -1.002467 Freq: D, dtype: float64
Utilisons l’attribut tz pour contrôler le fuseau horaire de l’index :
print(ts.index.tz)
None
Les données ts n’ont pas de fuseau horaire. Assignons maintenant les plages de dates à ces données. Pour ce faire, tu peux utiliser la méthode .tz_localize().
ts_utc = ts.tz_localize('UTC')
ts_utc2022-12-09 00:00:00+00:00 -2.453961 2022-12-10 00:00:00+00:00 0.431716 2022-12-11 00:00:00+00:00 0.256313 2022-12-12 00:00:00+00:00 0.655868 2022-12-13 00:00:00+00:00 -1.311629 2022-12-14 00:00:00+00:00 -1.002467 Freq: D, dtype: float64
Si tu souhaites organiser la série temporelle en fonction d’une région particulière, tu peux utiliser la méthode .tz_convert(). Par exemple, définissons la série temporelle en fonction d’Hawaï :
ts_utc.tz_convert('US/Hawaii')2022-12-08 14:00:00-10:00 -2.453961 2022-12-09 14:00:00-10:00 0.431716 2022-12-10 14:00:00-10:00 0.256313 2022-12-11 14:00:00-10:00 0.655868 2022-12-12 14:00:00-10:00 -1.311629 2022-12-13 14:00:00-10:00 -1.002467 Freq: D, dtype: float64
Tu peux transformer ton dataset en fuseau horaire central international.
zstamp = pd.Timestamp('2022-06-26 09:00')
zstampTimestamp('2022-06-26 09:00:00')Convertissons cette heure en heure locale internationale :
zstamp_utc = zstamp.tz_localize('utc')
zstamp_utcTimestamp('2022-06-26 09:00:00+0000', tz='UTC')Convertissons maintenant cette heure locale en heure locale d’Istanbul :
zstamp_utc.tz_convert('Europe/Istanbul')Timestamp('2022-06-26 12:00:00+0300', tz='Europe/Istanbul')Si l’on combine deux séries temporelles dans des régions différentes, les résultats sont affichés en heure centrale-locale. Imprimons à nouveau la série temporelle ts :
2022-12-09 -2.453961 2022-12-10 0.431716 2022-12-11 0.256313 2022-12-12 0.655868 2022-12-13 -1.311629 2022-12-14 -1.002467 Freq: D, dtype: float64
Créons deux séries temporelles avec deux régions différentes :
ts1 = ts[:5].tz_localize('Europe/Berlin')
ts2 = ts[2:].tz_localize('Europe/Istanbul')Additionnons maintenant ces 2 séries temporelles.
result = ts1 + ts2
Examinons les index de la variable result :
result.index
DatetimeIndex(['2022-12-08 23:00:00+00:00', '2022-12-09 23:00:00+00:00',
'2022-12-10 21:00:00+00:00', '2022-12-10 23:00:00+00:00',
'2022-12-11 21:00:00+00:00', '2022-12-11 23:00:00+00:00',
'2022-12-12 21:00:00+00:00', '2022-12-12 23:00:00+00:00',
'2022-12-13 21:00:00+00:00'],
dtype='datetime64[ns, UTC]', freq=None)Ainsi, les index de result ont été imprimés en fonction de l’heure centrale-locale.
Conclusion
L’analyse des séries temporelles est très fréquemment utilisée dans les études financières. Dans cet article, j’ai expliqué comment utiliser les méthodes de ré-échantillonnage, de décalage et de fenêtrage, et comment travailler avec les fuseaux horaires. Tu peux trouver le notebook du code ici.
Et si tu es arrivé.e jusqu’à là, je te recommande de suivre mon programme complet sur l’analyse et la prévision de Séries Temporelles. C’est le seul programme en français que tu peux trouver sur les Time Series.