

Cet article vise à donner un aperçu des réseaux de neurones : j’y décris notamment les concepts fondamentaux.
Je tente de répondre avec vous aux questions suivantes:
- Qu’est-ce qu’un réseau de neurones ?
- Quelles sont les principales composantes des réseaux de neurones ?
- Comment fonctionnent les réseaux de neurones ?
- Qu’est-ce qu’une fonction d’activation ?
- Qu’est-ce que la rétro-propagation ?
- Quels sont les différents types de réseaux de neurones ?
Si vous souhaitez aller plus loin et construire un réseau de neurones en Python de A à Z, vous pouvez jeter un œil à ma formation: 5 projets complets et pratiques d’Intelligence artificielle en Python.
Qu’est ce qu’un réseau de neurones?
Tout d’abord, le réseau de neurones est un concept. Ce n’est pas physique. Le concept de réseaux de neurones artificiels (Artificial Neural Networks ANN) a été inspiré par les neurones biologiques. Dans un réseau de neurones biologiques, plusieurs neurones travaillent ensemble, reçoivent des signaux d’entrée, traitent des informations et déclenchent un signal de sortie.
Neurone biologique vs. neurone artificiel
Les réseaux de neurones tirent profit des expériences passées
Réseau de neurones d’Intelligence artificielle (IA)
Le réseau de neurones d’intelligence artificielle est basé sur le même modèle que le réseau de neurones biologique.

Bien que le concept sous-jacent soit le même que celui des réseaux biologiques, le réseau de neurones de l’IA est un groupe d’algorithmes mathématiques produisant une donnée de sortie (output) à partir des données d’entrée (input).
Ces algorithmes peuvent être groupés pour produire les résultats souhaités.
Dans un réseau de neurones d’IA, plusieurs algorithmes travaillent ensemble pour effectuer des calculs sur les données d’entrée afin de produire une donnée de sortie. Ces données de sortie peuvent également aider le réseau de neurones à apprendre et à améliorer leur précision.
Les réseaux de neurones sont entraînés avec une multitude de données d’entrées couplée à leurs données de sortie respectives. Ils calculent ensuite la donnée de sortie, ils la comparent à la donnée de sortie réelle connue et se mettent à jour en permanence pour améliorer les résultats (si nécessaire).
Les réseaux de neurones peuvent apprendre d’eux-mêmes
Au cours du temps, la donnée de sortie est utilisée pour améliorer la précision du modèle de notre réseau de neurones. Les réseaux de neurones peuvent aider les machines à identifier des modèles, des images et des données de séries chronologiques prévisionnelles.
Les informations textuelles sont généralement codées en nombres (binaires) et chaque bit est transmis à un seul neurone.
Quelles sont les principales composantes du réseau de neurones ?
Le réseau de neurones est composé des composants principaux suivants:
Neurones: ensemble de fonctions
Ils prennent une donnée d’entrée et produisent une donnée de sortie. Un certain nombre de neurones sont groupés en couches (ou layers). Tous les neurones du même groupe remplissent un type de fonction similaire.
Les neurones d’entrée reçoivent des données d’entrée, les traitent et les transmettent aux neurones dans la couche suivante. Les neurones cachés prennent les données de sortie des précédents neurones en entrée, calculent de nouvelles données de sortie et les transmettent à des couches successives.
Dans un réseau de neurones à plus de 3 couches (voir schéma ci-dessus), les neurones de la dernière couche cachée (hidden layer) transmettent les données de sortie en entrée des neurones de la couche de sortie (output layer). À partir de cela les neurones de la couche de sortie produisent les données de sortie finales.
Couches: groupement de neurones
Les couches (ou layers) contiennent des neurones et aident à faire circuler l’information. Il existe au moins deux couches dans un réseau de neurones: la couche d’entrée (input layer) et la couche de sortie (output layer).
Il est tout à fait possible d’avoir un (très) grand nombre de couches dans un réseau de neurones complexe. Plus il y aura de couches, plus le réseau sera profond (deep learning).
Les couches, autres que les couches d’entrée et de sortie, sont appelées les couches cachées (ou hidden layers).
Poids et biais: valeurs numériques
Les poids et biais sont des variables du modèle qui sont mises à jour pour améliorer la précision du réseau. Un poids est appliqué à l’entrée de chacun des neurones pour calculer une donnée de sortie.
Les réseaux de neurones mettent à jour ces poids de manière continue. Il existe donc une boucle de rétro-action mise en œuvre dans la plupart des réseaux de neurones.
Les biais sont également des valeurs numériques qui sont ajoutées une fois que les poids sont appliqués aux valeurs d’entrée. Les poids et les biais sont donc en quelque sorte des valeurs d’auto-apprentissage de nos réseaux de neurones.
Considérez le poids comme une donnée capitale pour un neurone.
Fonction d’activation: algorithmes mathématiques appliqués aux valeurs de sortie
Les fonctions d’activation lissent ou normalisent la donnée de sortie avant qu’elle ne soit transmise aux neurones suivants. Ces fonctions aident les réseaux de neurones à apprendre et à s’améliorer.
Le réseau de neurones est un concept d’apprentissage automatique modélisé par le cerveau biologique
Comment fonctionnent les réseaux de neurones?
Le concept de réseau de neurones repose sur trois étapes principales:
- Pour chaque neurone dans une couche, multiplier la valeur d’entrée par le poids.
- Ensuite, pour chaque couche, additionner toutes les pondérations des neurones et ajouter un biais.
- Enfin, appliquer la fonction d’activation sur cette valeur pour calculer une nouvelle sortie.
Comprendre le processus
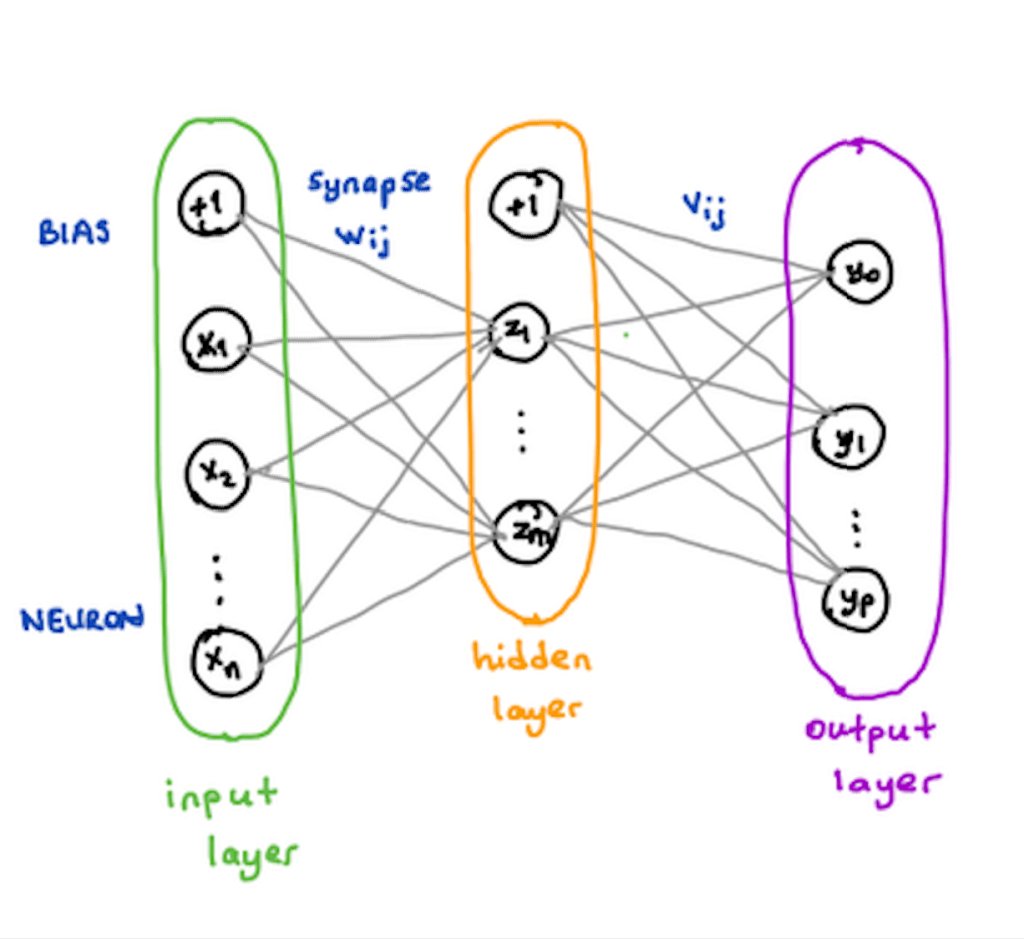
Soit X1, X2, …, Xn les n neurones de la couche d’entrée, Z1, …, Zm les m neurones de la couche cachée et Y1, …,Yp les p neurones de la couche de sortie. Soit 1 la valeur de biais des couches d’entrée et caché. Et soit Wij et Vij les poids synaptiques, respectivement entre la couche d’entrée et la couche cachée et entre la couche cachée et celle de sortie.
Chacun des neurones Xn de la couche d’entrée (ainsi que le biais) entre dans chacun des m neurones de la couche cachée et pareil pour la couche suivante (cf. schéma ci-dessus). Pour obtenir une valeur de sortie d’un neurone, le processus est le suivant:
- Chaque neurone est associé à un poids synaptique. Lorsqu’une donnée d’entrée entre dans un neurone, le poids sur le neurone est multiplié par sa valeur d’entrée.
- Ainsi on calcule la somme des poids multipliés par les valeurs d’entrée à laquelle on ajoute le biais.
- Enfin, une fonction d’activation (voir ci-dessous) est appliquée à cette somme pondérée. Cette valeur de sortie d’un neurone peut ensuite être renvoyée aux neurones de la couche suivante.
Qu’est-ce qu’une fonction d’activation ?
Comme son nom l’indique, la fonction d’activation est une formule mathématique (algorithme) activée dans certaines circonstances. Lorsque les neurones calculent la somme pondérée des valeurs d’entrée + le biais, elles sont transmises à la fonction d’activation, qui vérifie si la valeur calculée est supérieure au seuil requis.
Si la valeur calculée est supérieure au seuil requis, la fonction d’activation est activée et une valeur de sortie est calculée.
Cette valeur de sortie est ensuite transmise aux couches suivantes ou précédentes (en fonction de la complexité du réseau), ce qui peut aider les réseaux de neurones à modifier le poids de leurs neurones.

Les fonctions d’activation introduisent la non-linéarité dans les réseaux de neurones, nécessaires pour résoudre des problèmes complexes.
Si nous traçons les sorties non linéaires produites par les fonctions d’activation, nous obtiendrons une courbure. La pente de la courbe est utilisée pour calculer le gradient. Et le gradient nous aide à comprendre le taux de changement et les relations entre les variables.
À partir des relations, les algorithmes sont optimisés et les poids sont mis à jour.
Types de fonctions d’activation
Il existe un grand nombre de fonctions d’activation, telles que:
- Sigmoïde : produit une courbe en forme de S. Bien que de nature non linéaire, il ne tient toutefois pas compte des légères variations des entrées, ce qui entraîne des résultats similaires.
- Fonctions de tangente hyperbolique (tanh) : Il s’agit d’une fonction supérieure comparée à Sigmoid. Cependant, elle rend moins bien compte des relations et elle est plus lente à converger.
- Unité linéaire rectifiée (ReLu): Cette fonction converge plus rapidement, optimise et produit la valeur souhaitée plus rapidement. C’est de loin la fonction d’activation la plus populaire utilisée dans les couches cachées.
- Softmax : utilisé dans la couche de sortie car il réduit les dimensions et peut représenter une distribution catégorique.

Qu’est-ce que la rétro-propagation?
Le concept de rétro-propagation (back propagation) aide les réseaux de neurones à améliorer leur précision.
Dans les applications logicielles traditionnelles, un certain nombre de fonctions sont codées. Ces fonctions prennent des valeurs en entrée et produisent une valeur de sortie. Les entrées ne sont pas utilisées pour mettre à jour les instructions.
Cependant, les réseaux de neurones sont artificiellement intelligents. Ils peuvent apprendre et s’améliorer.
Lorsque les réseaux de neurones sont formés, une gamme de valeurs d’entrée est transmise avec la valeur de sortie attendue correspondante. Les fonctions d’activation produisent alors une sortie à partir de l’ensemble des entrées.
Rétro-propagation : aide le réseau de neurones à apprendre
Lorsque le résultat réel est différent du résultat attendu, les poids appliqués aux neurones sont mis à jour. Parfois, les résultats attendus et réels se situent dans les limites du seuil d’erreur et le réseau de neurones est considéré comme optimal.
Cependant, la sortie attendue est parfois différente de la sortie réelle. En conséquence, les informations sont renvoyées dans le réseau et les poids et biais sont améliorés. Ce processus est de nature récursive et est appelé rétro-propagation.
Le processus de rétro-propagation permet aux algorithmes d’auto-apprendre
Ainsi, la rétro-propagation rend les réseaux de neurones intelligents en s’améliorant automatiquement.
Quels sont les différents types de réseaux de neurones ?
Il existe différents types de réseaux de neurones. Les deux réseaux de neurones les plus populaires sont:
- Réseau de neurones récurrent – Recurrent Neural Network (RNN):
Ce sont des réseaux de neurones spécialisés qui utilisent le contexte des entrées lors du calcul de la sortie. La sortie dépend des entrées et des sorties calculées précédemment.
Ainsi, les RNN conviennent aux applications où les informations historiques sont importantes. Ces réseaux nous aident à prévoir les séries chronologiques dans les applications commerciales et à prévoir les mots dans les applications de type chatbot. Ils peuvent fonctionner avec différentes longueurs d’entrée et de sortie et nécessitent une grande quantité de données. - Réseau de neurones de convolution – Convolution Neural Network (CNN):
Ces réseaux reposent sur des filtres de convolution (matrices numériques). Les filtres sont appliqués aux entrées avant que celles-ci ne soient transmises aux neurones.
Ces réseaux de neurones sont utiles pour le traitement et la prévision d’images.
Conclusion
Dans cet article, j’ai présenté le concept de réseau de neurones (qu’est-ce que c’est et comment cela fonctionne).
De plus nous avons pu voir un aperçu des composants qui les rendent artificiellement intelligents.
Enfin, j’ai introduit les 2 types de réseaux de neurones les plus populaires.
Si vous souhaitez aller plus loin dans l’apprentissage et construire un réseau de neurones en Python de A à Z, vous pouvez jeter un œil à ma formation: 5 projets complets et pratiques d’Intelligence artificielle en Python.










Une bonne explication mais il est important d’ajouter des illustrations surtout pour les débutants. Merci en tout cas
J’ai utilisé quelques passages je veux mettre la source exacte:
auteur et la date.
merci
MonCoachData avec un lien vers le site moncoachdata.com 🙂
salut, merci pour cette article. j’ai été beaucoup édifié
toutefois, je n’arrive pas à accéder à la page concernant ” 5 projets complets et pratiques d’Intelligence artificielle en Python”. pourriez-vous m’orienter svp…..
cordialement
Merci Ulrich, j’ai mis à jour le lien du cours sur l’article, mais sinon tous les cours sont présents sur la page : https://moncoachdata.com/formation-data-science/ 🙂