Si tu travailles dans le domaine de la Data Science, quel que soit ton job, SQL est l’une des compétences les plus importantes que tu dois posséder. Je le placerais dans le top 3 avec Python. C’est pourquoi dans cet article, je te propose d’améliorer tes compétences SQL avec Python.
Lorsque j’ai commencé à apprendre la Data Science, j’ai trouvé qu’il était un peu difficile de mettre en place un environnement pour pratiquer le SQL. Je devais installer un moteur de base de données et un IDE pour écrire des requêtes, comme MySQL Workbench ou pgAdmin.
Cette configuration n’est pas très compliquée et il est probable que tu utilises ce type d’environnement lorsque tu travailleras dans le domaine de la Data Science. Cependant, il existe une option beaucoup plus simple pour s’entraîner lorsque tu commences à apprendre.
Cette option est sqlite3, qui est un module Python intégré. Il fournit une interface SQL facile à utiliser. Le module sqlite3 est basé sur SQLite, une bibliothèque en langage C qui fournit une base de données légère sur disque.
Puisque la plupart d’entre nous commencent leur voyage dans la Data Science en installant Python, pourquoi ne pas l’utiliser également pour apprendre SQL ?
Dans cet article, nous allons passer en revue plusieurs exemples pour apprendre à :
- Créer une base de données
- Créer des tables
- Alimenter les tables
- Interroger les tables
…avec le module sqlite3.
Création d’une base de données
La première étape consiste à créer une base de données. Nous pouvons utiliser la fonction connect pour cette tâche. Elle permet de se connecter à une base de données et, si la base de données n’existe pas, la fonction connect la crée également.
import sqlite3
con = sqlite3.connect("sample.db")L’étape suivante consiste à créer un curseur de base de données, nécessaire à l’exécution des instructions SQL et à la récupération des résultats.
cursor = con.cursor()
Nous pouvons voir les tables de cette base de données en utilisant la requête suivante et la fonction fetchall. Nous interrogeons essentiellement la table intégrée sqlite_master.
check_tables = """SELECT name FROM sqlite_master WHERE type='table';""" cursor.execute(check_tables) cursor.fetchall()
# sortie []
Comme la base de données ne contient aucune table, la fonction fetchall renvoie une liste vide.
Création de tables
Créons une table. Nous allons écrire la requête pour créer une table et utiliser le curseur pour l’exécuter.
create_products_table = """CREATE TABLE IF NOT EXISTS products (
id integer PRIMARY KEY,
category text NOT NULL,
price real,
cost real
);"""
cursor.execute(create_products_table)Vérifions à nouveau les tables de la base de données d’exemple.
check_tables = """SELECT name FROM sqlite_master WHERE type='table';""" cursor.execute(check_tables) cursor.fetchall()
# sortie
[('products',)]Nous voyons maintenant que la table products existe dans la base de données.
Nous pouvons exécuter n’importe quelle requête à l’aide du curseur. Par exemple, l’extrait de code suivant exécute la requête pour sélectionner toutes les lignes de la table products et affecte le résultat à une variable appelée result. Ensuite, la fonction fetchall est appelée sur la variable result pour voir ce qu’elle contient.
result = cursor.execute("SELECT * FROM products")
result.fetchall()# sortie
Elle ne renvoie rien puisque la table products est vide. Remplissons-la à l’aide de l’instruction insert into.
populate_products_table = """INSERT INTO products VALUES
(1001, 'A', 15.9, 12.9),
(1002, 'B', 24.9, 20.5),
(1003, 'A', 13.5, 10.6),
(1004, 'A', 17.5, 13.5),
(1005, 'B', 28.9, 23.5)
;"""
cursor.execute(populate_products_table)Note : L’instruction insert ouvre implicitement une transaction, qui doit être validée avant que les modifications ne soient enregistrées dans la base de données.
con.commit()
La table products devrait maintenant comporter 5 lignes. Confirmons en exécutant l’instruction select ci-dessus.
result = cursor.execute("SELECT * FROM products")
result.fetchall()# sortie [(1001, 'A', 15.9, 12.9), (1002, 'B', 24.9, 20.5), (1003, 'A', 13.5, 10.6), (1004, 'A', 17.5, 13.5), (1005, 'B', 28.9, 23.5)]
On peut bien sûr écrire des requêtes plus avancées. Par exemple, la requête suivante renvoie les lignes qui appartiennent à la catégorie A.
result = cursor.execute("SELECT * FROM products WHERE category='A'")
result.fetchall()# sortie [(1001, 'A', 15.9, 12.9), (1003, 'A', 13.5, 10.6), (1004, 'A', 17.5, 13.5)]
Une ligne de code pour créer un DataFrame Pandas
L’un des avantages du module sqlite3 est qu’il est compatible avec Pandas. Ainsi, nous pouvons facilement écrire les résultats d’une requête dans un DataFrame Pandas.
Nous pouvons appeler la fonction read_sql_query de Pandas avec la requête et l’objet de connexion.
products = pd.read_sql_query("SELECT * FROM products", con)
products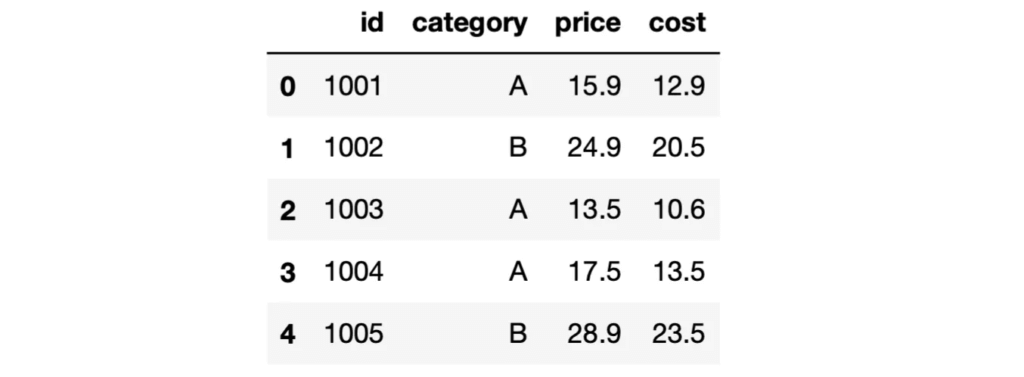
Créons une autre table et remplissons-la.
create_customers_table = """CREATE TABLE IF NOT EXISTS customers (
id integer PRIMARY KEY,
customer id integer NOT NULL,
is_member integer NOT NULL,
purchase_date text,
purchased_product integer,
purchase_quantity integer
);"""
populate_customer_table = """INSERT INTO customers VALUES
(1, 110, 0, "2022-12-23", 1002, 5),
(2, 112, 0, "2022-12-14", 1001, 4),
(3, 113, 1, "2022-12-08", 1003, 6),
(4, 113, 1, "2022-12-14", 1002, 4),
(5, 114, 0, "2022-12-21", 1004, 10)
;"""
cursor.execute(create_customers_table)
cursor.execute(populate_customer_table)
con.commit()Nous pouvons créer un DataFrame avec la table customers comme suit :
customers = pd.read_sql_query("SELECT * FROM customers", con)
customers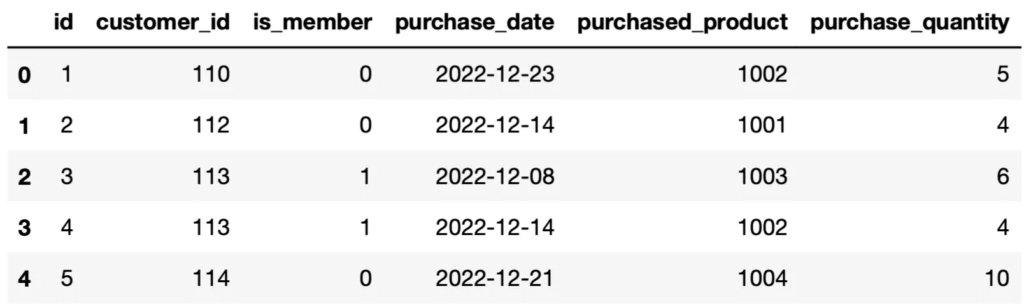
Requêtes plus complexes
Écrivons une requête qui récupère les données des tables products et customers. Elle comprendra une instruction de jointure.
query = '''
SELECT
customer_id,
purchased_product,
purchase_quantity,
price
FROM customers c
LEFT JOIN products p ON c.purchased_product = p.id
'''
cursor.execute(query)
cursor.fetchall()# sortie [(110, 1002, 5, 24.9), (112, 1001, 4, 15.9), (113, 1003, 6, 13.5), (113, 1002, 4, 24.9), (114, 1004, 10, 17.5)]
Tu peux utiliser l’attribut description pour voir les noms des colonnes dans le résultat de la requête :
cursor.description
# sortie
(('customer_id', None, None, None, None, None, None),
('purchased_product', None, None, None, None, None, None),
('purchase_quantity', None, None, None, None, None, None),
('price', None, None, None, None, None, None))
# enregistrer les noms dans une liste Python en utilisant la compréhension de liste col_names = [description[0] for description in cursor.description] col_names
# sortie ['customer_id', 'purchased_product', 'purchase_quantity', 'price']
Fermeture de la connexion
Nous pouvons utiliser la méthode close pour fermer la connexion actuelle à la base de données.
con.close()
Pour vérifier si les modifications sont enregistrées dans la base de données, nous pouvons créer une nouvelle connexion et écrire une requête pour vérifier.
con = sqlite3.connect("sample.db")
cursor = con.cursor()
result = cursor.execute("SELECT * FROM products")
result.fetchall()# sortie [(1001, 'A', 15.9, 12.9), (1002, 'B', 24.9, 20.5), (1003, 'A', 13.5, 10.6), (1004, 'A', 17.5, 13.5), (1005, 'B', 28.9, 23.5)]
Oui, les modifications ont été enregistrées dans la base de données sample.db.
Conclusion de tes nouvelles compétences SQL avec Python
Le module sqlite3 fournit un environnement facile à utiliser pour pratiquer le SQL, ce qui est d’une importance cruciale pour presque tous ceux qui travaillent dans l’écosystème de la Data Science.
Le fait de ne pas avoir à installer d’outil ou de moteur de base de données supplémentaire encourage encore plus l’utilisation de sqlite3. De plus, il suffit d’une ligne de code pour enregistrer le résultat d’une requête dans un DataFrame Pandas. Je pense qu’il s’agit d’une fonctionnalité très intéressante car Pandas est l’outil de manipulation et d’analyse de données le plus utilisé.
Tu peux également consulter 2 autres articles :