

L’exploration de sites Web n’est pas forcément difficile (surtout si tu connais Python). Pour démontrer cela, on va effectuer un Web Scraping avec Pandas. Quoi de mieux à quelques jours de la Coupe du Monde de Football de regarder les différents groupes de la compétition !
Les sites Web dynamiques peuvent être scrappés avec des bibliothèques telles que Selenium et Scrapy. Les sites Web simples peuvent être scrappés avec BeautifulSoup, et les sites Web super simples peuvent être scrappés avec seulement Pandas.
Et il suffit d’une ou deux lignes de code pour scrapper des sites Web avec Pandas !
Dans cet article, nous allons extraire des données de Wikipedia.
Nous allons extraire les tableaux des groupes de la Coupe du Monde de la FIFA 2022. Il y a 8 tableaux du groupe A au groupe H et nous allons les obtenir avec quelques lignes de code en utilisant Pandas et Python.
Tout d’abord, l’installation des bibliothèques et des dépendances
La première chose à faire est d’installer les bibliothèques que nous utiliserons pour ce tutoriel – pandas et string.
pandas sera utilisé pour extraire les données et le module string nous aidera à mieux organiser les données extraites.
pip install pandas pip install string
Note : Pour faire du web scrapìng avec pandas, nous devons également installer certaines dépendances telles que lxml et html5lib (nous pouvons les installer avec pip).
Une fois que ces bibliothèques sont installées sur nos ordinateurs, nous pouvons commencer avec ce tutoriel.
Scraping du site web (en une ligne de code)
Des sites Web simples comme Wikipédia peuvent être facilement récupérés en une ou deux lignes de code à l’aide de pandas.
Pour ce faire, nous devons d’abord importer pandas. Ensuite, il faut utiliser la méthode .read_html et écrire entre parenthèses le site web que l’on souhaite scrapper.
import pandas as pd
all_tables = pd.read_html("https://en.wikipedia.org/wiki/2022_FIFA_World_Cup")
C’est à peu près tout ! Toutes les tables du site Wikipedia sont maintenant stockées dans la liste all_tables.
Maintenant nous devons chercher les tableaux qui appartiennent aux groupes A, B, …H (8 tableaux au total).
Si nous naviguons à travers les éléments de la liste, nous verrons que les premier, deuxième et troisième tableaux sont respectivement aux indices 11, 18 et 25.
all_tables[11] all_tables[18] all_tables[25]
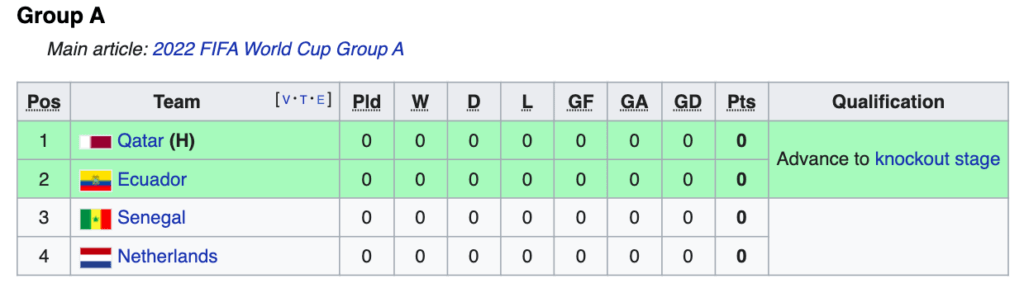
Voici à quoi ressemble le tableau du groupe C (indice 25).
Organisation des données
Si nous naviguons dans les index de la liste all_tables, nous constaterons que le premier tableau est à l’index 11 et que les tableaux suivants sont à 7 index d’avance.
Nous pouvons relier ces index avec le nom de chaque groupe en utilisant la fonction zip.
for letter, i in zip(alphabet, range(11, 67, 7)):
print(letter, i)
Le résultat sera le suivant :
A 11 B 18 C 25 D 32 E 39 F 46 G 53 H 60
Génial ! Nous savons maintenant que l’index 11 appartient au groupe A et que l’index 60 appartient au groupe H.
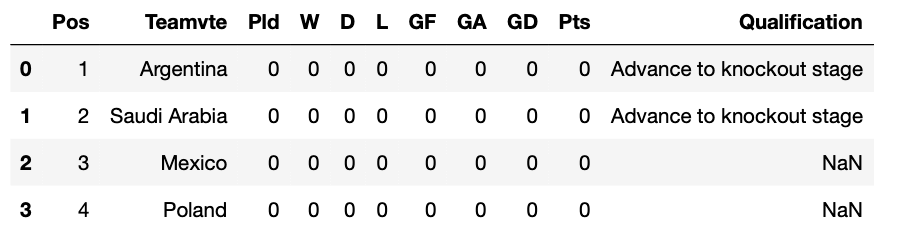
Il est temps de mieux organiser les tables extraites dans un dictionnaire, de sorte que nous n’ayons plus à nous occuper de ces affreux index. Nous allons également nettoyer les DataFrames en renommant le nom de la deuxième colonne “Teamvte” et en abandonnant la colonne “Qualification”.
dict_tables = {}
for letter, i in zip(alphabet, range(11, 67, 7)):
df = all_tables[i]
df.rename(columns={df.columns[1]: 'Team'}, inplace=True)
df.pop('Qualification')
dict_tables[f'Group {letter}'] = df
Voilà, c’est fait ! Nous avons maintenant toutes les tables stockées dans le dictionnaire dict_tables. Jetons-y un coup d’oeil :
dict_tables.keys()
dict_keys(['Group A', 'Group B', 'Group C', 'Group D', 'Group E', 'Group F', 'Group G', 'Group H'])
Maintenant, nous pouvons obtenir la table de n’importe quel groupe en spécifiant sa clé.
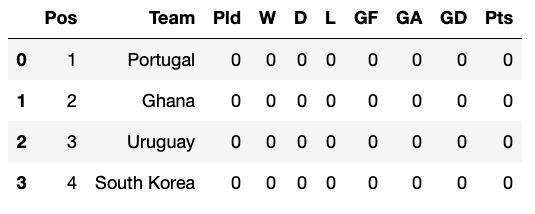
Voici comment nous allons procéder pour le groupe H :
dict_tables['Group H']
Et voici le résultat :
Félicitations ! tu as appris à scraper des sites Web avec Pandas. Voici tout le code que nous avons écrit dans ce tutoriel.
import pandas as pd
from string import ascii_uppercase as alphabet
all_tables = pd.read_html("https://en.wikipedia.org/wiki/2022_FIFA_World_Cup")
dict_tables = {}
for letter, i in zip(alphabet, range(11, 67, 7)):
df = all_tables[i]
df.rename(columns={df.columns[1]: 'Team'}, inplace=True)
df.pop('Qualification')
dict_tables[f'Group {letter}'] = df
# afficher toutes les clés
print(dict_tables.keys())
# tableau du groupe H
dict_tables['Group H']
Pour aller plus loin, je te recommande de suivre mon cours de Scraping (APIs et Web).











Bonjour et merci pour ce nouvel article. C’est vraiment un domaine qui m’intéresse. Puis je vous adresser un mail avec les anomalies que je rencontre ? Merci par avance pour votre réponse.
N’hésite pas à venir échanger sur le Discord 🙂