Pour maximiser la vitesse de tes requêtes sur n’importe quel moteur SQL, il est essentiel de comprendre l’ordre d’exécution SQL. Même si tu peux travailler sans cette connaissance, je te recommande de lire cet article pour en avoir une compréhension rapide.
Le moteur SQL ne suit pas le même ordre que celui que tu as défini dans ta requête, il est donc crucial de s’en souvenir. Par exemple, bien que nous commencions par une instruction SELECT, le moteur ne commencera pas par cette commande.
Dans cet article, nous allons examiner une requête complexe étape par étape pour comprendre comment le moteur SQL fonctionne en coulisses.
Important : tous les exemples sont réalisés sur PostgreSQL, les syntaxes peuvent donc varier d’un moteur à l’autre. Cependant, ce concept est applicable à tous les autres types de moteurs SQL.
Définir la requête
Pour cet exemple, j’aimerais parler d’une requête typique utilisée dans des flux de travail réels. Supposons que nous ayons une base de données pour les voitures avec une table pour les différents modèles, et que chaque modèle ait ses propres spécifications de moteur répertoriées dans une table séparée. Pour illustrer cela, nous pouvons créer des tables pour ce scénario.
DROP TABLE IF EXISTS cars, engines;
CREATE TABLE cars (
manufacturer VARCHAR(64),
model VARCHAR(64),
country VARCHAR(64),
engine_name VARCHAR(64),
year INT
);
CREATE TABLE engines (
name VARCHAR(64),
horse_power INT
);
INSERT INTO cars
VALUES
('BMW', 'M4', 'Germany', 'S58B30T0-353', 2021),
('BMW', 'M4', 'Germany', 'S58B30T0-375', 2021),
('Chevrolet', 'Corvette', 'USA', 'LT6', 2023),
('Chevrolet', 'Corvette', 'USA', 'LT2', 2023),
('Audi', 'R8', 'Germany', 'DOHC FSI V10-5.2-456', 2019),
('McLaren', 'GT', 'UK', 'M840TE', 2019),
('Mercedes', 'AMG C 63 S E', 'Germany', 'M139L', 2023);
INSERT INTO engines
VALUES
('S58B30T0-353', 473),
('S58B30T0-375', 510),
('LT6', 670),
('LT2', 495),
('DOHC FSI V10-5.2-456', 612),
('M840TE', 612),
('M139L', 469);
Pour atteindre notre objectif d’identifier les deux voitures les plus puissantes d’Allemagne, nous allons examiner des automobiles modernes qui n’ont pas plus de 8 ans d’âge. Pour ce faire, nous utiliserons des instructions SQL bien connues telles que SELECT, FROM, JOIN, WHERE, GROUP BY, HAVING, ORDER BY et LIMIT.
SELECT cars.manufacturer , cars.model , cars.country , cars.year , MAX(engines.horse_power) as maximum_horse_power FROM cars JOIN engines ON cars.engine_name = engines.name WHERE cars.year > 2015 AND cars.country = 'Germany' GROUP BY cars.manufacturer, cars.model, cars.country, cars.year HAVING MAX(engines.horse_power)> 200 ORDER BY maximum_horse_power DESC LIMIT 2
La sortie de cette requête est la suivante :

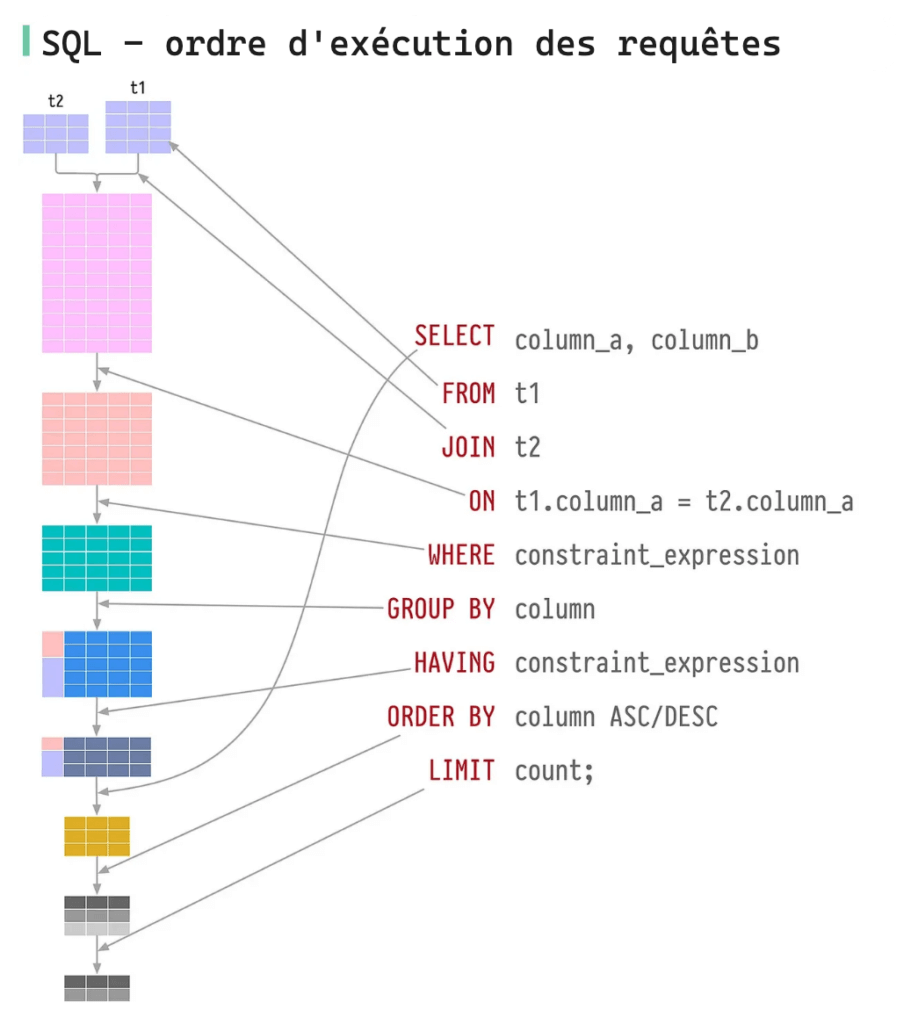
Maintenant que nous avons notre requête, comprenons comment le moteur les ordonne lors de l’exécution. Voici l’ordre :
- FROM
- JOIN (et ON)
- WHERE
- GROUP BY
- HAVING
- SELECT
- ORDER BY
- LIMIT
Il est important de noter qu’avant d’exécuter la requête, le moteur SQL crée un plan d’exécution afin de réduire la consommation de ressources. Ce plan contient des informations précieuses telles que les coûts estimés, les algorithmes de jointure, l’ordre des opérations, etc. Il s’agit d’un résultat complet, auquel on peut accéder si nécessaire.
Étape par étape
FROM et JOIN
FROM cars JOIN engines
Lorsqu’il lance une requête SQL, le moteur doit savoir quelles tables utiliser. Pour ce faire, il commence par une instruction FROM. Tu peux ajouter d’autres tables à l’aide du mot-clé JOIN, à condition qu’elles partagent une colonne commune qui sera utilisée dans la requête. Il s’agit d’un processus simple qu’il convient de garder à l’esprit.
ON
ON cars.engine_name = engines.name
La séquence suivante est ON, où nous définissons comment joindre différentes tables. Ce processus implique également l’utilisation d’indices prédéfinis, tels que B-tree et Bitmap, pour accélérer les calculs. Il est important de noter qu’il existe plusieurs types d’indices qui peuvent être utiles dans ce cas. Ces deux étapes requièrent une quantité considérable de traitement, il est donc crucial de se concentrer et de commencer à optimiser à ce stade.
WHERE
WHERE cars.year > 2015 AND cars.country = 'Germany'
Lorsque nous trions nos données, il est important de garder à l’esprit que l’utilisation de la clause WHERE uniquement avec des colonnes indexées peut améliorer les performances, en particulier lorsqu’il s’agit de grandes tables. En outre, il peut être intéressant de filtrer les données dans des sous-requêtes ou des CTEs avant l’instruction WHERE dans certains scénarios afin d’améliorer encore les performances.
Cependant, il est important de noter que de nombreux problèmes liés aux performances des requêtes dépassent le cadre de cet article. Je recommande d’approfondir ces problèmes et d’expérimenter diverses techniques pour écrire des requêtes plus rapides.
GROUP BY et HAVING
GROUP BY cars.manufacturer, cars.model, cars.country, cars.year HAVING MAX(engines.horse_power)> 200
Ensuite, nous devons suivre l’ordre spécifié dans la requête. Ensuite, nous devons déterminer toutes les agrégations nécessaires que nous devons effectuer. La clause HAVING est intrigante car nous ne pouvons pas utiliser d’alias à partir de la ligne SELECT. En effet, le moteur SQL ne connaît pas encore cette définition.
SELECT
SELECT cars.manufacturer , cars.model , cars.country , cars.year , MAX(engines.horse_power) as maximum_horse_power
Une fois toutes les étapes nécessaires terminées, nous avons exécuté l’instruction SELECT. À ce stade, nous avons simplement spécifié les colonnes à inclure dans la sortie finale. Il est important de garder à l’esprit que de nombreuses opérations, telles que la fusion et l’agrégation, ont déjà été effectuées à ce stade.
ORDER BY et LIMIT
ORDER BY maximum_horse_power DESC LIMIT 2
Lorsque nous exécutons les commandes finales, nous prenons connaissance des alias que nous avons mentionnés dans l’instruction SELECT. Par conséquent, nous pouvons utiliser l’alias maximum_horse_power au lieu du nom de la fonction, bien que nous puissions toujours utiliser ce dernier. Il est préférable d’éviter de trier une grande quantité de données, car cela peut prendre beaucoup de temps.
Conclusion
Pour bien comprendre le langage SQL et optimiser le processus de requête, il est important de noter que le moteur SQL ne travaille pas dans le même ordre que la requête. Cela peut t’aider à optimiser la fusion et le filtrage des données dans les étapes précédentes. Les articles suivants traiteront des indices et de la mesure des performances des requêtes, qui sont essentiels pour une optimisation efficace.