Pour cet article, nous avons un ensemble de données d’entrainement de 55 millions de courses en taxi à New York depuis 2009 et 9914 enregistrements pour les données de test. L’objectif de ce défi est de prédire le prix d’une course en taxi en fonction des informations sur les lieux de prise en charge et de dépose, de la date et de l’heure de la prise en charge et du nombre de passagers voyageant.
Dans tout projet d’analyse, 80 % du temps et des efforts sont consacrés au nettoyage des données, à l’analyse exploratoire et à l’obtention de nouvelles caractéristiques. Dans cet article, nous avons pour objectif de nettoyer les données, de visualiser la relation entre les variables et aussi de trouver de nouvelles caractéristiques qui permettent de mieux prévoir le prix des taxis.
Les données – Prédiction du prix des taxis : Analyse Exploratoire
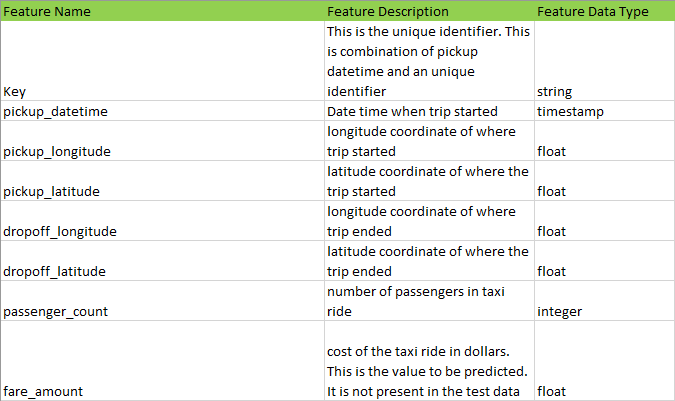
Les données relatives à ce problème sont disponibles sur Kaggle . Pour cette analyse, je n’ai importé que 6 millions de lignes sur les 55 millions de lignes des données relatives au set d’entrainement. Les champs qui sont présents dans les données sont les suivants :
Génération d’hypothèses
L’étape suivante pour résoudre tout problème d’analyse consiste à dresser une liste d’hypothèses, qui dans notre cas sont des facteurs qui influeront sur le coût d’une course en taxi.
- Distance du trajet : si la distance à parcourir est plus grande, le prix du trajet devrait être plus élevé.
- Durée du trajet : aux heures de pointe, le prix du taxi peut être plus élevé.
- Jour du voyage : Le montant du tarif peut varier en semaine et le week-end.
- Conditions météorologiques : S’il neige, la disponibilité des taxis peut être moindre et donc les tarifs plus élevés.
- Les trajets depuis/vers l’aéroport : Les trajets depuis/vers l’aéroport ont généralement un tarif fixe.
- Quartier de départ ou d’arrivée : le tarif peut varier en fonction du type de quartier.
- Disponibilité des taxis : si un endroit particulier dispose de nombreux taxis, les tarifs peuvent être plus bas.
Nettoyage de données et Exploration
Dans cette section, nous examinerons les différentes étapes utilisées pour nettoyer les données et comprendre la relation entre les variables et utiliser cette compréhension pour créer de meilleures caractéristiques.
1. Répartition du montant de la course
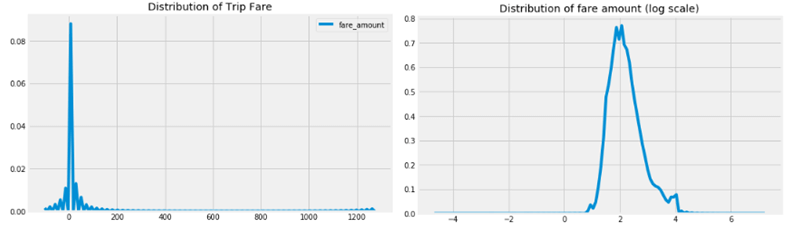
Nous avons d’abord examiné la répartition du montant du tarif et avons constaté qu’il y avait 262 enregistrements où le tarif était négatif. Comme le coût d’un voyage ne peut pas être négatif, nous avons supprimé ces cas des données. Pour mieux comprendre la répartition du montant de la course, nous avons effectué une transformation logarithmique après avoir supprimé les tarifs négatifs, ce qui a permis d’obtenir une répartition proche de la normale.
2. Répartition des caractéristiques géographiques
La gamme des latitudes et des longitudes se situe respectivement entre -90 à 90 et -180 à 180. Mais dans l’ensemble des données d’entrainement, nous avons observé des latitudes et des longitudes dans une fourchette de (-3488.079513, 3344.459268), ce qui n’est pas possible. Lors d’une exploration plus approfondie, nous avons également identifié un ensemble de 114K enregistrements qui avaient à la fois des coordonnées de lieux de prise et de dépose à l’Equateur. Comme ces données concernent des trajets en taxi à New York, nous avons supprimé ces lignes de notre analyse. De telles anomalies n’ont pas été trouvées dans les données de test.
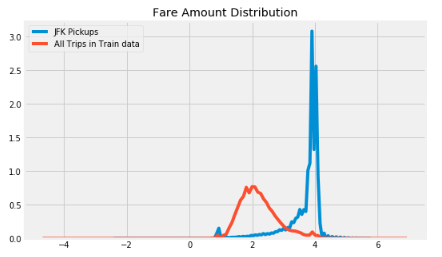
Nous avons ensuite examiné le montant moyen des tarifs pour les transferts vers JFK, par rapport à tous les voyages dans les données d’entrainement, et nous avons constaté que les tarifs étaient plus élevés pour les voyages à l’aéroport. Sur la base de ces observations, nous avons créé des caractéristiques permettant de vérifier si une prise de client ou un dépôt se faisait vers l’un des trois aéroports de New York – JFK, EWR ou LaGuardia.
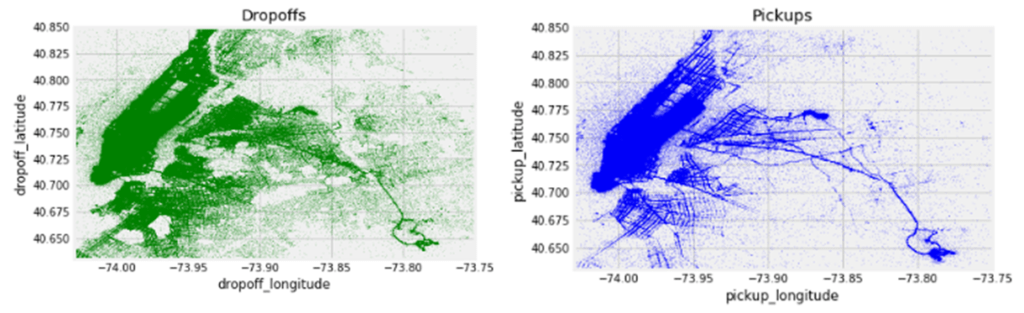
L’étape suivante a consisté à vérifier si notre hypothèse de tarif de certains quartiers est supérieure au reste, en se basant sur les 5 Boroughs de la ville de New York qui est divisé entre – Manhattan, Queens, Brooklyn, Staten Island et Bronx, chaque lieu de prise en charge et de dépose a été regroupé dans ces 5 quartiers. Et oui, notre hypothèse était juste – sauf pour Manhattan, où se trouvait la plupart des lieux de prise en charge et de dépôt. Pour chaque autre quartier, il y avait une différence dans la répartition des tarifs de prise en charge et de dépôt. De plus, le Queens avait un tarif moyen de prise en charge plus élevé que les autres quartiers.

3. Répartition de la distance de trajet
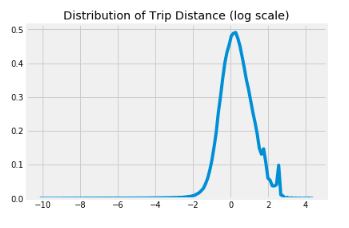
En utilisant les coordonnées de prise en charge et de dépôt, nous calculons la distance du voyage en miles sur la base de la distance Haversine. La distance du trajet, tout comme le montant du tarif suit la distribution de la longue queue, nous prenons une transformation logarithmique pour la rendre proche de la distribution normale
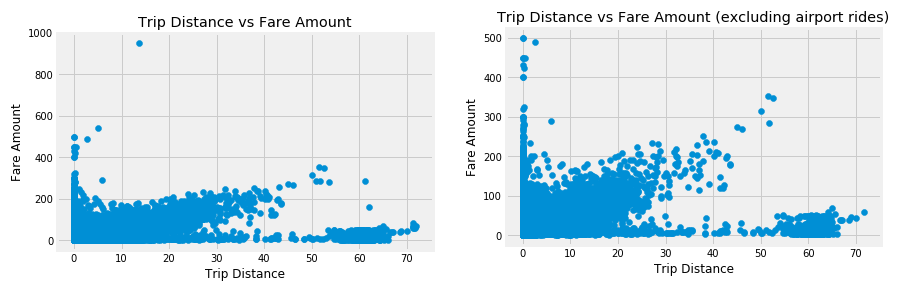
Une de nos hypothèses était que le montant du tarif devrait idéalement augmenter avec la distance du trajet. Un diagramme de dispersion entre la distance du trajet et le montant du tarif a montré que, bien qu’il y ait une relation linéaire, le tarif par mile (pente) était plus bas, et il y avait beaucoup de trajets dont la distance était supérieure à 50 miles, mais le tarif était très bas. Pour vérifier si c’était le cas en raison des trajets à l’aéroport, nous avons supprimé les trajets à l’aéroport et avons tracé la distribution. Nous avons ensuite observé que le tarif par mile était plus élevé et un autre petit groupe de trajets dont la distance était supérieure à 50 miles a été observé.
L’étape suivante consistait à voir s’il existait une région particulière où la distance de déplacement > 50 miles était observée. Cela a montré qu’il y avait beaucoup de prises en charge et de dépôts dans le bas de Manhattan. Cela a conduit à une nouvelle caractéristique – pickup_is_lower_manhattan et dropoff_is_low_manhattan.
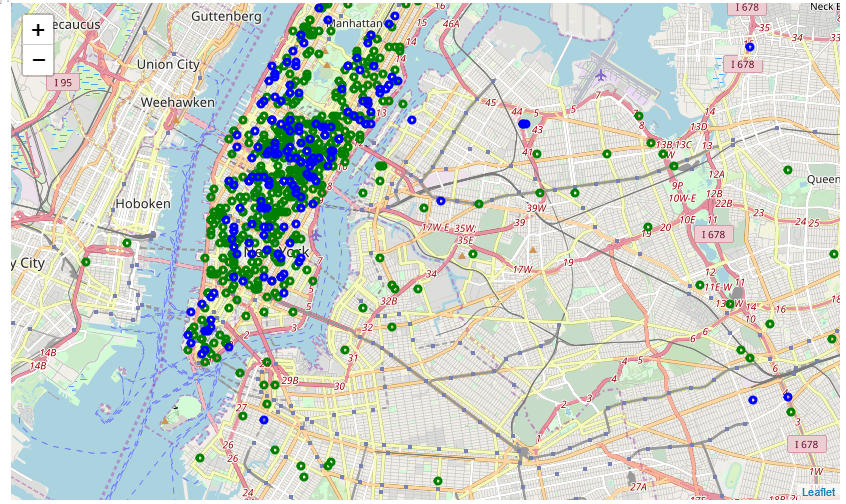
4. Répartition de l’heure et date de prise en charge
La première étape pour analyser l’évolution des tarifs dans le temps consiste à créer des caractéristiques telles que l’heure, le jour de la semaine, le jour, le mois, l’année à partir de la date de prise en charge. Le code permettant d’extraire ces caractéristiques est le suivant :
train['pickup_datetime']=pd.to_datetime(train['pickup_datetime'],format='%Y-%m-%d %H:%M:%S UTC') train['pickup_date']= train['pickup_datetime'].dt.date train['pickup_day']=train['pickup_datetime'].apply(lambda x:x.day) train['pickup_hour']=train['pickup_datetime'].apply(lambda x:x.hour) train['pickup_day_of_week']=train['pickup_datetime'].apply(lambda x:calendar.day_name[x.weekday()]) train['pickup_month']=train['pickup_datetime'].apply(lambda x:x.month) train['pickup_year']=train['pickup_datetime'].apply(lambda x:x.year)
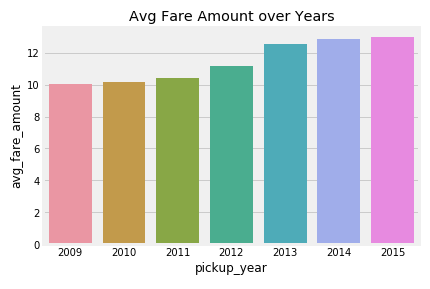
Comme prévu, le prix moyen du taxi a augmenté au cours des années.
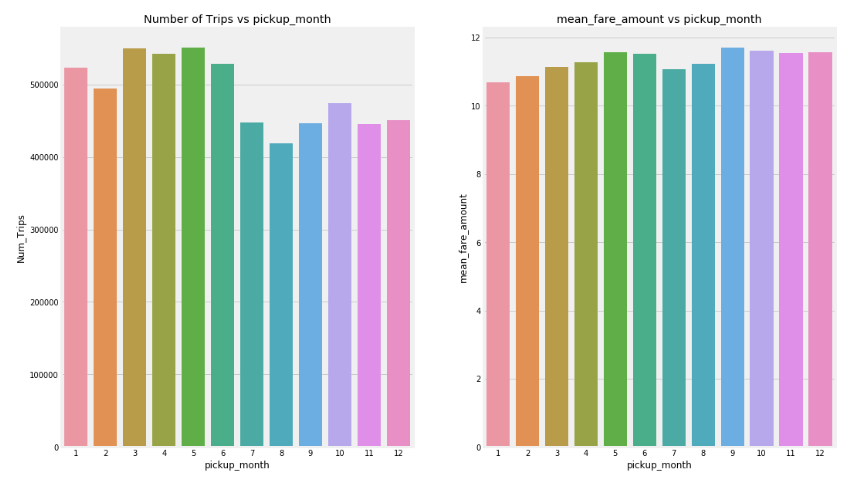
Au fil des mois, bien qu’il y ait eu moins de prises en charge de juillet à décembre, le tarif moyen est presque constant d’un mois à l’autre
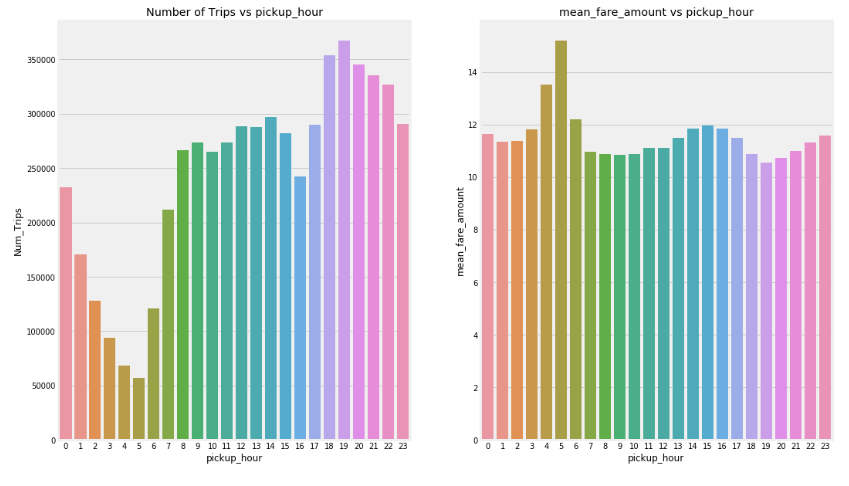
Nous avons observé que si le nombre de prises en charge est plus élevé le samedi, le montant moyen du tarif est plus faible. Le dimanche et le lundi, bien que le nombre de trajets soit plus faible, le tarif moyen est plus élevé.

Le tarif moyen à 5 heures du matin est le plus élevé, tandis que le nombre de voyages à 5 heures du matin est le plus faible. En effet, à 5 heures du matin, 83 % des trajets sont effectués vers l’aéroport, le nombre de trajets étant le plus élevé en 18 et 19 heures.
Notes de fin
Sur la base des caractéristiques créées à l’aide de cette analyse exploratoire, le modèle de base utilisant XGBoost a obtenu un RMSE de 3,03760 sur le tableau des leaders publics, qui se situe dans le percentile des 15 premiers. Le code de cet article est disponible en cliquant ici.
Dans la deuxième partie de cet article, nous verrons comment nous pouvons utiliser les caractéristiques identifiées à l’aide de cette analyse exploratoire pour créer des modèles de Machine Learning et comprendre comment évaluer les modèles. J’espère que vous avez trouvé cet article utile et qu’il vous a aidé à prendre confiance pour résoudre ce défi sur Kaggle. Comme toujours, toutes les discussions et suggestions sont les bienvenues.