

Pandas est une bibliothèque populaire d’analyse et de manipulation de données pour Python. La structure de données de base de Pandas est le DataFrame qui stocke les données sous forme de tableau avec des lignes et des colonnes étiquetées. Voici un guide pratique pour effectuer des analyses de données efficaces contenant 8 façons de filtrer un DataFrame Pandas.
Une opération courante dans l’analyse de données consiste à filtrer les valeurs en fonction d’une ou de plusieurs conditions. Pandas propose plusieurs façons de filtrer les points de données (c’est-à-dire les lignes). Dans cet article, nous allons aborder 8 façons différentes de filtrer un DataFrame Pandas.
Nous commençons par importer les bibliothèques :
import numpy as np import pandas as pd
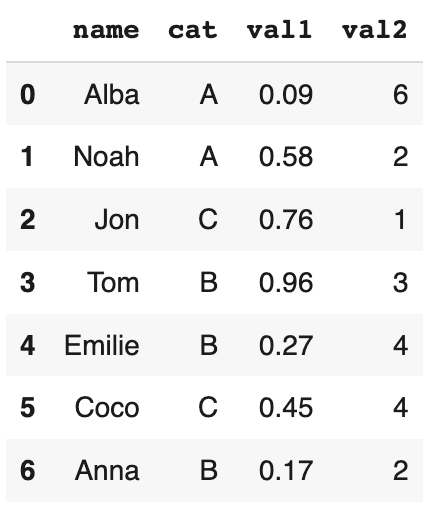
Créons un DataFrame pour voir nos différents exemples :
df = pd.DataFrame({
'prénom':['Alba','Noah','Jon','Tom','Emilie','Coco','Anna'],
'catégorie':['A','A','C','B','B','C','B'],
'valeur1':np.random.random(7).round(2),
'valeur2':np.random.randint(1,10, size=7)
})
Top 8 des façons de filtrer un DataFrame Pandas
1. Opérateurs logiques
Nous pouvons utiliser les opérateurs logiques sur les valeurs des colonnes pour filtrer les lignes.
df[df.val1 > 0.5]
name cat val1 val2 ------------------------------------------- 1 Noah A 0.58 2 2 Jon C 0.76 1 3 Tom B 0.96 3
Nous avons sélectionné les lignes dans lesquelles la valeur de la colonne “val1” est supérieure à 0,5.
Les opérateurs logiques fonctionnent également sur les chaînes de caractères (strings).
df[df.name > 'Jon']
name cat val1 val2 ------------------------------------------- 1 Noah A 0.28 6 3 Tom B 0.07 5
Seuls les prénoms qui suivent “Jon” dans l’ordre alphabétique sont sélectionnés.
2. Opérateurs logiques multiples
Pandas permet de combiner plusieurs opérateurs logiques. Par exemple, nous pouvons appliquer des conditions sur les colonnes val1 et val2 comme ci-dessous.
df[(df.val1 > 0.5) & (df.val2 == 1)]
name cat val1 val2 ------------------------------------------- 2 Jon C 0.76 1
Le signe “&” signifie “et” et le signe “|” signifie “ou”.
df[(df.val1 < 0.5) | (df.val2 == 3)]
name cat val1 val2 ------------------------------------------- 0 Alba A 0.09 6 3 Tom B 0.96 3 4 Emilie B 0.27 4 5 Coco C 0.45 4 6 Anna B 0.17 2
3. isin
La méthode isin est une autre façon d’appliquer des conditions multiples pour le filtrage. Par exemple, nous pouvons filtrer les prénoms qui existent dans une liste donnée.
names = ['Jon','Noah','Emilie'] df[df.name.isin(names)]
name cat val1 val2 ------------------------------------------- 1 Noah A 0.58 2 2 Jon C 0.76 1 4 Emilie B 0.27 4
4. Accesseur Str
Pandas est également une bibliothèque très efficace pour les données textuelles. Les fonctions et méthodes de l’accesseur str offrent des moyens flexibles de filtrer les lignes sur la base de chaînes de caractères string.
Par exemple, nous pouvons sélectionner les prénoms qui commencent par la lettre “A”.
df[df.name.str.startswith('A')]name cat val1 val2 ------------------------------------------- 0 Alba A 0.09 6 6 Anna B 0.17 2
La fonction contains de l’accesseur str renvoie les valeurs qui contiennent un ensemble donné de caractères.
df[df.name.str.contains('a')]name cat val1 val2 ------------------------------------------- 0 Alba A 0.09 6 1 Noah A 0.58 2 6 Anna B 0.17 2
Nous pouvons également transmettre un ensemble plus long de caractères à la fonction contains en fonction des chaînes de caractères présentes dans les données.
5. Tilde (~)
L’opérateur tilde est utilisé pour la logique “not” dans le filtrage. Si nous ajoutons l’opérateur tilde avant l’expression du filtre, les lignes qui ne correspondent pas à la condition sont renvoyées.
df[~df.name.str.startswith('A')]name cat val1 val2 ------------------------------------------- 1 Noah A 0.58 2 2 Jon C 0.76 1 3 Tom B 0.96 3 4 Emilie B 0.27 4 5 Coco C 0.45 4
On prend les noms qui ne commencent pas par la lettre “A”.
6. Query
La fonction query offre un peu plus de flexibilité pour écrire les conditions de filtrage. Nous pouvons transmettre les conditions sous forme de chaîne de caractères string.
Par exemple, le code suivant renvoie les lignes qui appartiennent à la catégorie B et dont la valeur est supérieure à 0,5 dans la colonne val1.
df.query('cat == "B" and val1 > 0.5')name cat val1 val2 ------------------------------------------- 3 Tom B 0.96 3
7. nlargest ou nsmallest
Dans certains cas, nous ne disposons pas d’une plage spécifique pour le filtrage mais avons simplement besoin des valeurs les plus grandes ou les plus petites. Les fonctions nlargest et nsmallest permettent de sélectionner les lignes qui ont les plus grandes ou les plus petites valeurs dans une colonne, respectivement.
df.nlargest(3, 'val1')
name cat val1 val2 ------------------------------------------- 3 Tom B 0.96 3 2 Jon C 0.76 1 1 Noah A 0.58 2
Nous spécifions le nombre de valeurs les plus grandes ou les plus petites à sélectionner et le nom de la colonne.
df.nsmallest(2, 'val2')
name cat val1 val2 ------------------------------------------- 2 Jon C 0.76 1 1 Noah A 0.58 2
8. loc et iloc
Les méthodes loc et iloc sont utilisées pour sélectionner des lignes ou des colonnes sur la base d’un index ou d’un label / étiquette.
- loc : sélectionne les lignes ou les colonnes à l’aide des labels / étiquettes
- iloc : sélectionne des lignes ou des colonnes à l’aide de l’index
Elles peuvent donc être utilisées pour le filtrage. Cependant, nous ne pouvons sélectionner qu’une partie particulière du DataFrame sans spécifier de condition.
df.iloc[3:5, :] # lignes 3 et 4, toutes les colonnes
name cat val1 val2 ------------------------------------------- 3 Tom B 0.96 3 4 Emilie B 0.27 4
Si le DataFrame a un index constitué d’entiers, les index et les labels des lignes seront les mêmes. Ainsi, loc et iloc s’utiliseront de la même manière sur les lignes (iloc prend tous les labels).
df.loc[3:5, :] # lignes 3 à 5, toutes les colonnes
name cat val1 val2 ------------------------------------------- 3 Tom B 0.96 3 4 Emilie B 0.27 4 5 Coco C 0.45 4
Mettons à jour l’index du DataFrame pour mieux souligner la différence entre loc et iloc.
df.index = ['a','b','c','d','e','f','g']
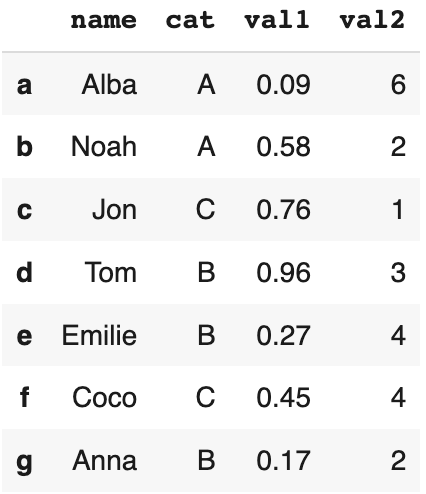
Nous ne pouvons plus passer des entiers à la méthode loc maintenant car les labels de l’index sont maintenant des lettres (string).
df.loc['b':'d', :]
name cat val1 val2 ------------------------------------------- b Noah B 0.58 2 c Jon C 0.76 1 d Tom B 0.96 3 b Noah A 0.58 2 c Jon C 0.76 1 d Tom B 0.96 3
Conclusion
Nous avons abordé 8 façons différentes de filtrer les lignes d’un DataFrame Pandas. Toutes sont utiles et se révèlent très pratiques dans des cas particuliers.
Pandas est une bibliothèque puissante pour l’analyse et la manipulation des données. Elle fournit de nombreuses fonctions et méthodes pour manipuler les données sous forme de tableaux. Comme pour tout autre outil, la meilleure façon d’apprendre Pandas, c’est de s’exercer. Pour en lire plus sur des cas concrets et pratiques sur Pandas, je vous recommande aussi de lire : 10 astuces Pandas et 12 fonctions Pandas et NumPy à ne pas manquer !
Merci de votre lecture. N’hésitez pas à me faire part de vos commentaires.










Merci très intéressant