

Le Data Cleaning (nettoyage de données) est l’étape la plus importante avant d’analyser ou modéliser des données mais elle peut-être très fastidieuse.
Plaçons-nous dans le contexte, c’est le début d’un nouveau projet et vous êtes impatient d’appliquer certains modèles de Machine Learning. Vous examinez les données et vous réalisez rapidement que c’est la cata: les données ne sont absolument pas exploitables en l’état.
Pour être tout à fait honnête, vous pouvez régulièrement vous attendre à consacrer jusqu’à 80% de votre temps à nettoyer les données.
Dans cet article, nous allons parcourir un certain nombre de tâches de Data Cleaning à l’aide de la bibliothèque Pandas de Python. Plus précisément, nous allons nous concentrer sur la plus grande tâche du Data Cleaning, à savoir le traitement des valeurs manquantes.
Après avoir lu cet article, vous pourrez nettoyer plus rapidement les données. Et à choisir, nous voulons tous passer moins de temps à nettoyer les données et plus de temps à explorer et modéliser 🙂
Sources de valeurs manquantes
Avant de littéralement nous immerger dans le code, il est important de comprendre d’où proviennent les valeurs manquantes. Voici quelques cas typiques pour lesquels des données sont manquantes:
- L’utilisateur a oublié de remplir un champ
- Les données ont été perdues lors du transfert manuel d’une base de données existante
- Il y a eu une erreur de programmation
- Les utilisateurs ont volontairement choisi de ne pas renseigner un champ lié à leurs convictions sur la manière dont les résultats pourraient être utilisés ou interprétés (vie privée, etc.).
Comme vous pouvez le constater, certaines de ces sources ne sont que de simples erreurs aléatoires. Et parfois, la raison d’une donnée manquante est plus profonde.
Il est important de comprendre ces différents types de données manquantes d’un point de vue statistique. Le type de données manquantes influera sur la manière dont vous remplirez les valeurs manquantes.
Aujourd’hui, nous allons apprendre à détecter les valeurs manquantes et à procéder à une imputation de base. Pour une approche statistique détaillée permettant de traiter les valeurs manquantes, consultez ces superbes diapositives de Matt Brems.
N’oubliez pas que l’imputation avec une valeur médiane ou moyenne (même si régulièrement utilisée) n’est pas toujours la meilleure idée. Veillez donc à consulter les diapositives de Matt pour connaître la bonne approche.
Introduction aux données
Avant de commencer à nettoyer un dataset, il est judicieux d’avoir un aperçu des données. Après cela, vous pouvez élaborer le plan de nettoyage de données.
J’aime commencer par me poser les questions suivantes:
- Quelles sont les caractéristiques?
- Quels sont les types attendus (int, float, string, boolean)?
- Y a-t-il des valeurs manquantes évidentes (valeurs que la bibliothèque pandas peut détecter)?
- Existe-t-il d’autres types de valeurs manquantes moins évidentes (impossible à détecter avec pandas)?
Pour vous montrer ce que je veux dire, commençons par l’exemple.
Les données avec lesquelles nous allons travailler constituent un très petit ensemble de données immobilières (seulement quelques lignes) mais contenant des valeurs manquantes, youpii! Voici une copie du fichier csv afin que vous puissiez coder et expérimenter les méthodes de cet article.
Il s’agit d’un ensemble de données beaucoup plus petit que ceux avec lequel vous avez l’habitude de travailler. Même s’il s’agit d’un petit ensemble de données, il met en évidence un grand nombre de situations réelles que vous rencontrerez.
Pour avoir une idée rapide des données, vous pouvez jeter un coup d’œil aux premières lignes:
# Importer les bibliothèques
import pandas as pd
import numpy as np
# Lire le fichier csv dans un dataframe pandas
df = pd.read_csv("property data.csv")
# Afficher les premières lignes
print(df.head())
ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS 0 104.0 PUTNAM Y 3.0 1 197.0 LEXINGTON N 3.0 2 NaN LEXINGTON N 3.0 3 201.0 BERKELEY NaN 1.0 4 203.0 BERKELEY Y 3.0
Maintenant, je peux répondre à ma question initiale, quelles sont mes caractéristiques?
Il est assez facile de déduire les caractéristiques suivantes à partir des noms de colonne:
- ST_NUM: numéro de rue
- ST_NAME: nom de la rue
- OWN_OCCUPIED: le propriétaire occupe le bien?
- NUM_BEDROOMS: nombre de chambres
Nous pouvons également répondre à la question “quels sont les types de données attendus”?
- ST_NUM: float ou int… (type numérique)
- ST_NAME: chaîne de caractères string
- OWN_OCCUPIED: string… Y pour “Oui” ou N pour “Non”
- NUM_BEDROOMS: float ou int (type numérique)
Pour répondre aux deux questions suivantes, nous devrons commencer à creuser un peu plus les fonctionnalités offertes par la bibliothèque pandas. Voyons maintenant des exemples de détection des valeurs manquantes.
Nettoyage de données : Valeurs manquantes standards
Qu’est-ce que je veux dire par “valeurs manquantes standard”? Ce sont des valeurs manquantes que Pandas peut détecter immédiatement.
Revenons à notre dataset original. Jetons un coup d’œil à la colonne “Street Number” (ST_NUM).

A la troisième ligne, il y a une cellule vide. À la septième ligne, il y a une valeur “NA”.
Clairement, ce sont les deux seules valeurs manquantes. Voyons comment pandas traite ces problèmes.
# Affichage de la colonne ST_NUM print(df['ST_NUM'])
0 104.0 1 197.0 2 NaN 3 201.0 4 203.0 5 207.0 6 NaN 7 213.0 8 215.0
# Affichage des valeurs nulles print(df['ST_NUM'].isnull())
0 False 1 False 2 True 3 False 4 False 5 False 6 True 7 False 8 False
En regardant la colonne, nous pouvons voir que pandas a rempli le champ vide avec la valeur “NA”. En utilisant la méthode isnull(), nous pouvons confirmer que la cellule vide et “NA” ont été reconnus comme des valeurs manquantes. Ce qui retourne les 2 valeurs “True”.
Ceci est un exemple simple qui met en évidence un point important. Pandas reconnaît les valeurs vides et celles de type “NA” comme des valeurs manquantes.
Dans la section suivante, nous examinerons quelques types que Pandas ne reconnaîtra pas.
Nettoyage de données : Valeurs manquantes non-standards
Parfois, cela peut être le cas sur des valeurs manquantes qui ont des formats différents.
Jetons un coup d’œil à la colonne “Number Bedrooms” (NUM_BEDROOMS), ce sera plus parlant.

Dans cette colonne, il y a quatre valeurs manquantes.
- n / a
- NA
- —
- na
Dans la section précédente, nous avons vu que Pandas reconnaît “NA” comme une valeur manquante, mais qu’en est-il des autres? Regardons cela dès maintenant.
# Affichage de la colonne NUM_BEDROOMS print(df['NUM_BEDROOMS'])
0 3 1 3 2 n/a 3 1 4 3 5 NaN 6 2 7 -- 8 na
# Affichage des valeurs nulles print(df['NUM_BEDROOMS'].isnull())
0 False 1 False 2 False 3 False 4 False 5 True 6 False 7 False 8 False
Comme précédemment, Pandas a reconnu le “NA” comme une valeur manquante. Malheureusement, les autres types ne sont pas reconnus, il les prend pour des valeurs cohérentes de la colonne du nombre de chambres.
Si plusieurs utilisateurs entrent manuellement des données, il s’agit d’un problème courant. Peut-être que j’utilise “n/a” mais que vous utilisez “na”. Et pourtant cela a la même signification de valeur manquante.
Un moyen simple de détecter ces différents formats consiste à les répertorier. Ensuite, lorsque nous importons des données, Pandas les reconnaîtra immédiatement. Voici un exemple de la façon dont nous ferions cela:
# Faire une liste de types de valeurs manquantes
missing_values = ["n/a", "na", "--"]
df = pd.read_csv("property data.csv", na_values = missing_values)
Okay examinons de nouveau la colonne NUM_BEDROOMS
print(df['NUM_BEDROOMS'])
0 3.0 1 3.0 2 NaN 3 1.0 4 3.0 5 NaN 6 2.0 7 NaN 8 NaN
print(df['NUM_BEDROOMS'].isnull())
0 False 1 False 2 True 3 False 4 False 5 True 6 False 7 True 8 True
Cette fois, tous les différents formats ont été reconnus comme des valeurs manquantes.
Vous ne pourrez peut-être pas les distinguer tous immédiatement. Lorsque vous travaillez sur les données et que vous voyez d’autres types de valeurs manquantes, vous pouvez les ajouter à la liste.
Il est important de reconnaître ces types non-standards de valeurs manquantes afin d’analyser et de transformer les valeurs manquantes. Si vous essayez de compter le nombre de valeurs manquantes avant de convertir ces types non standard, vous risquez d’oublier beaucoup de valeurs manquantes.
Dans la section suivante, nous examinerons un type de valeur manquante plus complexe, mais très courant.
Nettoyage de données : Valeurs manquantes inattendues
Jusqu’à présent, nous avons vu des valeurs manquantes standards et des valeurs manquantes non-standards. Mais que se passe t-il si nous avons un 3e type “inattendu”?
Par exemple, si notre caractéristique doit être constituée normalement d’une chaine de caractères string mais qu’à la place on ait une donnée numérique. On peut dire que techniquement il s’agit d’une valeur manquante.
Jetons un coup d’œil à la colonne “Owner Occupied” (OWN_OCCUPIED) pour bien saisir la nuance.
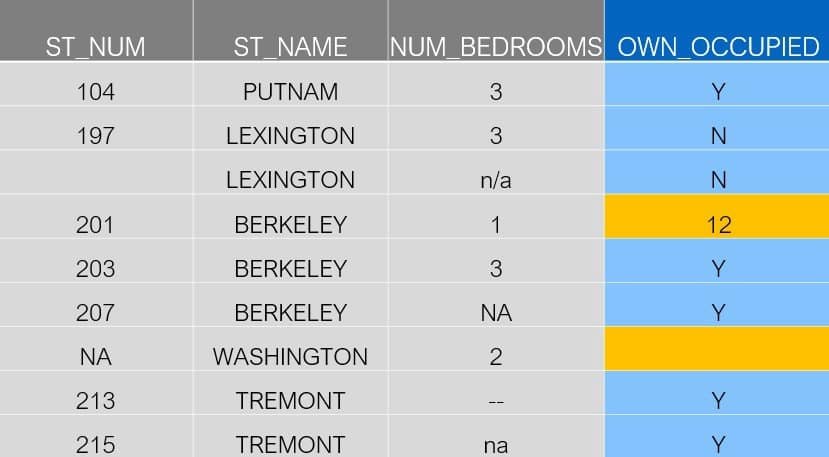
D’après nos exemples précédents, nous savons que pandas détectera la cellule vide de la ligne sept comme une valeur manquante. On va le confirmer avec le même code que précédemment.
print(df['OWN_OCCUPIED'])
0 Y 1 N 2 N 3 12 4 Y 5 Y 6 NaN 7 Y 8 Y
print(df['OWN_OCCUPIED'].isnull())
0 False 1 False 2 False 3 False 4 False 5 False 6 True 7 False 8 False
Dans la quatrième ligne, il y a le nombre 12. La réponse à la question ‘est-ce que le propriétaire réside dans le logement?’ doit clairement être une chaîne de caractères (Y/oui ou N/non), ce type numérique doit donc être considéré une valeur manquante.
Cet exemple est un peu plus compliqué, nous devons donc réfléchir à une stratégie pour détecter ces types de valeurs manquantes. Il existe différentes approches, mais voici comment je vais procéder pour celle-ci.
- Boucle sur la colonne OWN_OCCUPIED
- Essayez de transformer chaque élément en un entier
- Si celui-ci peut être transformé en un entier, on remplace l’élément par une valeur manquante connue (NaN).
- Si le nombre ne peut pas être converti en un entier, nous savons alors par déduction qu’il s’agit d’une chaîne de caractères, alors on continue de parcourir la boucle.
Regardons ce que ça donne avec du code:
# Détection de nombres
cnt=0
for row in df['OWN_OCCUPIED']:
try:
int(row)
df.loc[cnt, 'OWN_OCCUPIED']=np.nan
except ValueError:
pass
cnt+=1
Dans ce code, nous parcourons chaque entrée de la colonne “Owner Occupied” (OWN_OCCUPIED). Pour essayer de changer l’élément correspondant à l’itération de la boucle en un entier, nous utilisons int(row).
Si la valeur peut être changée en un entier, nous modifions l’entrée en une valeur manquante à l’aide de np.nan de Numpy.
D’autre part, s’il ne peut pas être changé en un entier, nous utiliser pass pour continuer.
Vous remarquerez que j’ai utilisé try et except ValueError. C’est ce qu’on appelle la gestion des exceptions, nous l’utilisons pour gérer les erreurs.
Si nous essayons de changer une entrée en un entier et que cela ne peut pas être changé, alors une ValueError sera renvoyée et le code s’arrêtera. Pour y remédier, nous utilisons la gestion des exceptions pour reconnaître ces erreurs et continuer tout de même la boucle jusqu’à la fin.
Un autre élément important du code est la méthode .loc. C’est la méthode Pandas idéale pour modifier les éléments de la colonne. Pour plus d’informations à ce sujet, vous pouvez consulter la documentation pandas.DataFrame.loc.
Maintenant que nous avons exploré les différentes manières de détecter les valeurs manquantes, nous allons examiner comment les analyser et les remplacer.
Nettoyage de données : Analyser les valeurs manquantes
Après avoir nettoyé les valeurs manquantes, nous voudrons probablement les analyser. Par exemple, nous pourrions vouloir examiner le nombre total de valeurs manquantes pour chaque caractéristique.
# Nombre total de valeurs manquantes pour chaque caractéristique print(df.isnull().sum())
ST_NUM 2 ST_NAME 0 OWN_OCCUPIED 2 NUM_BEDROOMS 4
Ou alors, nous voudrons peut-être faire une vérification rapide pour voir s’il nous reste des valeurs manquantes.
# des valeurs manquantes? print(df.isnull().values.any())
True
Nous pourrions également vouloir obtenir un nombre total de valeurs manquantes.
# Nombre total de valeurs manquantes print(df.isnull().sum().sum())
8
Maintenant que nous avons analysé le nombre de valeurs manquantes, examinons quelques méthodes de remplacement simples.
Nettoyage de données : Remplacement
Souvent, vous devrez trouver comment vous voulez gérer les valeurs manquantes.
Parfois, vous voudrez simplement supprimer ces lignes, parfois les remplacer.
Comme je l’ai dit plus tôt, cela ne doit pas être pris à la légère. Nous allons passer en revue certaines imputations de base, mais pour une approche statistique détaillée permettant de traiter les données manquantes, consultez les slides de Matt Brems.
Cela étant dit, peut-être voulez-vous simplement renseigner les valeurs manquantes avec une seule valeur.
# Remplacer les valeurs manquantes par un nombre df['ST_NUM'].fillna(125, inplace=True)
Plus probablement, vous voudrez peut-être faire une imputation basée sur la position d’une valeur manquante. Voici comment vous feriez cela.
# Remplacement basée sur une position df.loc[2,'ST_NUM'] = 125
Un moyen très courant de remplacer les valeurs manquantes consiste à utiliser la médiane.
# Remplacer en utilisant la médiane median = df['NUM_BEDROOMS'].median() df['NUM_BEDROOMS'].fillna(median, inplace=True)
Ce ne sont que des méthodes très simples pour remplacer les valeurs manquantes, mais assurez-vous de consulter la page de Matt pour connaître les techniques appropriées dans chaque cas.
Conclusion
Traiter des données inexploitables car en désordre est inévitable. Le nettoyage des données (Data Cleaning) ne constitue qu’une partie du processus d’un projet de Data Science.
Dans cet article, nous avons présenté quelques méthodes pour détecter, analyser et remplacer les valeurs manquantes.
Armés de ces techniques, vous passerez moins de temps à nettoyer les données et plus de temps à vous amuser en explorant et en modélisant ces données 🙂











Merci pour ce contenu très édifiant.
Vous avez fait un très bon boulot, une explication claire et concise. Je vous en félicite
wow merci pour ton commentaire plein de bienveillance :))
Très intéressant merci
Un très bon travail, très bien expliqué
Un grand Merci.
merci beucoup
très interressant
Merci Moussa 🙂
intéressants , est il possible d’avoir un sujet traitant le remplacement des valeurs manquantes dans un dataset avec deux groupe de colonnes d’un coté les colonnes des variables quantitatives et de l’autre coté les variables qualitatives sans utiliser les transformateurs mais directe. j’ai fait le code suivant mais j’ai pas réussi à l’assemblé en un seule pour traiter un seul dataset avec ces caractéristiques pré-cités.
si = SimpleImputer(strategy=’mean’)
df[quanti_col] = si.fit_transform(df[quanti_col])
sic = SimpleImputer(strategy=’most_frequent’)
df[quali_col] = sci.fit_transform(df[quali_col])
?????????????
ici qu’est ce qu’il faut mettre pour l’assembler en un seul
afin de permettre de traiter le modèle .
MERCI
Rejoins le Discord pour discuter de ça 🙂