

En apprenant la programmation avec le langage Python, vous vous rendrez surement compte du nombre croissant de techniques d’analyse et d’utilisation de données. Le Machine Learning (ou Apprentissage Automatique) est sans doute l’un des domaines que vous souhaitez maîtriser (puisque vous êtes sur cette page).
Le Machine Learning vous permet de faire des prédictions en introduisant des données dans des algorithmes complexes. Les utilisations du Machine Learning sont infinies, ce qui en fait une compétence majeure à ajouter à votre CV.
Dans ce tutoriel, je vous explique les principes de base du Machine Learning et comment vous familiariser avec le Machine Learning avec Python. Heureusement pour nous, Python possède un incroyable écosystème de bibliothèques qui facilitent l’application du Machine Learning. Nous utiliserons les excellentes bibliothèques Scikit-learn, Pandas et Matplotlib dans ce tutoriel. Si vous souhaitez approfondir le Machine Learning et posséder tous les fondamentaux, je vous invite à regarder cette formation complète en cliquant ici.
Le Data Set
Avant de nous lancer dans le Machine Learning, nous allons explorer un dataset (ou jeu de données) et déterminer ce qui pourrait être intéressant à prédire.
Le dataset est de BoardGameGeek, et contient des données sur 80000 jeux de société. Voici un exemple de jeu de société sur le site ici. Toutes ces données ont été scrapées au format csv par Sean Beck et peuvent être téléchargées ici. Le dataset contient plusieurs informations sur chaque jeu de société. Voici une liste des plus intéressants:
- name – nom du jeu de société.
- playtime – le temps de jeu (donné par le fabricant).
- minplaytime – le temps de jeu minimum (donné par le fabricant).
- maxplaytime – la durée de jeu maximale (indiquée par le fabricant).
- minage – l’âge minimum recommandé pour jouer.
- users_rated – le nombre d’utilisateurs qui ont évalué le jeu.
- average_rating – la note moyenne attribuée au jeu par les utilisateurs. (0-10)
- total_weights – Nombre de poids donnés par les utilisateurs. Le poids est une mesure subjective constituée par BoardGameGeek. En quelque sorte, ça décrit le niveau d’engagement ou d’implication d’un jeu. Voici une explication complète ici.
- average_weight – la moyenne de tous les poids subjectifs (0-5).
Python : introduction à la bibliothèque Pandas
La première étape de notre exploration consiste à lire les données et à afficher rapidement quelques statistiques sommaires. Pour ce faire, nous allons utiliser la bibliothèque Pandas. Pandas fournit des structures de données et des outils d’analyse de données permettant de manipuler les données beaucoup plus rapidement et efficacement qu’avec Python. La structure de données la plus courante est appelée un DataFrame. Il s’agit d’une extension d’une matrice, nous allons donc discuter de ce qu’est une matrice avant de revenir aux DataFrames.
Notre fichier de données ressemble à ceci (j’ai supprimé certaines colonnes pour faciliter la lecture) :
id,type,name,yearpublished,minplayers,maxplayers,playingtime 12333,boardgame,Twilight Struggle,2005,2,2,180 120677,boardgame,Terra Mystica,2012,2,5,150
Ceci est dans un format appelé csv pour comma-separated values (ou valeurs séparées par des virgules). Chaque ligne de données est un jeu de société différent et des informations différentes relatives à chaque jeu de société sont séparées par des virgules dans la ligne. La première ligne est la ligne d’en-tête et décrit chaque information. L’ensemble complet d’une information ou caractéristique, en descendant chacune des valeurs, est une colonne.
Nous pouvons facilement conceptualiser un fichier csv en tant que matrice :
| id | type | name | yearpublished | minplayers | maxplayers | playingtime |
|---|---|---|---|---|---|---|
| 12333 | boardgame | Twilight Struggle | 2005 | 2 | 2 | 180 |
| 120677 | boardgame | Terra Mystica | 2012 | 2 | 5 | 150 |
J’ai supprimé certaines des colonnes ici à des fins d’affichage, ça vous donne une idée de l’aspect visuel des données. Une matrice est une structure de données bi-dimensionnelle, avec des lignes et des colonnes. Nous pouvons accéder aux éléments d’une matrice par position.
La première ligne commence par id, la deuxième ligne commence par 12333 et la troisième ligne par 120677.
La première colonne est id, la seconde est type, etc.
Les matrices en Python peuvent être utilisées via la bibliothèque NumPy. Une matrice a cependant quelques inconvénients. Vous ne pouvez pas accéder facilement aux colonnes et aux lignes par leur nom, et chaque colonne doit avoir le même type de données. Cela signifie que nous ne pouvons pas stocker efficacement les données de nos jeux de société dans une matrice – la colonne name contient des chaînes de caractères ‘string’ et la colonne yearpublished contient des entiers ‘integer’, ce qui signifie que nous ne pouvons pas les stocker tous les deux dans la même matrice.
Un DataFrame, en revanche, peut avoir différents types de données dans chaque colonne. Il comporte de nombreuses fonctionnalités intégrées pour l’analyse des données, telles que la recherche de colonnes par leur nom. Pandas nous donne accès à ces fonctionnalités et simplifie le travail avec les données.
Lire nos données
Nous allons maintenant lire nos données d’un fichier csv dans un DataFrame Pandas, en utilisant la méthode read_csv.
# Importer la bibliothèque pandas.
import pandas
# Lire les données.
games = pandas.read_csv("board_games.csv")
# Afficher les noms de colonnes du DataFrame games.
print(games.columns)
Index(['id', 'type', 'name', 'yearpublished', 'minplayers', 'maxplayers',
'playingtime', 'minplaytime', 'maxplaytime', 'minage', 'users_rated',
'average_rating', 'bayes_average_rating', 'total_owners',
'total_traders', 'total_wanters', 'total_wishers', 'total_comments',
'total_weights', 'average_weight'],
dtype='object')
Le code ci-dessus lit les données et affiche tous les noms de colonnes. Les colonnes qui figurent dans les données mais que je n’ai pas répertoriées ci-dessus sont assez explicites.
print(games.shape)
(81312, 20)
Nous pouvons également voir la dimension du DataFrame, ce qui montre qu’il possède 81312 lignes (ou jeux de sociétés) et 20 colonnes (ou caractéristiques) décrivant chaque jeu.
Tracer nos variables cibles
Il pourrait être intéressant de prédire le score moyen qu’un humain attribuerait à un nouveau jeu de société inédit. Ceci est stocké dans la colonne average_rating, qui correspond à la moyenne de toutes les notes des utilisateurs pour un jeu de société. Prédire cette caractéristique pourrait être utile, par exemple, aux fabricants de jeux de société qui réfléchissent au type de jeu à créer. Nous pouvons accéder à une colonne d’un DataFrame Pandas en utilisant games[“average_rating”]. Cela extraira une seule colonne du DataFrame. Traçons un histogramme de cette colonne afin de pouvoir visualiser la distribution des notations. Nous allons utiliser Matplotlib pour générer la visualisation. Matplotlib est la principale bibliothèque de traçage que vous découvrirez en apprenant la programmation Python. La plupart des autres bibliothèques de traçage, telles que seaborn et ggplot2, sont construites à partir de Matplotlib. Nous importons les fonctions de traçage de Matplotlib avec la commande import matplotlib.pyplot as plt. Nous pouvons ensuite dessiner et afficher les graphiques.
# Importer matplotlib import matplotlib.pyplot as plt # Histogramme de toutes les notes de la colonne average_rating. plt.hist(games["average_rating"]) # Afficher le graphique plt.show()
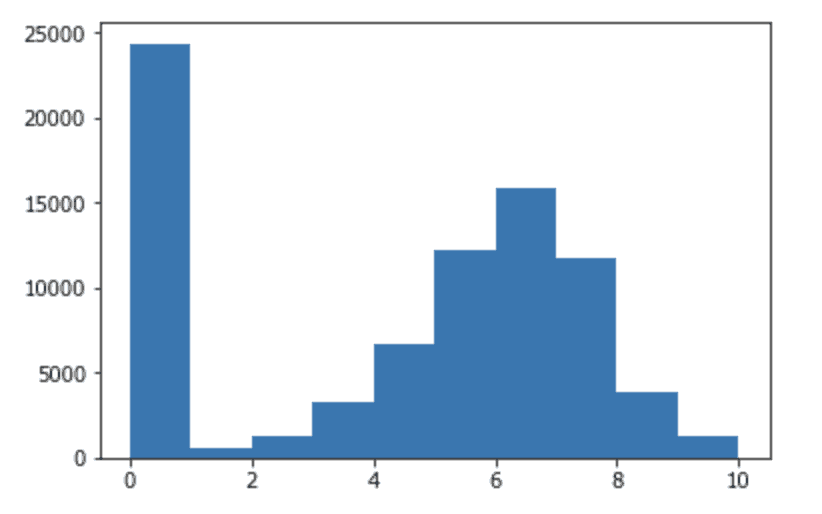
Ce que nous voyons ici, c’est qu’il y a pas mal de jeux de société avec une note de 0. Il existe une répartition assez normale des notations, avec quelques biais à droite, et une notation moyenne autour de 6 (si vous supprimez les zéros).
Exploration des notes de 0
Y at-il vraiment autant de jeux très mauvais qui ont reçu la note de 0? Ou est-ce qu’il se passe autre chose? Nous devrons nous pencher davantage sur les données pour vérifier cela. Avec Pandas, nous pouvons sélectionner des sous-ensembles de données à l’aide de d’objets Series de type booléen (les vecteurs ou une colonne / ligne d’un DataFrame, sont appelés objets Series Pandas).
Voici un exemple:
games[games["average_rating"] == 0]
Le code ci-dessus créera un nouveau DataFrame, avec uniquement les lignes de games où la valeur de la colonne average_rating est égale à 0. Nous pouvons ensuite indexer le DataFrame résultant pour obtenir les valeurs souhaitées. Il existe deux manières d’indexer dans pandas: nous pouvons indexer par le nom de la ligne ou de la colonne ou par la position. L’indexation par noms ressemble à games[“average_rating”] – cela retournera la colonne entière de average_rating de games. L’indexation par position ressemble à games.iloc[0]. La première ligne du DataFrame est retournée. Nous pouvons également transmettre plusieurs valeurs d’index à la fois – games.iloc[0,0] retournera la première colonne de la première ligne de games (En savoir plus sur l’indexation dans pandas ici).
# Afficher la première ligne du DataFrame games avec des notes de 0. # La méthode .iloc sur des dataframes nous permet d'indexer par position. print(games[games["average_rating"] == 0].iloc[0]) # Afficher la première ligne de tous les jeux de sociétés dont la note est supérieure à 0. print(games[games["average_rating"] > 0].iloc[0])
id 318 type boardgame name Looney Leo yearpublished 0 minplayers 0 maxplayers 0 playingtime 0 minplaytime 0 maxplaytime 0 minage 0 users_rated 0 average_rating 0 bayes_average_rating 0 total_owners 0 total_traders 0 total_wanters 0 total_wishers 1 total_comments 0 total_weights 0 average_weight 0 Name: 13048, dtype: object id 12333 type boardgame name Twilight Struggle yearpublished 2005 minplayers 2 maxplayers 2 playingtime 180 minplaytime 180 maxplaytime 180 minage 13 users_rated 20113 average_rating 8.33774 bayes_average_rating 8.22186 total_owners 26647 total_traders 372 total_wanters 1219 total_wishers 5865 total_comments 5347 total_weights 2562 average_weight 3.4785 Name: 0, dtype: object
Cela nous montre que la principale différence entre un jeu de société avec une note de 0 et un jeu avec une note supérieure à 0 c’est que le jeu classé 0 n’a aucun commentaire. La colonne users_rated est 0. En filtrant tous les jeux de société avec 0 avis, nous pouvons supprimer une bonne partie du “bruit”.
Supprimer les jeux de société ne possédant aucun review
# Supprime chaque ligne sans aucun review utilisateur. games = games[games["users_rated"] > 0] # Supprime les lignes contenant des valeurs manquantes. games = games.dropna(axis=0)
Nous venons de filtrer toutes les lignes sans aucun avis d’utilisateurs. Pendant que nous y étions, nous avons également supprimé toutes les lignes avec des valeurs manquantes. De nombreux algorithmes de Machine Learning ne peuvent pas traiter les valeurs manquantes. Nous avons donc besoin d’un moyen de les gérer. Les filtrer est une technique courante, mais cela signifie que nous pouvons potentiellement perdre des données précieuses. Il eexiste encore plein d’autres techniques permettant de traiter les données manquantes.
Classification des jeux de société
Nous avons vu qu’il peut y avoir des jeux de sociétés bien distincts. Un ensemble (que nous venons de supprimer) était l’ensemble de jeux sans aucune critique. Un autre ensemble pourrait être un ensemble de jeux avec de très bonnes notes… Une technique pour en savoir plus sur ces jeux est une technique appelée clustering. La mise en cluster vous permet de rechercher facilement des modèles dans vos données en regroupant des lignes similaires (dans ce cas, des jeux de sociétés). Nous allons utiliser un type particulier de clustering appelé clustering k-means. Scikit-learn a une excellente implémentation du clustering k-means que nous pouvons utiliser. Scikit-learn est la principale bibliothèque de Machine Learning en Python. Elle contient les implémentations des algorithmes les plus courants, notamment random forests, les support vector machines et la régression logistique. Scikit-learn a une API bien robuste pour appliquer à ces algorithmes.
# Importer le modèle kmeans clustering. from sklearn.cluster import KMeans # Initialiser le modèle avec 2 paramètres -- nombre de clusters et random state. kmeans_model = KMeans(n_clusters=5, random_state=1) # Seulement les colonnes numériques de games. good_columns = games._get_numeric_data() # Adapter le modèle en utilisant les bonnes colonnes. kmeans_model.fit(good_columns) # Obtenir les labels des clusters. labels = kmeans_model.labels_
Pour utiliser l’algorithme de clustering dans Scikit-learn, nous allons d’abord l’initialiser à l’aide de deux paramètres: n_clusters définit le nombre de clusters de jeux que nous voulons, et random_state est un seed aléatoire que nous avons définie afin de reproduire les mêmes résultats ultérieurement. Voici plus d’informations sur l’implémentation ici. Nous obtenons alors uniquement les colonnes numériques de notre DataFrame. La plupart des algorithmes de Machine Learning ne peuvent pas opérer directement sur des données texte et ne peuvent prendre que des nombres en entrée. Obtenir uniquement les colonnes numériques supprime le type et le nom, qui ne sont pas utilisables par l’algorithme de classification. Enfin, nous ajustons notre modèle kmeans à nos données et obtenons les étiquettes ou labels d’attribution du cluster pour chaque ligne.
Tracer les Clusters
Maintenant que nous avons les labels des clusters, nous pouvons tracer ces clusters. Un point de bloquant c’est que nos données comportent de nombreuses colonnes – il est impensable de pouvoir visualiser les choses dans plus de 3 dimensions. Nous devrons donc réduire la dimensionnalité de nos données sans perdre trop d’informations. Une façon de faire est une technique appelée l’analyse en composantes principales (Principle Components Analysis ou PCA). PCA prend plusieurs colonnes et les transforme en moins de colonnes tout en essayant de conserver les informations uniques dans chaque colonne. Pour simplifier, supposons que nous ayons deux colonnes, total_owners et total_traders. Il existe une corrélation entre ces deux colonnes et des informations qui se chevauchent. La PCA compressera ces informations dans une colonne avec de nouveaux numéros tout en essayant de ne perdre aucune information. Nous allons essayer de transformer nos données de jeux de société en deux dimensions, ou colonnes, afin de pouvoir facilement les tracer.
# Importer le modèle PCA. from sklearn.decomposition import PCA # Créer un modèle PCA. pca_2 = PCA(2) # adapter le modèle PCA aux colonnes numériques précédentes. plot_columns = pca_2.fit_transform(good_columns) # Faire un graphique à nuage de points pour chaque type de jeux de société, à partir des clusters. plt.scatter(x=plot_columns[:,0], y=plot_columns[:,1], c=labels) # Afficher le graphique. plt.show()
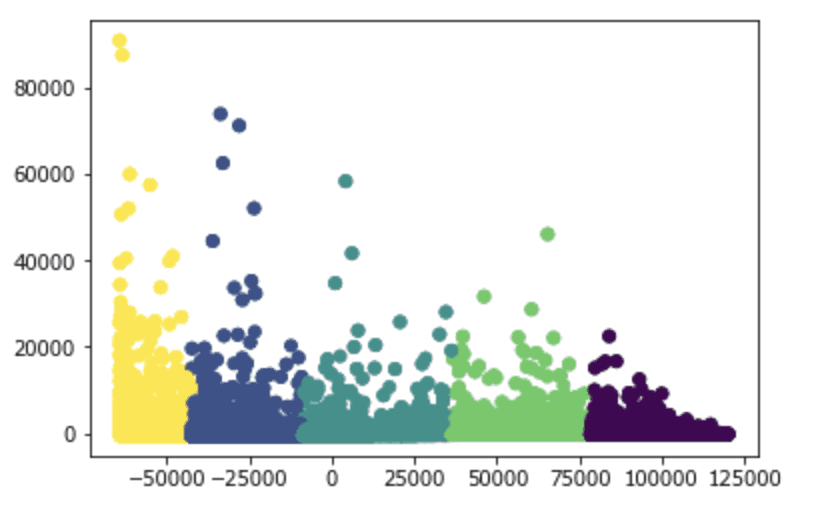
Nous commençons par initialiser un modèle PCA à partir de Scikit-learn. La PCA n’est pas une technique de Machine Learning, mais Scikit-learn contient également d’autres modèles utiles pour le Machine Learning. Les techniques de réduction de dimensionnalité telles que la PCA sont largement utilisées lors du pré-traitement de données pour des algorithmes de Machine Learning. Nous transformons ensuite nos données en 2 colonnes et en traçons les colonnes. Lorsque nous traçons les colonnes, nous les distinguons en fonction de leur affectation à leurs clusters respectifs. Le graphique nous montre qu’il y a 5 clusters distincts. Nous pourrions explorer davantage les jeux de chaque groupe pour en savoir plus sur les facteurs à l’origine du regroupement des jeux.
Déterminer quoi prédire
Nous devons déterminer deux choses avant de nous lancer dans le Machine Learning: comment mesurer l’erreur et ce que nous allons prédire. Nous avons pensé plus tôt que average_rating pourrait être un bon élément de prédiction et notre exploration renforce cette hypothèse. Il existe une variété de moyens pour mesurer l’erreur (beaucoup sont énumérés ici). En règle générale, lorsque nous procédons à une régression et à la prédiction de variables continues, nous avons besoin d’une mesure d’erreur différente de celle utilisée lors de la classification et de la prédiction de valeurs discrètes. Pour cela, nous utiliserons l’erreur quadratique moyenne: elle est facile à calculer et simple à comprendre. Cela nous montre à quel point, en moyenne, nos prédictions sont proches (ou non) de nos valeurs réelles.
Trouver des corrélations
Maintenant que nous voulons prédire average_rating, voyons quelles colonnes pourraient être intéressantes pour notre prédiction. Une solution consiste à rechercher la corrélation entre average_rating et chacune des autres colonnes. Cela nous indiquera quelles autres colonnes pourraient prédire average_rating le mieux. Nous pouvons utiliser la méthode corr sur des DataFrames Pandas pour trouver facilement des corrélations. Cela nous donnera la corrélation entre chaque colonne et chaque autre colonne. Le résultat étant un DataFrame, nous pouvons l’indexer et obtenir uniquement les corrélations de la colonne average_rating.
games.corr()["average_rating"]
id 0.304201 yearpublished 0.108461 minplayers -0.032701 maxplayers -0.008335 playingtime 0.048994 minplaytime 0.043985 maxplaytime 0.048994 minage 0.210049 users_rated 0.112564 average_rating 1.000000 bayes_average_rating 0.231563 total_owners 0.137478 total_traders 0.119452 total_wanters 0.196566 total_wishers 0.171375 total_comments 0.123714 total_weights 0.109691 average_weight 0.351081 Name: average_rating, dtype: float64
Nous voyons que les colonnes average_weight et id sont les plus corrélées à la notation. Les identifiants de la colonne id sont vraisemblablement attribués lorsque le jeu de société est ajouté à la base de données, ce qui indique probablement que les jeux fabriqués ultérieurement ont des scores plus élevés. Peut-être que les critiques n’étaient pas aussi agréables aux débuts de BoardGameGeek, ou que les jeux plus anciens étaient de moins bonne qualité. average_weight indique la «profondeur» ou la complexité d’un jeu. Il est donc possible que les jeux plus complexes soient mieux notés.
Choisir les prédicteurs parmi les colonnes
Avant de commencer à faire des prédictions, sélectionnons uniquement les colonnes pertinentes pour l’entrainement de notre algorithme. Nous voudrons supprimer certaines colonnes qui ne sont pas numériques. Nous voudrons également supprimer les colonnes qui ne peuvent être calculées que si vous connaissez déjà la note moyenne. Laisser ces colonnes détruirait l’objectif du classificateur qui consiste à prédire le classement sans aucune connaissance préalable. L’utilisation de colonnes qui ne peuvent être calculées qu’avec la connaissance de la cible peut conduire à l’overfitting (ou sur-entrainement), où votre modèle est bon dans un ensemble d’entraînement, mais ne se généralise pas bien aux données futures. La colonne bayes_average_rating semble dériver d’une certaine manière de average_rating, donc supprimons-la.
# Obtenir toutes les colonnes du DataFrame games. columns = games.columns.tolist() # Filtrer les colonnes pour supprimer celles que nous ne voulons pas. columns = [c for c in columns if c not in ["bayes_average_rating", "average_rating", "type", "name"]] # Stocker la variable que nous voulons prédire. target = "average_rating"
Séparer le dataset en 2 sets: un set de Train et un set de Test
Nous voulons pouvoir déterminer avec quelle précision un algorithme utilise nos métriques d’erreur. Cependant, l’évaluation de l’algorithme sur les mêmes données que celles sur lesquelles il a été entrainé provoquera un sur-entrainement (overfitting). Nous voulons que l’algorithme apprenne à faire des prédictions à partir de règles généralisées, et non de mémoriser comment faire des prédictions spécifiques. Un exemple est l’apprentissage des mathématiques. Si vous mémorisez ça 1 + 1 = 2 et 2 + 2 = 4, vous pourrez répondre parfaitement à toutes les questions concernant 1 + 1 et 2 + 2. Vous aurez 0 erreur. Cependant, la deuxième personne vous demande quelque chose en dehors de votre ensemble d’entraînement (dans lequel vous connaissez la réponse), comme 3 + 3, vous ne pourrez pas la résoudre. D’autre part, si vous êtes capable de généraliser et d’apprendre plus, vous ferez des erreurs occasionnelles parce que vous n’avez pas mémorisé les solutions – vous résoudrez peut-être incorrectement 3453 + 353535, mais vous pourrez au moins résoudre tout problème supplémentaire qu’on vous proposera. Si votre erreur semble étonnamment basse lorsque vous vous entraînez à un algorithme de Machine Learning, vous devez toujours vérifier si vous ne sur-entrainé pas. Pour éviter l’overfitting, nous allons entrainer notre algorithme sur un ensemble composé de 80% des données et le tester sur un autre ensemble composé de 20% des données (le reste). Pour ce faire, nous échantillonnons d’abord au hasard 80% des lignes dans le set d’entraînement, puis mettons tout le reste dans le set de test.
# Importer une fonction prévue pour séparer les sets. from sklearn.model_selection import train_test_split # Générer le set de training. Fixer random_state pour répliquer lé resultats ultérieurement. train = games.sample(frac=0.8, random_state=1) # Sélectionner tout ce qui n'est pas dans le set de training et le mettre dans le set de test. test = games.loc[~games.index.isin(train.index)] # Afficher les dimensions des 2 sets. print(train.shape) print(test.shape)
(45515, 20) (11379, 20)
Ci-dessus, nous exploitons le fait que chaque ligne d’un DataFrame Pandas possède un index unique pour sélectionner une ligne ne faisant pas partie du set d’entraînement et figurant dans le set de test.
Adapter un modèle de régression linéaire
La régression linéaire est un algorithme de Machine Learning puissant et couramment utilisé. Il prédit la variable cible en utilisant des combinaisons linéaires des variables prédictrices. Disons que nous avons 2 valeurs, 3 et 4. Une combinaison linéaire serait de 3 * 0.5 + 4 * 0.5. Une combinaison linéaire consiste à multiplier chaque nombre par une constante et à additionner les résultats. La régression linéaire ne fonctionne bien que lorsque les variables de prédictrices et la variable cible sont corrélées linéairement. Comme nous l’avons vu précédemment, quelques-uns des prédicteurs sont corrélés à la cible. La régression linéaire devrait donc nous convenir. Nous pouvons utiliser l’implémentation de régression linéaire dans Scikit-learn, tout comme nous avons utilisé l’implémentation de k-means plus tôt.
# Importer le modèle LinearRegression. from sklearn.linear_model import LinearRegression # Initialiser la classe du modèle. model = LinearRegression() # Adapter le modèle aux données d'entrainement model.fit(train[columns], train[target])
Lorsque nous entrainons le modèle, nous passons en paramètre la matrice des prédicteurs, qui comprend toutes les colonnes du DataFrame que nous avons précédemment sélectionnées. Si vous passez une liste à un DataFrame Pandas lors de son indexation, un nouveau DataFrame sera générée avec toutes les colonnes de la liste. Nous transmettons également la variable cible, pour laquelle nous souhaitons faire des prédictions. Le modèle apprend à partir de l’équation qui fait correspondre les prédicteurs à la cible avec une erreur minimale.
Erreur des prédictions
Après avoir entrainé le modèle, nous pouvons faire des prédictions sur de nouvelles données. Ces nouvelles données doivent être exactement au même format que les données d’apprentissage, sinon le modèle ne produira pas de prédictions précises. Notre set de test est identique au set de formation (sauf que les lignes contiennent des jeux de société différents). Nous sélectionnons le même sous-ensemble de colonnes dans l’ensemble de tests, puis nous effectuons des prédictions dessus.
# Importer la fonction de calcul d'erreur depuis scikit-learn. from sklearn.metrics import mean_squared_error # Générer des prédictions pour le set de test. predictions = model.predict(test[columns]) # Calculer l'erreur entre nos prédictions et les valeurs réelles que nous connaissons. mean_squared_error(predictions, test[target])
1.8239281903519875
Une fois que nous avons les prédictions, nous sommes en mesure de calculer l’erreur entre les prédictions de l’ensemble de test et les valeurs réelles. L’erreur quadratique moyenne dont la formule est :
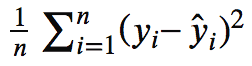
En fait, nous soustrayons chaque valeur prédite de la valeur réelle, nous élevons les différences au carré puis nous les additionnons. Ensuite, nous divisons le résultat par le nombre total de valeurs prédites. Cela nous donnera l’erreur moyenne pour chaque prédiction.
Ici on obtient une erreur d’environ 1.82. On pourrait essayer d’améliorer cette erreur en cherchant à la diminuer.
Essayer un modèle différent
L’un des avantages de Scikit-learn est qu’il nous permet d’essayer très facilement des algorithmes plus puissants. Par exemple l’algorithme random forest. L’algorithme random forest peut trouver des non-linéarités dans les données qu’une régression linéaire ne pourrait pas déceler. Supposons, par exemple, que si la colonne minage d’un jeu est inférieur à 5, la note est basse, si elle est dans 5-10, elle est élevée et si elle est dans 10-15, elle est basse. Un algorithme de régression linéaire ne pourrait pas prendre cela en compte, car il n’existe pas de relation linéaire entre le prédicteur et la cible. Les prédictions faites avec random forest comportent généralement moins d’erreurs que celles faites par régression linéaire.
# Importer le modèle random forest. from sklearn.ensemble import RandomForestRegressor # Initialiser le modèle avec certains paramètres. model = RandomForestRegressor(n_estimators=100, min_samples_leaf=10, random_state=1) # Adapter le modèle aux données. model.fit(train[columns], train[target]) # Faire des prédictions. predictions = model.predict(test[columns]) # Calculer l'erreur. mean_squared_error(predictions, test[target])
1.4144905030983794
On obtient comme vous le constatez une erreur d’environ 1.41 donc inférieur au modèle précédent. On vient donc de trouver un meilleur modèle pour prédire la note moyenne d’un jeu de société.
Exploration plus poussée
Nous sommes parvenus à passer des données au format csv à des prédictions, fou, non? Voici quelques idées pour une exploration plus poussée, vous pouvez essayer:
- le support vector machine.
- d’assembler plusieurs modèles pour créer de meilleures prédictions.
- de prédire une colonne différente, telle que average_weight.
- de générer des caractéristiques à partir du texte, telles que la longueur du nom du jeu, le nombre de mots, etc.
Voulez-vous en savoir plus sur le Machine Learning avec Python?
MonCoachData propose des formations sur le Machine Learning et la Data Science, à partir de données réelles et en élaborant des projets concrets.











Super article, en suivant pas à pas les étapes, il est facile de comprendre les différents points.