

Pour exceller en Analyse de Données / Data Science / Machine Learning avec Python, Pandas est une bibliothèque que VOUS devez maîtriser. Voici une antisèche ou un glossaire de certaines des syntaxes les plus utilisées que vous devez connaître sur le bout des doigts ! Vous pouvez sélectionner, à partir de la table des matières ci-dessous, la partie qui vous intéresse de ce mémo Pandas pour le traitement de données.
Aujourd’hui, le paquet Pandas est l’outil le plus fondamental (et de loin) dans le domaine de la Data Science et de l’analyse de données en Python. Les puissants outils de Machine Learning et de visualisation de données très glamours ont peut-être attiré votre attention ou aiguisé votre curiosité, mais vous n’irez pas loin si vous n’avez pas de bonnes compétences sur la bibliothèque Pandas.
C’est pourquoi, j’ai rassemblé pour vous certaines des fonctions de base de Pandas les plus utilisées. Je commencerai par la création du fameux DataFrame (ou table de données), puis je poursuivrai avec le reshaping des données, puis la recherche de chaînes de caractères, le tri des valeurs, etc.
C’est parti !
Création d’un DataFrame
Je pense qu’il est utile de mentionner la structure de base du DataFrame de Pandas. Lorsqu’il s’agit de données, dans la plupart des cas, vous aurez des variables et les valeurs observées de vos variables. Dans Pandas, chaque variable est stockée sous forme de colonne, tandis que toutes les observations liées à cette variable sont stockées sous forme de lignes. Par exemple, si vous avez 20 observations pour une variable A, dans Pandas elle sera présentée comme une “Colonne A” avec 20 lignes de données.
Création d’un DataFrame vide
import pandas as pd # 4 îles des Canaries col = ['Lanzarote','Fuerteventura', 'La Gomera', 'El Hierro'] df = pd.DataFrame(columns=col) df
Retourne une liste vide :
Lanzarote Fuerteventura La Gomera El Hierro
Création d’un DataFrame à partir d’une liste
col = ['Lanzarote','Fuerteventura', 'La Gomera', 'El Hierro'] ind = [2000,2010,2020] data = [['98731','34444','99384','654'],['34323','44243','88543','3451'],['2222','4324','3432','19344']] df = pd.DataFrame(data, columns=col, index=ind) df
Retourne :

Création d’un DataFrame à partir d’un dictionnaire
data = {'A':[98731,34444,99384],'B':[34323,44243,88543],'C':[2222,4324,None]}
df = pd.DataFrame(data)
df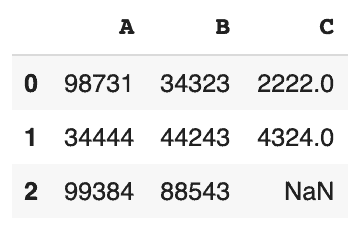
On utilise “None” pour représenter une valeur vide dans Pandas.
Renommer une colonne
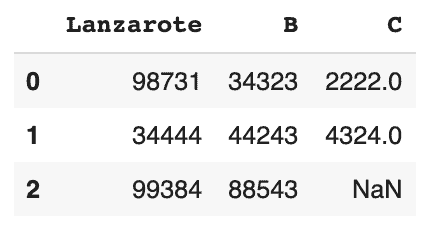
df = df.rename(columns={'A':'Lanzarote'})
dfRetourne :
Insertion
Insertion de colonne
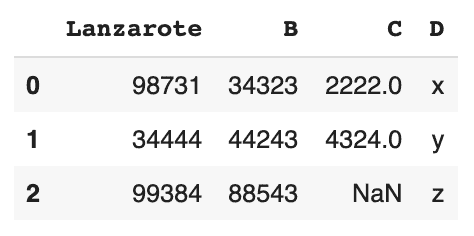
# insertion de la colonne D d = ['x','y','z'] df['D'] = d df
Retourne :
Insertion de ligne
# Insertion de la 4ème ligne
new_row = {'Lanzarote':98989, 'B':77889, 'C':None, 'D' :'z'}
df = df.append(new_row, ignore_index=True)
df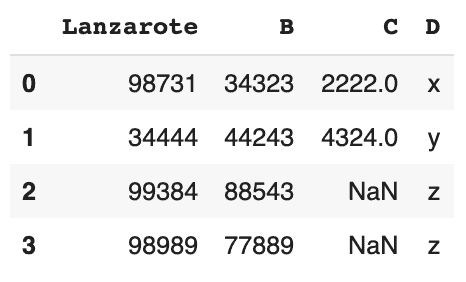
Suppression
Retirer une colonne
Pour retirer plusieurs colonnes, vous pouvez utiliser une liste. Par exemple df.drop(["C", "B"],axis=1).
Pour effectuer un changement permanent, vous pouvez ré-écrire par dessus la variable df = df.drop(...)
# Suppression de la colonne C uniquement
df.drop('C',axis=1)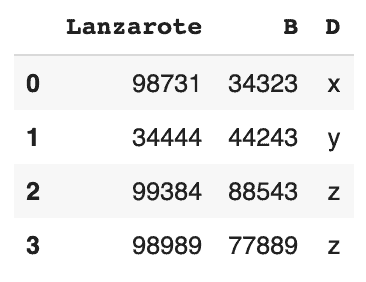
Retirer une ligne
# Suppression d'une ligne avec l'index "0" df.drop(0)
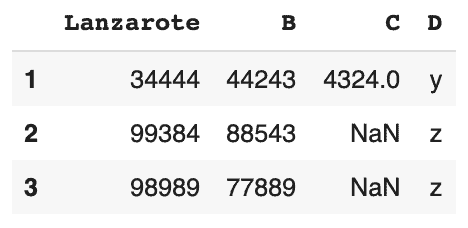
Éliminer les doublons
df.drop_duplicates()
Notre DataFrame df reste le même, car nous n’avons pas de doublon ici.
Traitement des valeurs manquantes
Le plus souvent, nous avons des valeurs nulles (ou vides) dans nos données. En général, nous allons soit supprimer ces valeurs manquantes, soit les remplacer par d’autres valeurs significatives, par exemple la moyenne de la colonne.
Vérifier les valeurs nulles
pd.isnull(df)
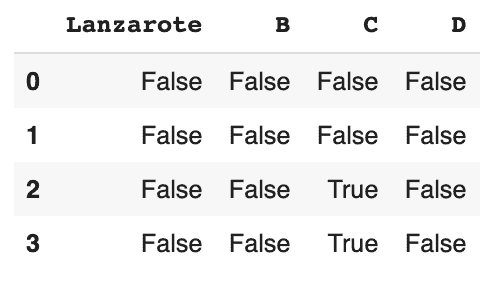
On peut voir qu’il y a 2 valeurs nulles dans la colonne C.
Localiser les valeurs nulles horizontalement
# vérifier horizontalement, de la première colonne à la dernière pd.isnull(df).any(axis=0)

Localiser les valeurs nulles verticalement
# vérifier verticalement, de l'indice 1 à 4 pd.isnull(df).any(axis=1)

Remplir tous les NaN avec des valeurs significatives
df2 = df.copy() df3 = df2.fillna(0) # remplir avec 0 df4 = df2.fillna(df.mean()) # remplir avec la moyenne de la colonne df5 = df2.fillna(df.B.max()) # remplir avec le max de la colonne B
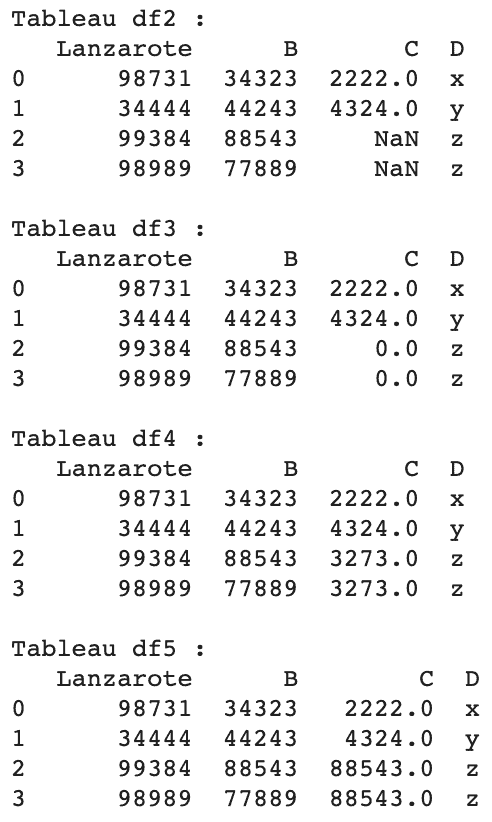
Dans ce cas, il semble que le plus raisonnable soit de remplir les valeurs NaN de la colonne C avec la moyenne de sa propre colonne.
Reshaping
La forme (ou dimension) des données est un autre problème courant auquel un data scientist doit faire face. Comme chaque modèle de Machine Learning a des exigences différentes en matière de forme/dimension des données, nous devons re-modeler les données en fonction des exigences du modèle. Par exemple, mon modèle LSTM préféré prend en compte les données tridimensionnelles, nous devons donc transformer la plupart des données bi-dimensionnelles en données tri-dimensionnelles.
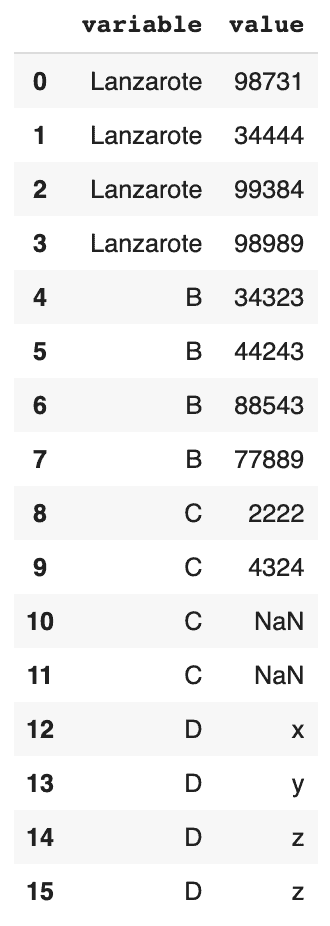
Rassembler toutes les colonnes en une seule
# rassembler toutes les colonnes, et toutes les observations en une seule colonne pd.melt(df2)
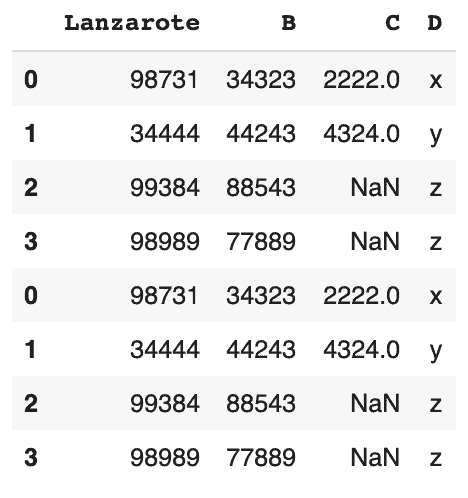
Concat – empilage
Cette fonction est similaire à UNION ALL de la syntaxe SQL. Elle empile les valeurs ayant le même nom de colonne.
# joindre verticalement pd.concat([df,df])
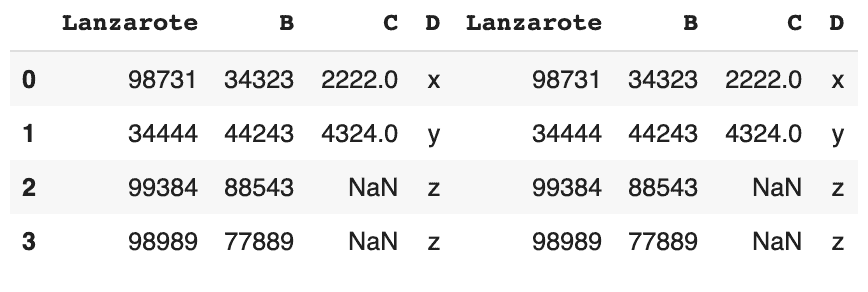
Concat – côte à côte
# joindre horizontalement pd.concat([df,df], axis=1)
Groupby
Il s’agit d’une technique terriblement populaire qui apparaît dans de nombreux langages informatiques. Dans l’exemple ci-dessous, nous regroupons les données par les lettres dans la colonne D, et ne montrons que les valeurs de la somme de chacune d’entre elles dans la colonne B.
# SELECT B, SUM(B) FROM df GROUP BY D ORDER BY B
df.groupby('D')['B'].sum()
Observation basique des données
Après le brassage et la transformation des données, il est temps de vérifier ce que nous avons fait.
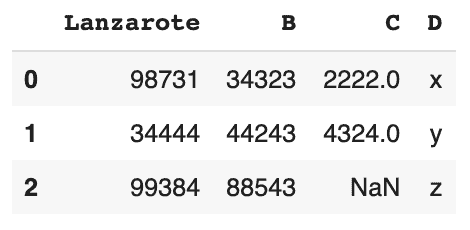
Imprimer les premières lignes
# la valeur par défaut est 5 si vous laissez la parenthèse vide. # nous affichons les 3 premières lignes seulement df.head(3)
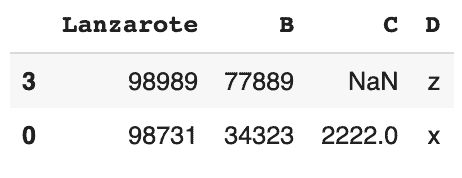
Imprimer les dernières lignes
# la valeur par défaut est 5 si vous laissez la prenthèse vide. # nous montrons les 2 dernières lignes seulement df.tail(2)
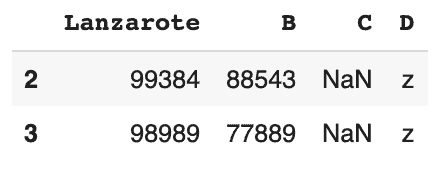
Imprimer aléatoirement quelques lignes
# échantillonnage aléatoire de seulement 50% de l'ensemble des données df.sample(frac=0.5)
Imprimer un résumé concis d’un DataFrame
df.info()

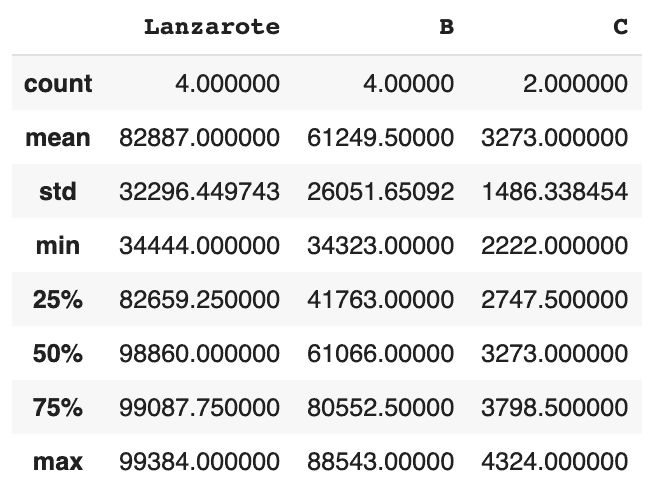
Générer des statistiques descriptives
Il s’agit d’une méthode simple et pratique pour repérer visuellement les variables qui ont des valeurs aberrantes (outliers).
# décrit uniquement les colonnes numériques. La colonne D est une colonne de chaînes de caractères, donc rien n'est montré. df.describe()
Requête / Récupération de données
Après avoir obtenu la forme/shape de dataframe dont nous avons besoin, nous voulons récupérer les informations de ces données. La fonction query est l’une des fonctions les plus utilisées dans Pandas pour l’extraction de données.
Triage
Pandas partage également certaines caractéristiques de SQL. Dans le tri, la valeur par défaut est ascendante, ce qui est similaire à ce que l’on trouve dans ORDER IN de SQL.
# trier les valeurs en fonction de Lanzarote
# par défaut, c'est ascendant
df.sort_values('Lanzarote', ascending=False)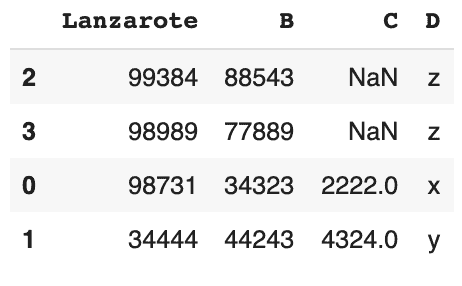
Réinitialisation de l’index
Très souvent, après un tri, nous devons réinitialiser l’index aux indices de ligne.
Voici la syntaxe pour cela :
df.reset_index()
Condition unique
# renvoie un DataFrame avec une condition : B doit être supérieur ou égal à 50000
df.query('B >= 50000')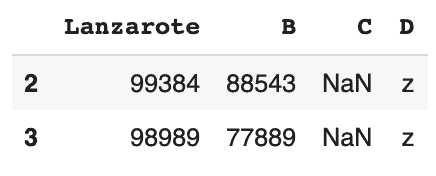
La syntaxe ci-dessous donne le même résultat, mais la récupération est différente.
df[df['B']>=50000]
Au lieu d’imprimer la totalité du DataFrame, l’opération suivante permet de récupérer la colonne C uniquement.
df.C[df['B']>=50000]

Seules 2 lignes de la colonne C sont imprimées.
Conditions multiples – “ET”
# renvoie un DataFrame avec 2 conditions : B doit être supérieur ou égal à 50000, et 'Lanzarote' doit être inférieur à 99000 df[(df['B']>=50000) & (df['Lanzarote'] < 99000)] # pas de "AND"

Conditions multiples – “OU”
# renvoie un DataFrame avec 2 conditions : B doit être supérieur ou égal à 50000, ou 'Lanzarote' doit être inférieur à 49000 df[(df['B']>=50000) | (df['Lanzarote'] < 49000)] # pas de "OR"
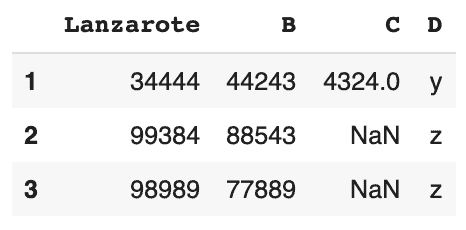
Correspondances de chaînes
Pour trouver une occurrence de chaîne dans un ensemble de données, nous pouvons utiliser str.find() ou str.contains(). La méthode str.find() renvoie une valeur entière. Si la sous-chaîne existe dans la chaîne, elle renvoie l’index de la première occurrence de la sous-chaîne. Si la sous-chaîne n’existe pas dans la chaîne, elle renvoie -1.
Pour le str.contains, il renvoie les valeurs booléennes True ou False.
# Dans la colonne D, vérifiez si "z" existe
print(df['D'].str.find('z'))
print(df['D'].str.contains('z',case=False))
Sélectionner les données avec loc et iloc
# retourner la liste entière # avec une déclaration conditionnelle print(df.loc[df['D'] == 'z']) # retourne le premier élément print(df.loc[0]) # sélectionne une valeur spécifique étiquette de ligne et étiquette de colonne print(df.loc[0, 'D']) # sélectionne une valeur spécifique index de ligne et index de colonne print(df.iloc[0,3])

Requête avec regex
De nombreuses fonctions natives de Pandas prennent en charge les regex, à savoir count(), replace(), contains(), extract(), findall(), match(), split() et rsplit().
# recherche des lignes avec une seule lettre dans la colonne D. df[df['D'].str.contains(r'[a-z]+')] # \D
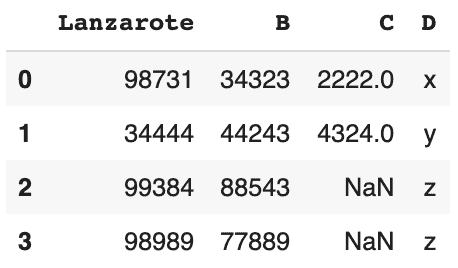
Il renvoie le DataFrame entier car toutes les variables de la colonne D sont des lettres.
Le plus grand et le plus petit
# retourne les 2 lignes avec les plus grand nombres dans la colonne B df.nlargest(2, 'B')
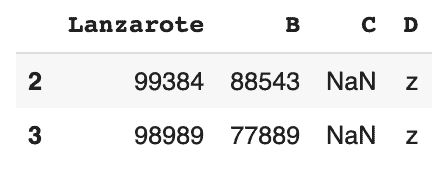
# retourne les 2 lignes avec le plus petit nombre dans la colonne B df.nsmallest(2, 'C')
Bonus : Traiter de grands volumes de données (Big Data)
Microsoft Excel ne peut traiter que 1000 lignes de données sans problème. Cependant, si le jeu de données dépasse 10k lignes, il se bloque souvent. Pandas de Python gère 1 million de lignes sans aucun problème (du moins, d’après mon expérience, avec un MacBook Pro 16GO de RAM).
Qu’en est-il du big data ? Qu’en est-il des données d’une taille supérieure à 1 Go ? ou de fichiers de données si énormes que vous ne pouvez pas du tout le charger en mémoire ?
Bien sûr, vous pouvez utiliser Dask, ou Vaex, mais nous allons rester avec Pandas ici.
Pour les données volumineuses dans Pandas, nous utiliserons le chunksize pour ne charger qu’une partie du fichier en mémoire à un moment donné.
df = pd.read_csv(’data.csv’, chunksize=10000)
Pandas pour le traitement de données – CODE
Voilà ! Maintenant que nous venons de réviser rapidement les opérations de base de Pandas, j’espère que cet aide-mémoire vous donnera plus d’assurance lorsque vous traiterez des DataFrames Pandas. Vous pouvez voir cette syntaxe en application de quelques analyses de données disponibles sur ce site, par exemple, l’analyse de données sur le Covid-19.
Pour faciliter la révision, j’ai mis tout ce qui est mentionné ci-dessus dans un notebook Google Colab. N’hésitez pas à l’exécuter et à le télécharger : Cheat Sheet Pandas pour le Traitement de Données.











Un grand merci bon travail
Ravi que ça t’ait plu :))
Magnifique, merci !